 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Linearized Alternating Direction Multiplier Method for Federated Matrix Completion Problems
Mar 17, 2025Matrix completion is fundamental for predicting missing data with a wide range of applications in personalized healthcare, e-commerce, recommendation systems, and social network analysis. Traditional matrix completion approaches typically assume centralized data storage, which raises challenges in terms of computational efficiency, scalability, and user privacy. In this paper, we address the problem of federated matrix completion, focusing on scenarios where user-specific data is distributed across multiple clients, and privacy constraints are uncompromising. Federated learning provides a promising framework to address these challenges by enabling collaborative learning across distributed datasets without sharing raw data. We propose \texttt{FedMC-ADMM} for solving federated matrix completion problems, a novel algorithmic framework that combines the Alternating Direction Method of Multipliers with a randomized block-coordinate strategy and alternating proximal gradient steps. Unlike existing federated approaches, \texttt{FedMC-ADMM} effectively handles multi-block nonconvex and nonsmooth optimization problems, allowing efficient computation while preserving user privacy. We analyze the theoretical properties of our algorithm, demonstrating subsequential convergence and establishing a convergence rate of $\mathcal{O}(K^{-1/2})$, leading to a communication complexity of $\mathcal{O}(\epsilon^{-2})$ for reaching an $\epsilon$-stationary point. This work is the first to establish these theoretical guarantees for federated matrix completion in the presence of multi-block variables. To validate our approach, we conduct extensive experiments on real-world datasets, including MovieLens 1M, 10M, and Netflix. The results demonstrate that \texttt{FedMC-ADMM} outperforms existing methods in terms of convergence speed and testing accuracy.
Productivity Assessment of Neural Code Completion
May 13, 2022



Neural code synthesis has reached a point where snippet generation is accurate enough to be considered for integration into human software development workflows. Commercial products aim to increase programmers' productivity, without being able to measure it directly. In this case study, we asked users of GitHub Copilot about its impact on their productivity, and sought to find a reflection of their perception in directly measurable user data. We find that the rate with which shown suggestions are accepted, rather than more specific metrics regarding the persistence of completions in the code over time, drives developers' perception of productivity.
Adaptive Forgetting Curves for Spaced Repetition Language Learning
Apr 23, 2020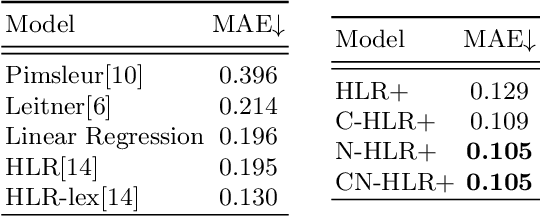

The forgetting curve has been extensively explored by psychologists, educationalists and cognitive scientists alike. In the context of Intelligent Tutoring Systems, modelling the forgetting curve for each user and knowledge component (e.g. vocabulary word) should enable us to develop optimal revision strategies that counteract memory decay and ensure long-term retention. In this study we explore a variety of forgetting curve models incorporating psychological and linguistic features, and we use these models to predict the probability of word recall by learners of English as a second language. We evaluate the impact of the models and their features using data from an online vocabulary teaching platform and find that word complexity is a highly informative feature which may be successfully learned by a neural network model.
Approximating Activation Functions
Jan 17, 2020
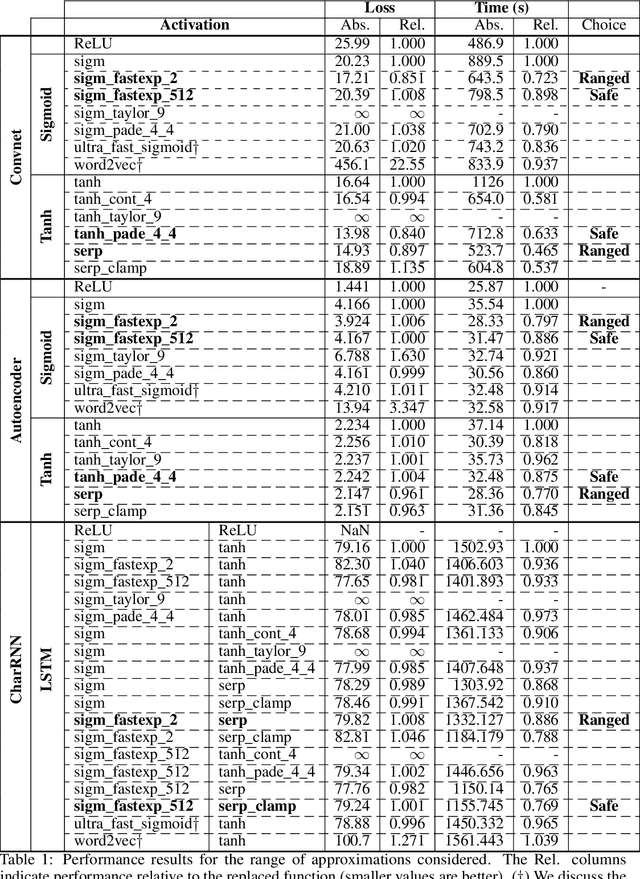
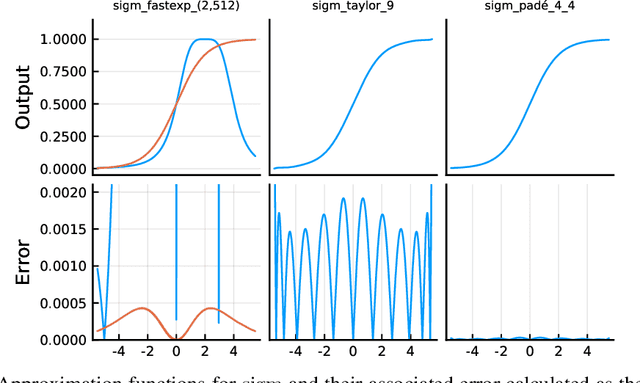
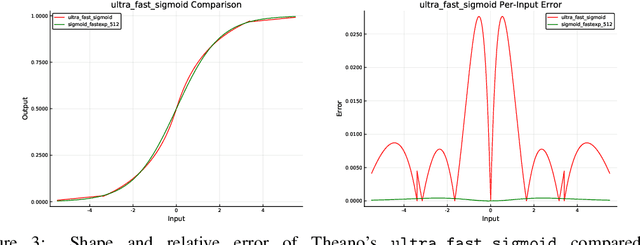
ReLU is widely seen as the default choice for activation functions in neural networks. However, there are cases where more complicated functions are required. In particular, recurrent neural networks (such as LSTMs) make extensive use of both hyperbolic tangent and sigmoid functions. These functions are expensive to compute. We used function approximation techniques to develop replacements for these functions and evaluated them empirically on three popular network configurations. We find safe approximations that yield a 10% to 37% improvement in training times on the CPU. These approximations were suitable for all cases we considered and we believe are appropriate replacements for all networks using these activation functions. We also develop ranged approximations which only apply in some cases due to restrictions on their input domain. Our ranged approximations yield a performance improvement of 20% to 53% in network training time. Our functions also match or considerably out perform the ad-hoc approximations used in Theano and the implementation of Word2Vec.
Learning to Fix Build Errors with Graph2Diff Neural Networks
Nov 04, 2019

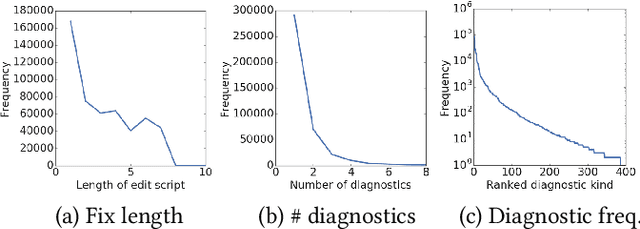

Professional software developers spend a significant amount of time fixing builds, but this has received little attention as a problem in automatic program repair. We present a new deep learning architecture, called Graph2Diff, for automatically localizing and fixing build errors. We represent source code, build configuration files, and compiler diagnostic messages as a graph, and then use a Graph Neural Network model to predict a diff. A diff specifies how to modify the code's abstract syntax tree, represented in the neural network as a sequence of tokens and of pointers to code locations. Our network is an instance of a more general abstraction that we call Graph2Tocopo, which is potentially useful in any development tool for predicting source code changes. We evaluate the model on a dataset of over 500k real build errors and their resolutions from professional developers. Compared to the approach of DeepDelta (Mesbah et al., 2019), our approach tackles the harder task of predicting a more precise diff but still achieves over double the accuracy.