 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBayesian Quantification with Black-Box Estimators
Feb 17, 2023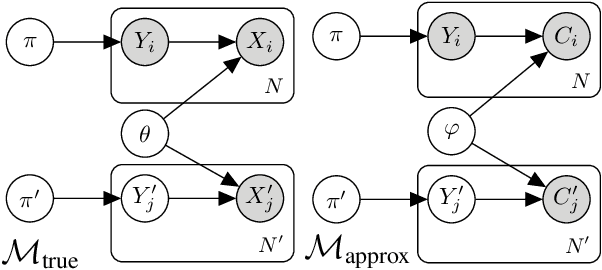
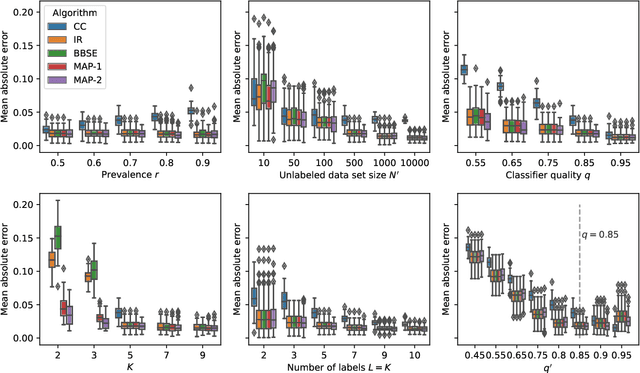
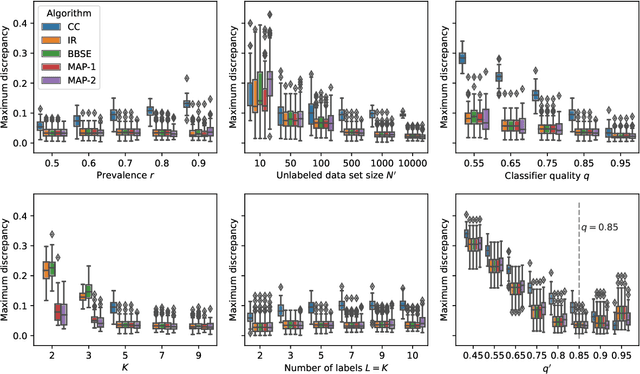
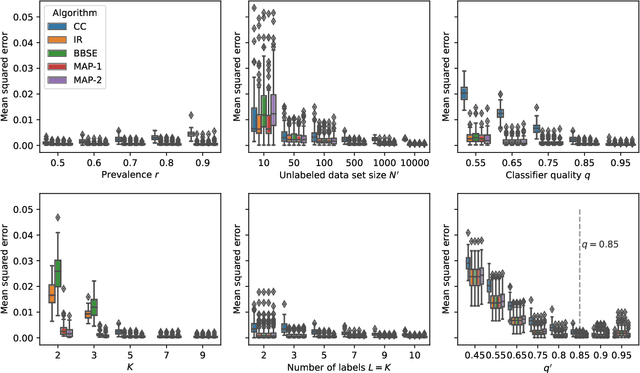
Understanding how different classes are distributed in an unlabeled data set is an important challenge for the calibration of probabilistic classifiers and uncertainty quantification. Approaches like adjusted classify and count, black-box shift estimators, and invariant ratio estimators use an auxiliary (and potentially biased) black-box classifier trained on a different (shifted) data set to estimate the class distribution and yield asymptotic guarantees under weak assumptions. We demonstrate that all these algorithms are closely related to the inference in a particular Bayesian model, approximating the assumed ground-truth generative process. Then, we discuss an efficient Markov Chain Monte Carlo sampling scheme for the introduced model and show an asymptotic consistency guarantee in the large-data limit. We compare the introduced model against the established point estimators in a variety of scenarios, and show it is competitive, and in some cases superior, with the state of the art.
Extracting Meaningful Attention on Source Code: An Empirical Study of Developer and Neural Model Code Exploration
Oct 11, 2022



The high effectiveness of neural models of code, such as OpenAI Codex and AlphaCode, suggests coding capabilities of models that are at least comparable to those of humans. However, previous work has only used these models for their raw completion, ignoring how the model reasoning, in the form of attention weights, can be used for other downstream tasks. Disregarding the attention weights means discarding a considerable portion of what those models compute when queried. To profit more from the knowledge embedded in these large pre-trained models, this work compares multiple approaches to post-process these valuable attention weights for supporting code exploration. Specifically, we compare to which extent the transformed attention signal of CodeGen, a large and publicly available pretrained neural model, agrees with how developers look at and explore code when each answering the same sense-making questions about code. At the core of our experimental evaluation, we collect, manually annotate, and open-source a novel eye-tracking dataset comprising 25 developers answering sense-making questions on code over 92 sessions. We empirically evaluate five attention-agnostic heuristics and ten attention-based post processing approaches of the attention signal against our ground truth of developers exploring code, including the novel concept of follow-up attention which exhibits the highest agreement. Beyond the dataset contribution and the empirical study, we also introduce a novel practical application of the attention signal of pre-trained models with completely analytical solutions, going beyond how neural models' attention mechanisms have traditionally been used.
Productivity Assessment of Neural Code Completion
May 13, 2022



Neural code synthesis has reached a point where snippet generation is accurate enough to be considered for integration into human software development workflows. Commercial products aim to increase programmers' productivity, without being able to measure it directly. In this case study, we asked users of GitHub Copilot about its impact on their productivity, and sought to find a reflection of their perception in directly measurable user data. We find that the rate with which shown suggestions are accepted, rather than more specific metrics regarding the persistence of completions in the code over time, drives developers' perception of productivity.
Unsupervised Recalibration
Sep 12, 2019


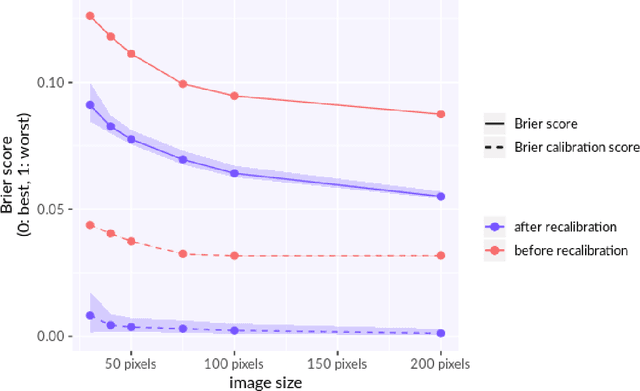
Unsupervised recalibration (URC) is a general way to improve the accuracy of an already trained probabilistic classification or regression model upon encountering new data while deployed in the field. URC does not require any ground truth associated with the new field data. URC merely observes the model's predictions and recognizes when the training set is not representative of field data, and then corrects to remove any introduced bias. URC can be particularly useful when applied separately to different subpopulations observed in the field that were not considered as features when training the machine learning model. This makes it possible to exploit subpopulation information without retraining the model or even having ground truth for some or all subpopulations available. Additionally, if these subpopulations are the object of study, URC serves to determine the correct ground truth distributions for them, where naive aggregation methods, like averaging the model's predictions, systematically underestimate their differences.