 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning to Fix Build Errors with Graph2Diff Neural Networks
Nov 04, 2019

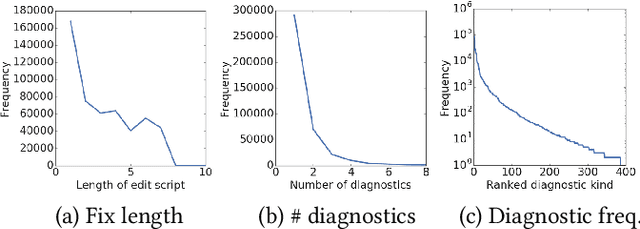

Professional software developers spend a significant amount of time fixing builds, but this has received little attention as a problem in automatic program repair. We present a new deep learning architecture, called Graph2Diff, for automatically localizing and fixing build errors. We represent source code, build configuration files, and compiler diagnostic messages as a graph, and then use a Graph Neural Network model to predict a diff. A diff specifies how to modify the code's abstract syntax tree, represented in the neural network as a sequence of tokens and of pointers to code locations. Our network is an instance of a more general abstraction that we call Graph2Tocopo, which is potentially useful in any development tool for predicting source code changes. We evaluate the model on a dataset of over 500k real build errors and their resolutions from professional developers. Compared to the approach of DeepDelta (Mesbah et al., 2019), our approach tackles the harder task of predicting a more precise diff but still achieves over double the accuracy.
Reducing the variance in online optimization by transporting past gradients
Jun 18, 2019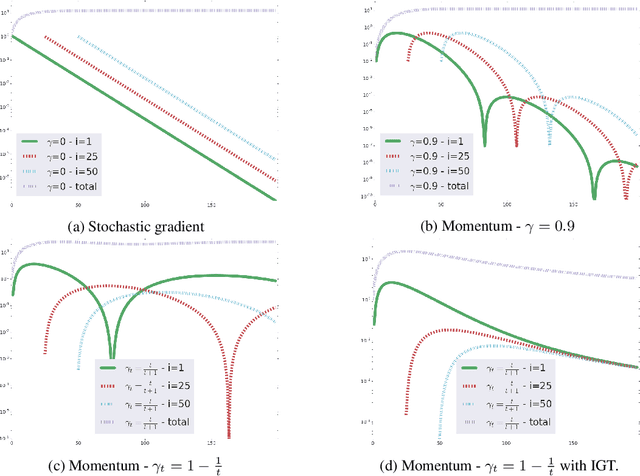
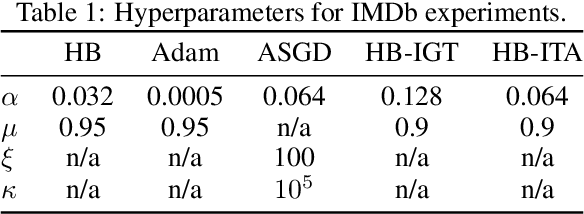
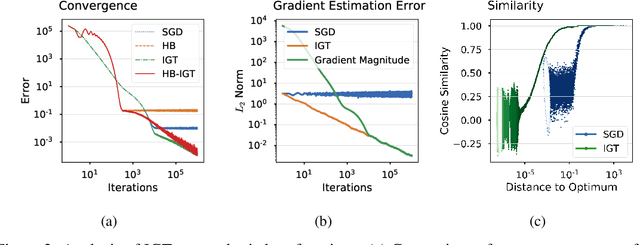
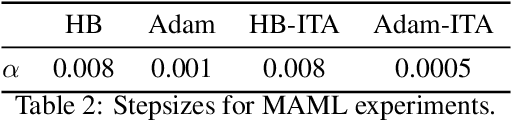
Most stochastic optimization methods use gradients once before discarding them. While variance reduction methods have shown that reusing past gradients can be beneficial when there is a finite number of datapoints, they do not easily extend to the online setting. One issue is the staleness due to using past gradients. We propose to correct this staleness using the idea of implicit gradient transport (IGT) which transforms gradients computed at previous iterates into gradients evaluated at the current iterate without using the Hessian explicitly. In addition to reducing the variance and bias of our updates over time, IGT can be used as a drop-in replacement for the gradient estimate in a number of well-understood methods such as heavy ball or Adam. We show experimentally that it achieves state-of-the-art results on a wide range of architectures and benchmarks. Additionally, the IGT gradient estimator yields the optimal asymptotic convergence rate for online stochastic optimization in the restricted setting where the Hessians of all component functions are equal.
Meta-Dataset: A Dataset of Datasets for Learning to Learn from Few Examples
Mar 07, 2019
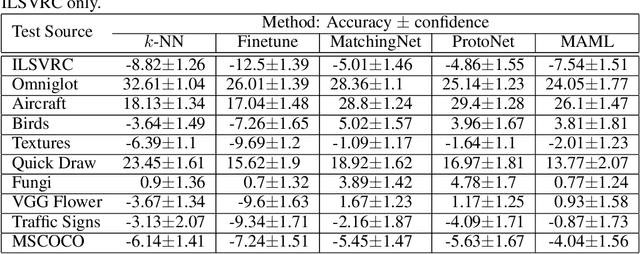
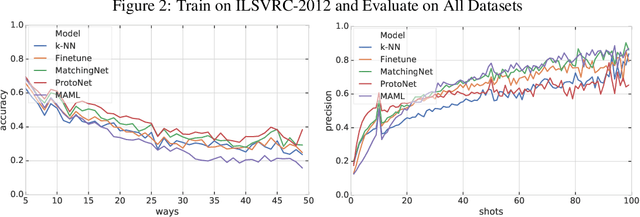
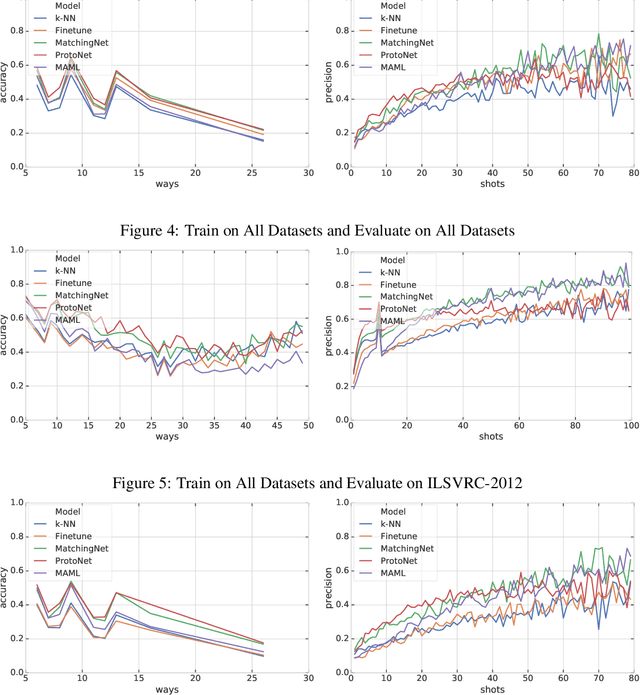
Few-shot classification refers to learning a classifier for new classes given only a few examples. While a plethora of models have emerged to tackle this recently, we find the current procedure and datasets that are used to systematically assess progress in this setting lacking. To address this, we propose Meta-Dataset: a new benchmark for training and evaluating few-shot classifiers that is large-scale, consists of multiple datasets, and presents more natural and realistic tasks. The aim is to measure the ability of state-of-the-art models to leverage diverse sources of data to achieve higher generalization, and to evaluate that generalization ability in a more challenging setting. We additionally measure robustness of current methods to variations in the number of available examples and the number of classes. Finally our extensive empirical evaluation leads us to identify weaknesses in Prototypical Networks and MAML, two popular few-shot classification methods, and to propose a new method, Proto-MAML, which achieves improved performance on our benchmark.
Negative eigenvalues of the Hessian in deep neural networks
Feb 06, 2019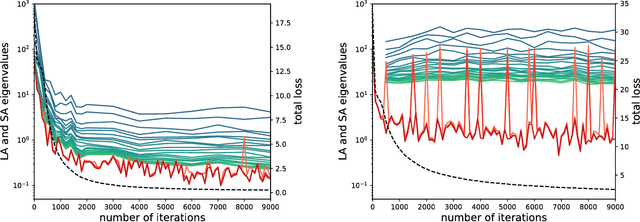
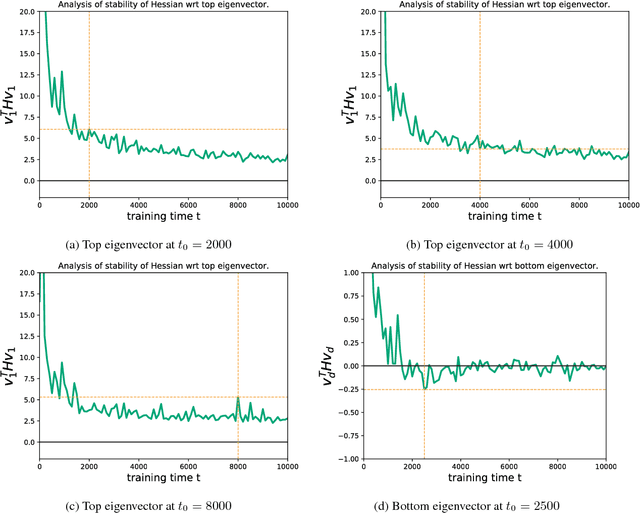
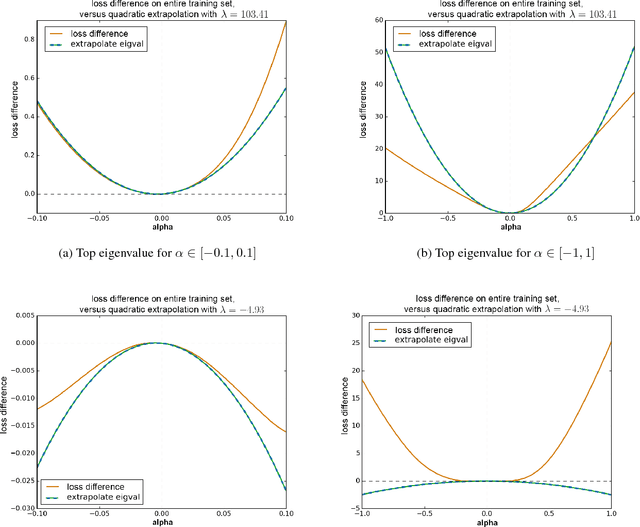
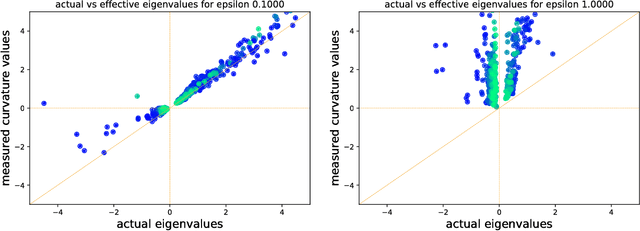
The loss function of deep networks is known to be non-convex but the precise nature of this nonconvexity is still an active area of research. In this work, we study the loss landscape of deep networks through the eigendecompositions of their Hessian matrix. In particular, we examine how important the negative eigenvalues are and the benefits one can observe in handling them appropriately.
Theano: A Python framework for fast computation of mathematical expressions
May 09, 2016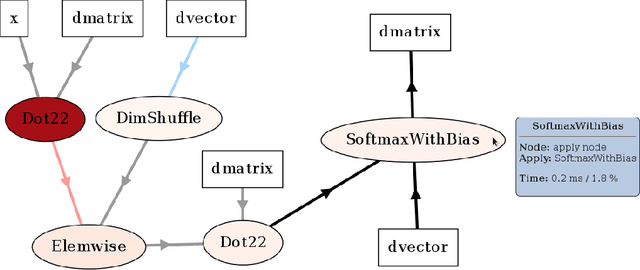
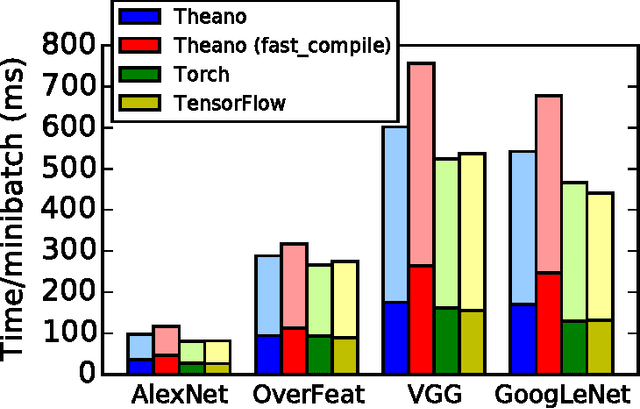
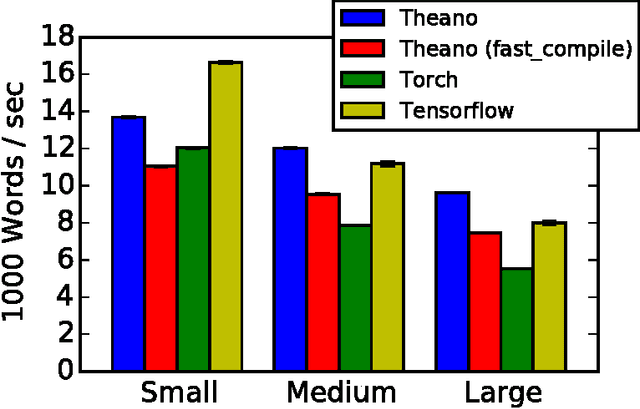
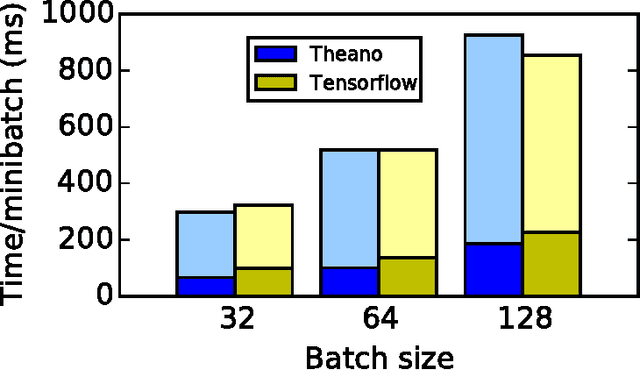
Theano is a Python library that allows to define, optimize, and evaluate mathematical expressions involving multi-dimensional arrays efficiently. Since its introduction, it has been one of the most used CPU and GPU mathematical compilers - especially in the machine learning community - and has shown steady performance improvements. Theano is being actively and continuously developed since 2008, multiple frameworks have been built on top of it and it has been used to produce many state-of-the-art machine learning models. The present article is structured as follows. Section I provides an overview of the Theano software and its community. Section II presents the principal features of Theano and how to use them, and compares them with other similar projects. Section III focuses on recently-introduced functionalities and improvements. Section IV compares the performance of Theano against Torch7 and TensorFlow on several machine learning models. Section V discusses current limitations of Theano and potential ways of improving it.