 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSupersonic: Learning to Generate Source Code Optimizations in C/C++
Oct 02, 2023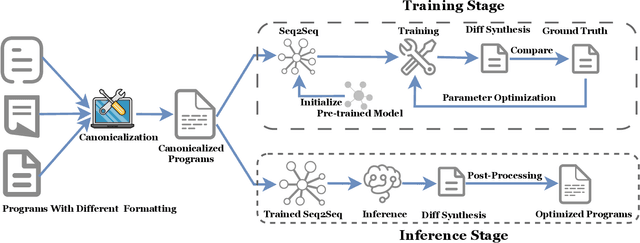


Software optimization refines programs for resource efficiency while preserving functionality. Traditionally, it is a process done by developers and compilers. This paper introduces a third option, automated optimization at the source code level. We present Supersonic, a neural approach targeting minor source code modifications for optimization. Using a seq2seq model, Supersonic is trained on C/C++ program pairs ($x_{t}$, $x_{t+1}$), where $x_{t+1}$ is an optimized version of $x_{t}$, and outputs a diff. Supersonic's performance is benchmarked against OpenAI's GPT-3.5-Turbo and GPT-4 on competitive programming tasks. The experiments show that Supersonic not only outperforms both models on the code optimization task but also minimizes the extent of the change with a model more than 600x smaller than GPT-3.5-Turbo and 3700x smaller than GPT-4.
Multimodal Representation for Neural Code Search
Jul 23, 2021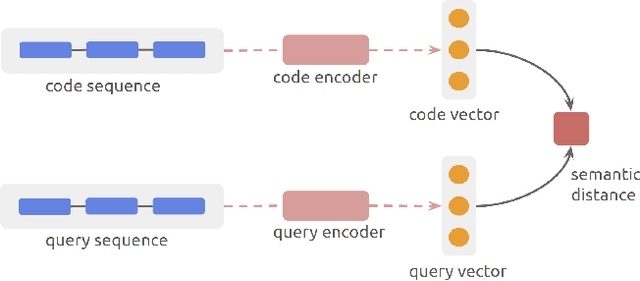
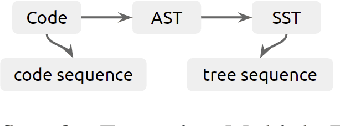
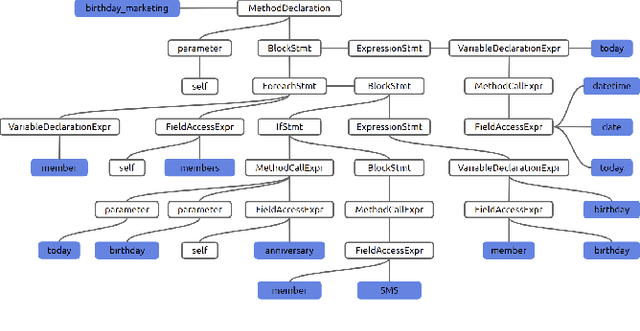
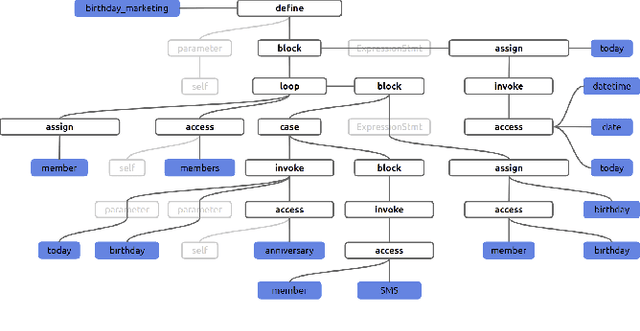
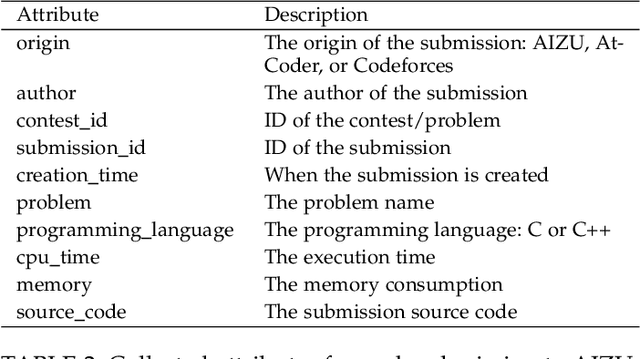
Semantic code search is about finding semantically relevant code snippets for a given natural language query. In the state-of-the-art approaches, the semantic similarity between code and query is quantified as the distance of their representation in the shared vector space. In this paper, to improve the vector space, we introduce tree-serialization methods on a simplified form of AST and build the multimodal representation for the code data. We conduct extensive experiments using a single corpus that is large-scale and multi-language: CodeSearchNet. Our results show that both our tree-serialized representations and multimodal learning model improve the performance of code search. Last, we define intuitive quantification metrics oriented to the completeness of semantic and syntactic information of the code data, to help understand the experimental findings.
Neural Transfer Learning for Repairing Security Vulnerabilities in C Code
Apr 16, 2021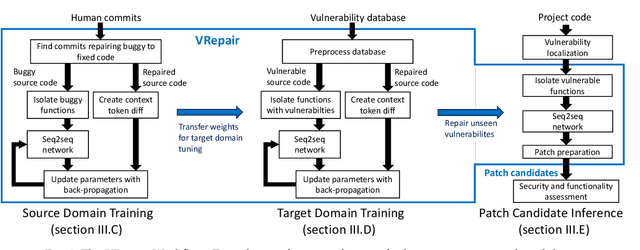


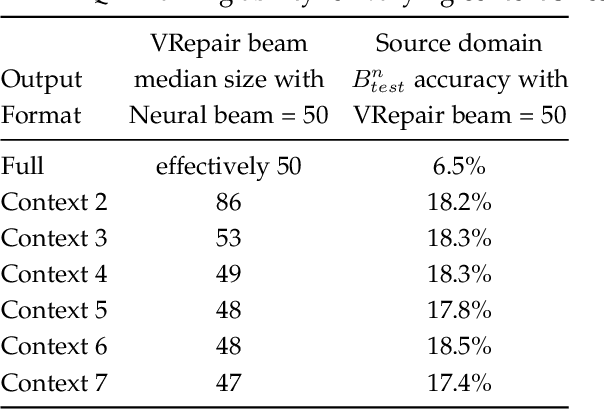
In this paper, we address the problem of automatic repair of software vulnerabilities with deep learning. The major problem with data-driven vulnerability repair is that the few existing datasets of known confirmed vulnerabilities consist of only a few thousand examples. However, training a deep learning model often requires hundreds of thousands of examples. In this work, we leverage the intuition that the bug fixing task and the vulnerability fixing task are related, and the knowledge learned from bug fixes can be transferred to fixing vulnerabilities. In the machine learning community, this technique is called transfer learning. In this paper, we propose an approach for repairing security vulnerabilities named VRepair which is based on transfer learning. VRepair is first trained on a large bug fix corpus, and is then tuned on a vulnerability fix dataset, which is an order of magnitudes smaller. In our experiments, we show that a model trained only on a bug fix corpus can already fix some vulnerabilities. Then, we demonstrate that transfer learning improves the ability to repair vulnerable C functions. In the end, we present evidence that transfer learning produces more stable and superior neural models for vulnerability repair.
Using Sequence-to-Sequence Learning for Repairing C Vulnerabilities
Dec 04, 2019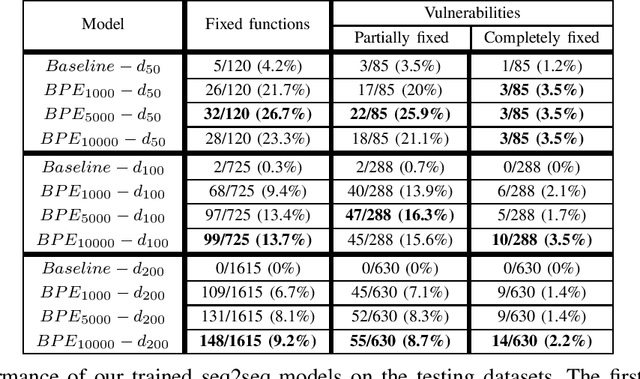
Software vulnerabilities affect all businesses and research is being done to avoid, detect or repair them. In this article, we contribute a new technique for automatic vulnerability fixing. We present a system that uses the rich software development history that can be found on GitHub to train an AI system that generates patches. We apply sequence-to-sequence learning on a big dataset of code changes and we evaluate the trained system on real world vulnerabilities from the CVE database. The result shows the feasibility of using sequence-to-sequence learning for fixing software vulnerabilities.
Learning to Fix Build Errors with Graph2Diff Neural Networks
Nov 04, 2019

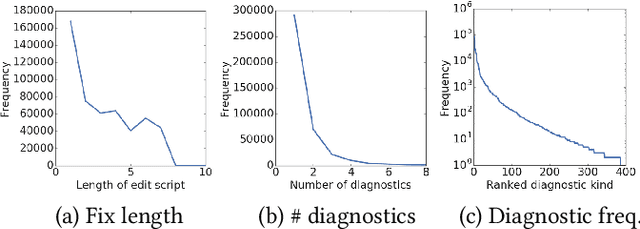

Professional software developers spend a significant amount of time fixing builds, but this has received little attention as a problem in automatic program repair. We present a new deep learning architecture, called Graph2Diff, for automatically localizing and fixing build errors. We represent source code, build configuration files, and compiler diagnostic messages as a graph, and then use a Graph Neural Network model to predict a diff. A diff specifies how to modify the code's abstract syntax tree, represented in the neural network as a sequence of tokens and of pointers to code locations. Our network is an instance of a more general abstraction that we call Graph2Tocopo, which is potentially useful in any development tool for predicting source code changes. We evaluate the model on a dataset of over 500k real build errors and their resolutions from professional developers. Compared to the approach of DeepDelta (Mesbah et al., 2019), our approach tackles the harder task of predicting a more precise diff but still achieves over double the accuracy.
A Literature Study of Embeddings on Source Code
Apr 05, 2019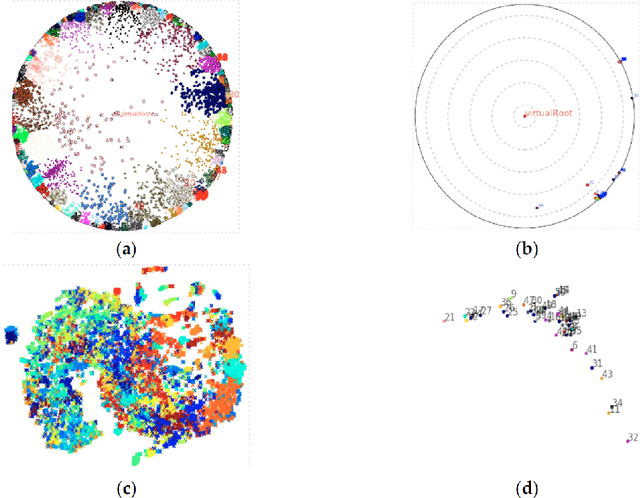
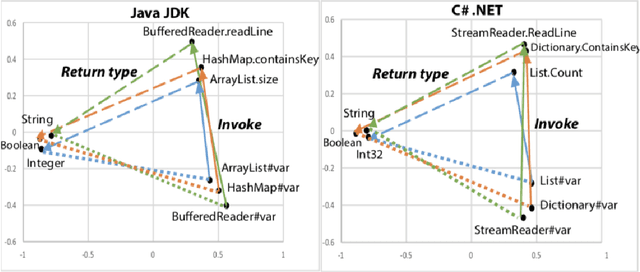
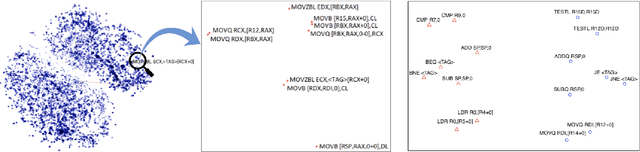
Natural language processing has improved tremendously after the success of word embedding techniques such as word2vec. Recently, the same idea has been applied on source code with encouraging results. In this survey, we aim to collect and discuss the usage of word embedding techniques on programs and source code. The articles in this survey have been collected by asking authors of related work and with an extensive search on Google Scholar. Each article is categorized into five categories: 1. embedding of tokens 2. embedding of functions or methods 3. embedding of sequences or sets of method calls 4. embedding of binary code 5. other embeddings. We also provide links to experimental data and show some remarkable visualization of code embeddings. In summary, word embedding has been successfully applied on different granularities of source code. With access to countless open-source repositories, we see a great potential of applying other data-driven natural language processing techniques on source code in the future.
SequenceR: Sequence-to-Sequence Learning for End-to-End Program Repair
Dec 24, 2018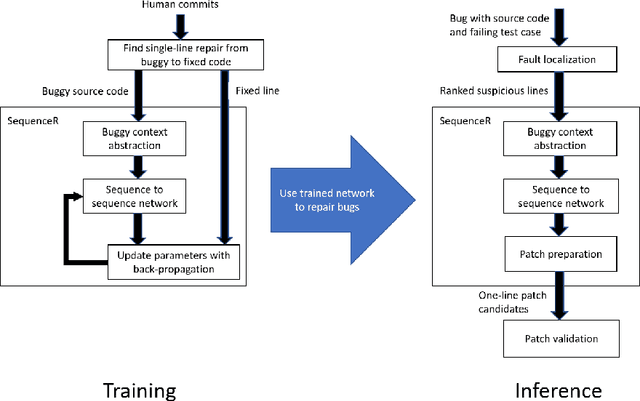



This paper presents a novel end-to-end approach to program repair based on sequence-to-sequence learning. We devise, implement, and evaluate a system, called SequenceR, for fixing bugs based on sequence-to-sequence learning on source code. This approach uses the copy mechanism to overcome the unlimited vocabulary problem that occurs with big code. Our system is data-driven; we train it on 35,578 commits, carefully curated from open-source repositories. We evaluate it on 4,711 independent real bug fixes, as well on the Defects4J benchmark used in program repair research. SequenceR is able to perfectly predict the fixed line for 950/4711 testing samples. It captures a wide range of repair operators without any domain-specific top-down design.
The CodRep Machine Learning on Source Code Competition
Jul 06, 2018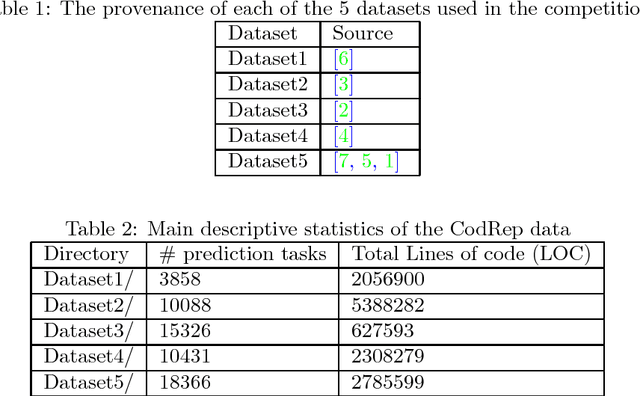
CodRep is a machine learning competition on source code data. It is carefully designed so that anybody can enter the competition, whether professional researchers, students or independent scholars, without specific knowledge in machine learning or program analysis. In particular, it aims at being a common playground on which the machine learning and the software engineering research communities can interact. The competition starts on April 14th 2018 and ends on October 14th 2018. The CodRep data is hosted at https://github.com/KTH/CodRep-competition/.