 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMultimodal Representation for Neural Code Search
Paper and Code
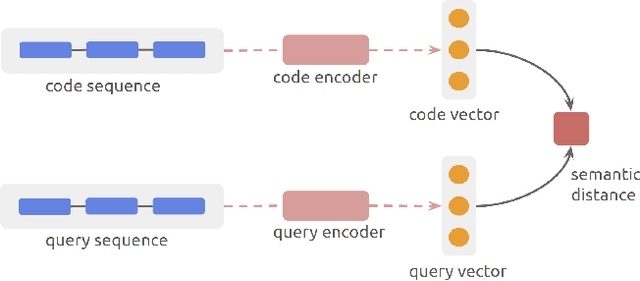
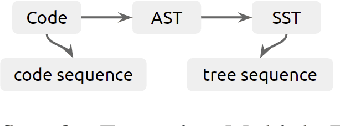
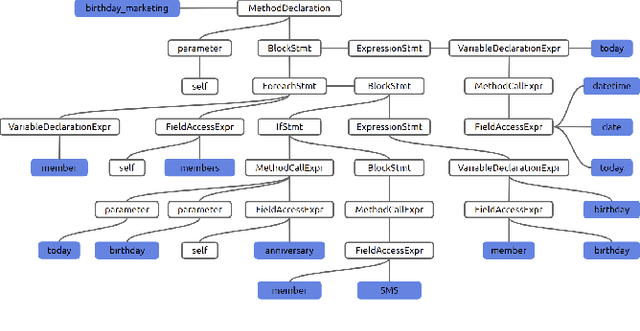
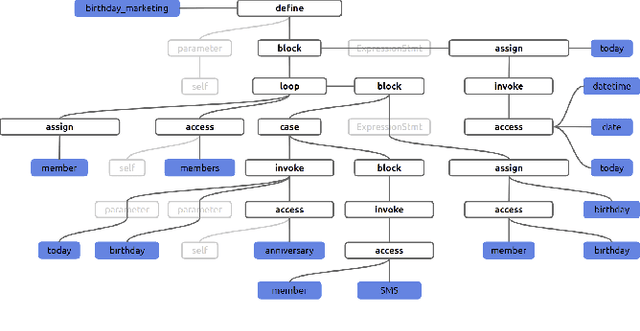
Semantic code search is about finding semantically relevant code snippets for a given natural language query. In the state-of-the-art approaches, the semantic similarity between code and query is quantified as the distance of their representation in the shared vector space. In this paper, to improve the vector space, we introduce tree-serialization methods on a simplified form of AST and build the multimodal representation for the code data. We conduct extensive experiments using a single corpus that is large-scale and multi-language: CodeSearchNet. Our results show that both our tree-serialized representations and multimodal learning model improve the performance of code search. Last, we define intuitive quantification metrics oriented to the completeness of semantic and syntactic information of the code data, to help understand the experimental findings.