 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
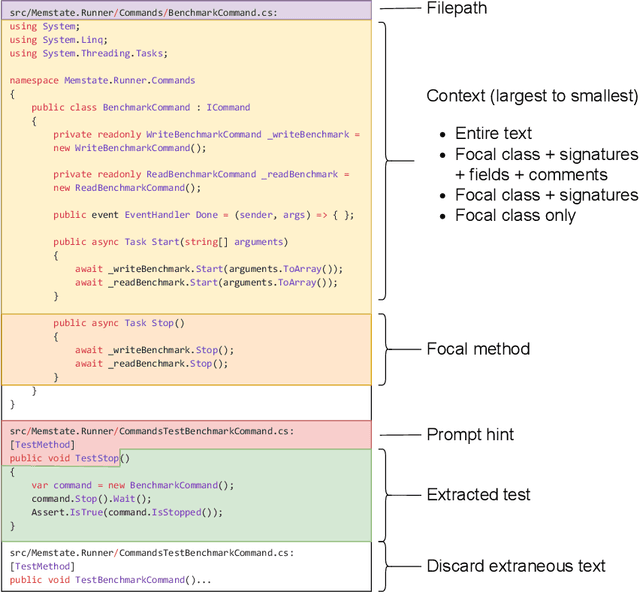
Add to EdgeDynamic Cogeneration of Bug Reproduction Test in Agentic Program Repair
Jan 27, 2026Bug Reproduction Tests (BRTs) have been used in many agentic Automated Program Repair (APR) systems, primarily for validating promising fixes and aiding fix generation. In practice, when developers submit a patch, they often implement the BRT alongside the fix. Our experience deploying agentic APR reveals that developers similarly desire a BRT within AI-generated patches to increase their confidence. However, canonical APR systems tend to generate BRTs and fixes separately, or focus on producing only the fix in the final patch. In this paper, we study agentic APR in the context of cogeneration, where the APR agent is instructed to generate both a fix and a BRT in the same patch. We evaluate the effectiveness of different cogeneration strategies on 120 human-reported bugs at Google and characterize different cogeneration strategies by their influence on APR agent behavior. We develop and evaluate patch selectors that account for test change information to select patches with plausible fixes (and plausible BRTs). Finally, we analyze the root causes of failed cogeneration trajectories. Importantly, we show that cogeneration allows the APR agent to generate BRTs for at least as many bugs as a dedicated BRT agent, without compromising the generation rate of plausible fixes, thereby reducing engineering effort in maintaining and coordinating separate generation pipelines for fix and BRT at scale.
Towards Verified Code Reasoning by LLMs
Sep 30, 2025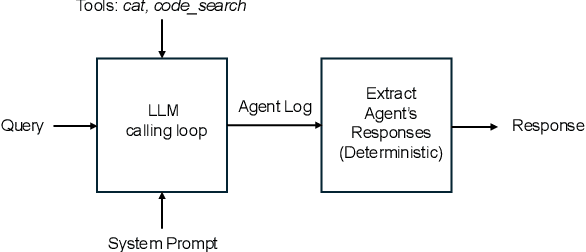

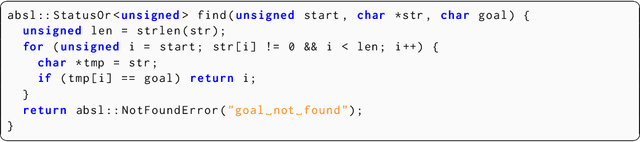
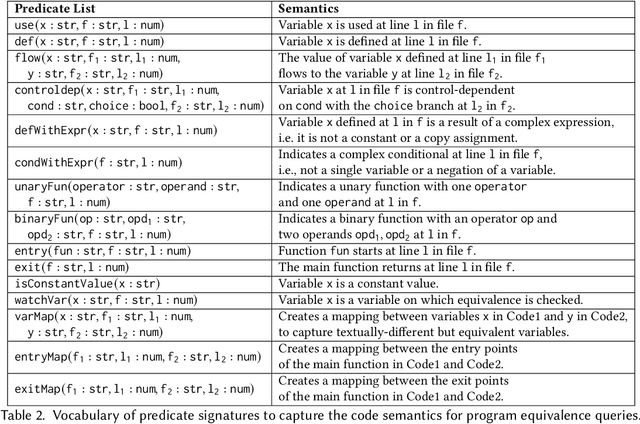
While LLM-based agents are able to tackle a wide variety of code reasoning questions, the answers are not always correct. This prevents the agent from being useful in situations where high precision is desired: (1) helping a software engineer understand a new code base, (2) helping a software engineer during code review sessions, and (3) ensuring that the code generated by an automated code generation system meets certain requirements (e.g. fixes a bug, improves readability, implements a feature). As a result of this lack of trustworthiness, the agent's answers need to be manually verified before they can be trusted. Manually confirming responses from a code reasoning agent requires human effort and can result in slower developer productivity, which weakens the assistance benefits of the agent. In this paper, we describe a method to automatically validate the answers provided by a code reasoning agent by verifying its reasoning steps. At a very high level, the method consists of extracting a formal representation of the agent's response and, subsequently, using formal verification and program analysis tools to verify the agent's reasoning steps. We applied this approach to a benchmark set of 20 uninitialized variable errors detected by sanitizers and 20 program equivalence queries. For the uninitialized variable errors, the formal verification step was able to validate the agent's reasoning on 13/20 examples, and for the program equivalence queries, the formal verification step successfully caught 6/8 incorrect judgments made by the agent.
Agentic Bug Reproduction for Effective Automated Program Repair at Google
Feb 03, 2025



Bug reports often lack sufficient detail for developers to reproduce and fix the underlying defects. Bug Reproduction Tests (BRTs), tests that fail when the bug is present and pass when it has been resolved, are crucial for debugging, but they are rarely included in bug reports, both in open-source and in industrial settings. Thus, automatically generating BRTs from bug reports has the potential to accelerate the debugging process and lower time to repair. This paper investigates automated BRT generation within an industry setting, specifically at Google, focusing on the challenges of a large-scale, proprietary codebase and considering real-world industry bugs extracted from Google's internal issue tracker. We adapt and evaluate a state-of-the-art BRT generation technique, LIBRO, and present our agent-based approach, BRT Agent, which makes use of a fine-tuned Large Language Model (LLM) for code editing. Our BRT Agent significantly outperforms LIBRO, achieving a 28% plausible BRT generation rate, compared to 10% by LIBRO, on 80 human-reported bugs from Google's internal issue tracker. We further investigate the practical value of generated BRTs by integrating them with an Automated Program Repair (APR) system at Google. Our results show that providing BRTs to the APR system results in 30% more bugs with plausible fixes. Additionally, we introduce Ensemble Pass Rate (EPR), a metric which leverages the generated BRTs to select the most promising fixes from all fixes generated by APR system. Our evaluation on EPR for Top-K and threshold-based fix selections demonstrates promising results and trade-offs. For example, EPR correctly selects a plausible fix from a pool of 20 candidates in 70% of cases, based on its top-1 ranking.
Evaluating Agent-based Program Repair at Google
Jan 13, 2025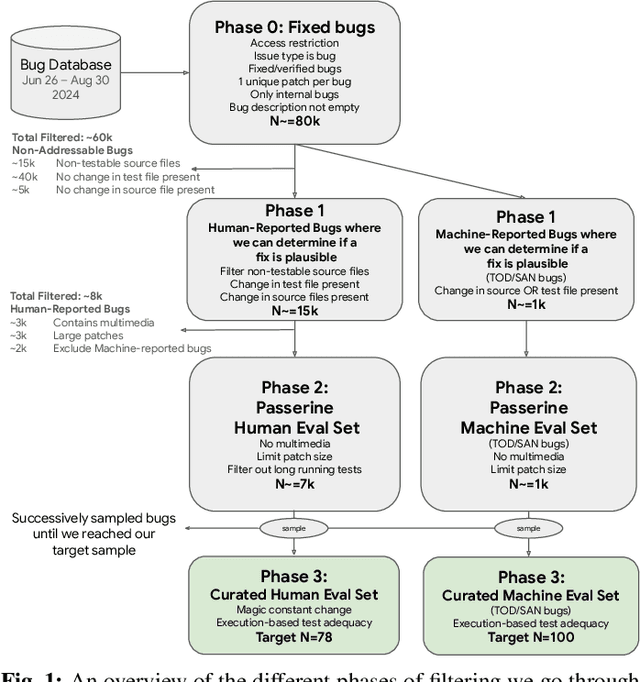



Agent-based program repair offers to automatically resolve complex bugs end-to-end by combining the planning, tool use, and code generation abilities of modern LLMs. Recent work has explored the use of agent-based repair approaches on the popular open-source SWE-Bench, a collection of bugs from highly-rated GitHub Python projects. In addition, various agentic approaches such as SWE-Agent have been proposed to solve bugs in this benchmark. This paper explores the viability of using an agentic approach to address bugs in an enterprise context. To investigate this, we curate an evaluation set of 178 bugs drawn from Google's issue tracking system. This dataset spans both human-reported (78) and machine-reported bugs (100). To establish a repair performance baseline on this benchmark, we implement Passerine, an agent similar in spirit to SWE-Agent that can work within Google's development environment. We show that with 20 trajectory samples and Gemini 1.5 Pro, Passerine can produce a patch that passes bug tests (i.e., plausible) for 73% of machine-reported and 25.6% of human-reported bugs in our evaluation set. After manual examination, we found that 43% of machine-reported bugs and 17.9% of human-reported bugs have at least one patch that is semantically equivalent to the ground-truth patch. These results establish a baseline on an industrially relevant benchmark, which as we show, contains bugs drawn from a different distribution -- in terms of language diversity, size, and spread of changes, etc. -- compared to those in the popular SWE-Bench dataset.
AutoDev: Automated AI-Driven Development
Mar 13, 2024The landscape of software development has witnessed a paradigm shift with the advent of AI-powered assistants, exemplified by GitHub Copilot. However, existing solutions are not leveraging all the potential capabilities available in an IDE such as building, testing, executing code, git operations, etc. Therefore, they are constrained by their limited capabilities, primarily focusing on suggesting code snippets and file manipulation within a chat-based interface. To fill this gap, we present AutoDev, a fully automated AI-driven software development framework, designed for autonomous planning and execution of intricate software engineering tasks. AutoDev enables users to define complex software engineering objectives, which are assigned to AutoDev's autonomous AI Agents to achieve. These AI agents can perform diverse operations on a codebase, including file editing, retrieval, build processes, execution, testing, and git operations. They also have access to files, compiler output, build and testing logs, static analysis tools, and more. This enables the AI Agents to execute tasks in a fully automated manner with a comprehensive understanding of the contextual information required. Furthermore, AutoDev establishes a secure development environment by confining all operations within Docker containers. This framework incorporates guardrails to ensure user privacy and file security, allowing users to define specific permitted or restricted commands and operations within AutoDev. In our evaluation, we tested AutoDev on the HumanEval dataset, obtaining promising results with 91.5% and 87.8% of Pass@1 for code generation and test generation respectively, demonstrating its effectiveness in automating software engineering tasks while maintaining a secure and user-controlled development environment.
Copilot Evaluation Harness: Evaluating LLM-Guided Software Programming
Feb 22, 2024The integration of Large Language Models (LLMs) into Development Environments (IDEs) has become a focal point in modern software development. LLMs such as OpenAI GPT-3.5/4 and Code Llama offer the potential to significantly augment developer productivity by serving as intelligent, chat-driven programming assistants. However, utilizing LLMs out of the box is unlikely to be optimal for any given scenario. Rather, each system requires the LLM to be honed to its set of heuristics to ensure the best performance. In this paper, we introduce the Copilot evaluation harness: a set of data and tools for evaluating LLM-guided IDE interactions, covering various programming scenarios and languages. We propose our metrics as a more robust and information-dense evaluation than previous state of the art evaluation systems. We design and compute both static and execution based success metrics for scenarios encompassing a wide range of developer tasks, including code generation from natural language (generate), documentation generation from code (doc), test case generation (test), bug-fixing (fix), and workspace understanding and query resolution (workspace). These success metrics are designed to evaluate the performance of LLMs within a given IDE and its respective parameter space. Our learnings from evaluating three common LLMs using these metrics can inform the development and validation of future scenarios in LLM guided IDEs.
Reinforcement Learning from Automatic Feedback for High-Quality Unit Test Generation
Oct 03, 2023

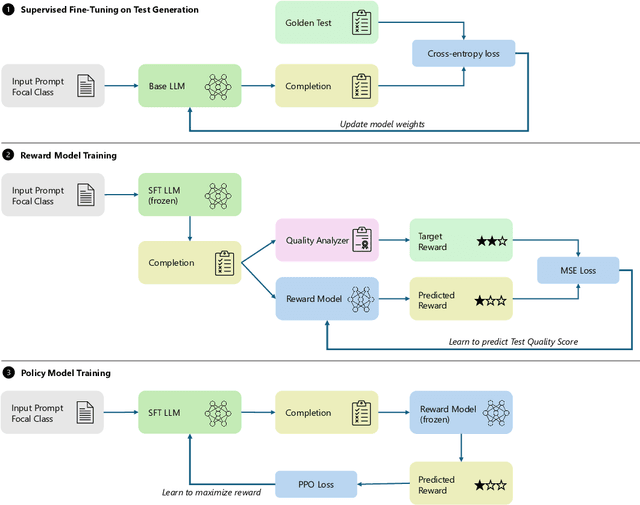
Software testing is a crucial aspect of software development, and the creation of high-quality tests that adhere to best practices is essential for effective maintenance. Recently, Large Language Models (LLMs) have gained popularity for code generation, including the automated creation of test cases. However, these LLMs are often trained on vast amounts of publicly available code, which may include test cases that do not adhere to best practices and may even contain test smells (anti-patterns). To address this issue, we propose a novel technique called Reinforcement Learning from Static Quality Metrics (RLSQM). To begin, we analyze the anti-patterns generated by the LLM and show that LLMs can generate undesirable test smells. Thus, we train specific reward models for each static quality metric, then utilize Proximal Policy Optimization (PPO) to train models for optimizing a single quality metric at a time. Furthermore, we amalgamate these rewards into a unified reward model aimed at capturing different best practices and quality aspects of tests. By comparing RL-trained models with those trained using supervised learning, we provide insights into how reliably utilize RL to improve test generation quality and into the effects of various training strategies. Our experimental results demonstrate that the RL-optimized model consistently generated high-quality test cases compared to the base LLM, improving the model by up to 21%, and successfully generates nearly 100% syntactically correct code. RLSQM also outperformed GPT-4 on four out of seven metrics. This represents a significant step towards enhancing the overall efficiency and reliability of software testing through Reinforcement Learning and static quality metrics. Our data are available at this link: https://figshare.com/s/ded476c8d4c221222849.
Predicting Code Coverage without Execution
Jul 25, 2023



Code coverage is a widely used metric for quantifying the extent to which program elements, such as statements or branches, are executed during testing. Calculating code coverage is resource-intensive, requiring code building and execution with additional overhead for the instrumentation. Furthermore, computing coverage of any snippet of code requires the whole program context. Using Machine Learning to amortize this expensive process could lower the cost of code coverage by requiring only the source code context, and the task of code coverage prediction can be a novel benchmark for judging the ability of models to understand code. We propose a novel benchmark task called Code Coverage Prediction for Large Language Models (LLMs). We formalize this task to evaluate the capability of LLMs in understanding code execution by determining which lines of a method are executed by a given test case and inputs. We curate and release a dataset we call COVERAGEEVAL by executing tests and code from the HumanEval dataset and collecting code coverage information. We report the performance of four state-of-the-art LLMs used for code-related tasks, including OpenAI's GPT-4 and GPT-3.5-Turbo, Google's BARD, and Anthropic's Claude, on the Code Coverage Prediction task. Finally, we argue that code coverage as a metric and pre-training data source are valuable for overall LLM performance on software engineering tasks.
An Empirical Investigation into the Use of Image Captioning for Automated Software Documentation
Jan 03, 2023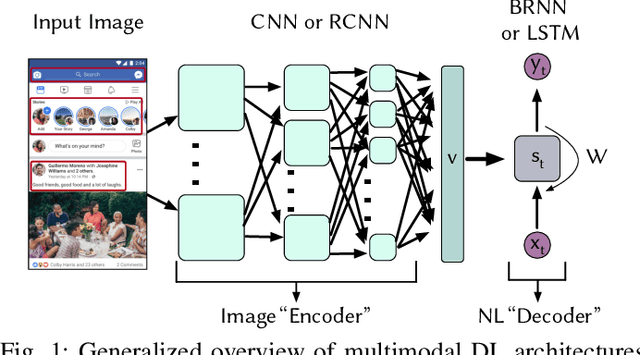
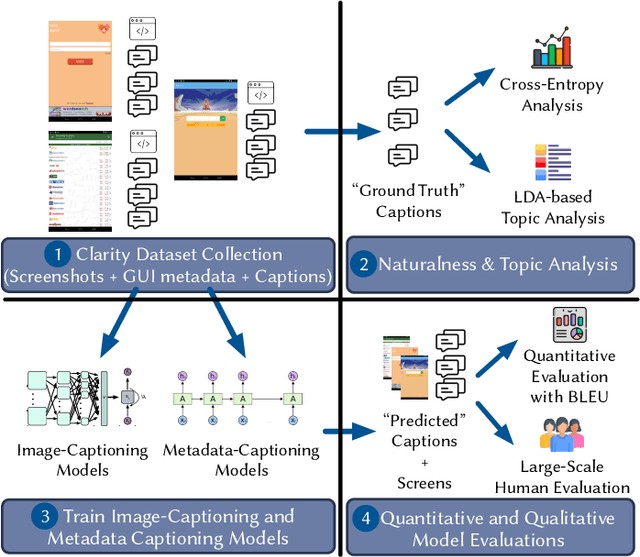
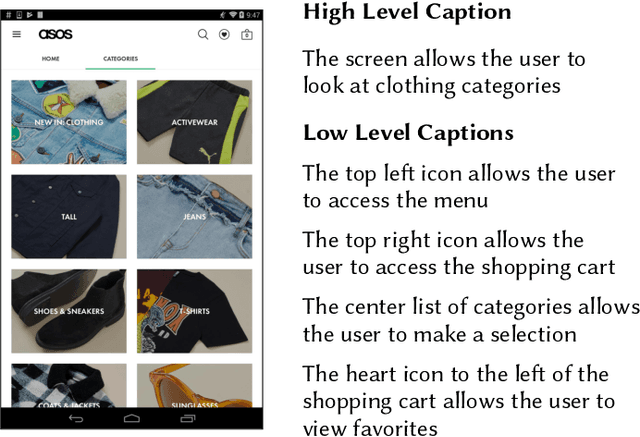
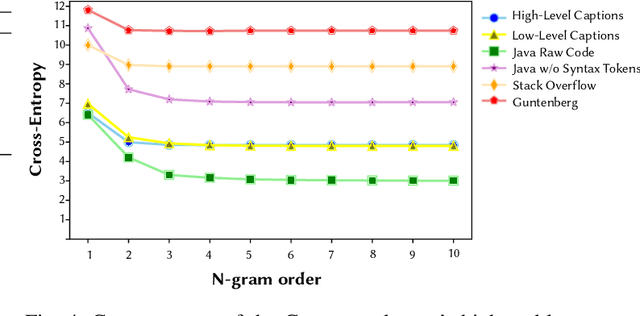
Existing automated techniques for software documentation typically attempt to reason between two main sources of information: code and natural language. However, this reasoning process is often complicated by the lexical gap between more abstract natural language and more structured programming languages. One potential bridge for this gap is the Graphical User Interface (GUI), as GUIs inherently encode salient information about underlying program functionality into rich, pixel-based data representations. This paper offers one of the first comprehensive empirical investigations into the connection between GUIs and functional, natural language descriptions of software. First, we collect, analyze, and open source a large dataset of functional GUI descriptions consisting of 45,998 descriptions for 10,204 screenshots from popular Android applications. The descriptions were obtained from human labelers and underwent several quality control mechanisms. To gain insight into the representational potential of GUIs, we investigate the ability of four Neural Image Captioning models to predict natural language descriptions of varying granularity when provided a screenshot as input. We evaluate these models quantitatively, using common machine translation metrics, and qualitatively through a large-scale user study. Finally, we offer learned lessons and a discussion of the potential shown by multimodal models to enhance future techniques for automated software documentation.
Exploring and Evaluating Personalized Models for Code Generation
Aug 29, 2022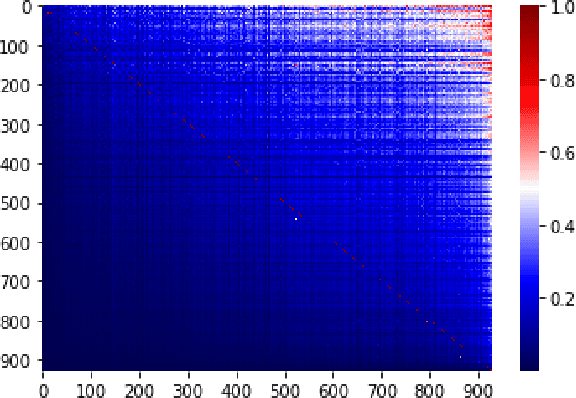
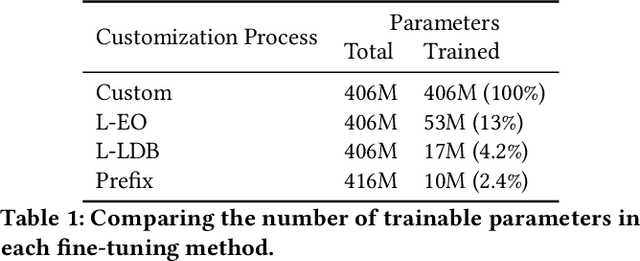
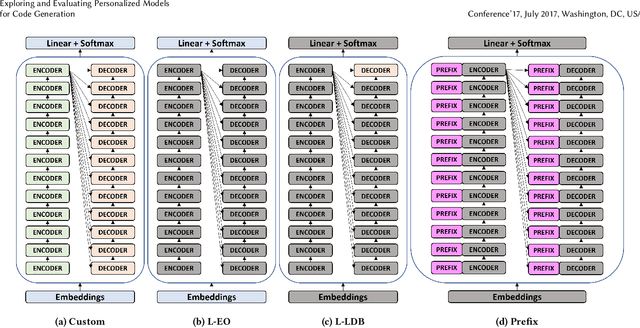
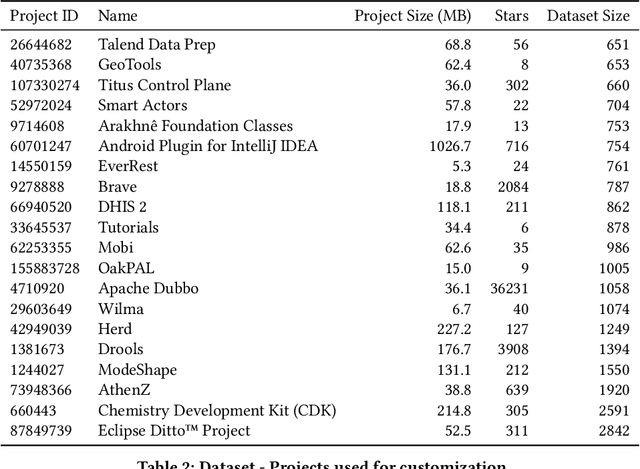
Large Transformer models achieved the state-of-the-art status for Natural Language Understanding tasks and are increasingly becoming the baseline model architecture for modeling source code. Transformers are usually pre-trained on large unsupervised corpora, learning token representations and transformations relevant to modeling generally available text, and are then fine-tuned on a particular downstream task of interest. While fine-tuning is a tried-and-true method for adapting a model to a new domain -- for example, question-answering on a given topic -- generalization remains an on-going challenge. In this paper, we explore and evaluate transformer model fine-tuning for personalization. In the context of generating unit tests for Java methods, we evaluate learning to personalize to a specific software project using several personalization techniques. We consider three key approaches: (i) custom fine-tuning, which allows all the model parameters to be tuned; (ii) lightweight fine-tuning, which freezes most of the model's parameters, allowing tuning of the token embeddings and softmax layer only or the final layer alone; (iii) prefix tuning, which keeps model parameters frozen, but optimizes a small project-specific prefix vector. Each of these techniques offers a trade-off in total compute cost and predictive performance, which we evaluate by code and task-specific metrics, training time, and total computational operations. We compare these fine-tuning strategies for code generation and discuss the potential generalization and cost benefits of each in various deployment scenarios.