 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDynamic Cogeneration of Bug Reproduction Test in Agentic Program Repair
Jan 27, 2026Bug Reproduction Tests (BRTs) have been used in many agentic Automated Program Repair (APR) systems, primarily for validating promising fixes and aiding fix generation. In practice, when developers submit a patch, they often implement the BRT alongside the fix. Our experience deploying agentic APR reveals that developers similarly desire a BRT within AI-generated patches to increase their confidence. However, canonical APR systems tend to generate BRTs and fixes separately, or focus on producing only the fix in the final patch. In this paper, we study agentic APR in the context of cogeneration, where the APR agent is instructed to generate both a fix and a BRT in the same patch. We evaluate the effectiveness of different cogeneration strategies on 120 human-reported bugs at Google and characterize different cogeneration strategies by their influence on APR agent behavior. We develop and evaluate patch selectors that account for test change information to select patches with plausible fixes (and plausible BRTs). Finally, we analyze the root causes of failed cogeneration trajectories. Importantly, we show that cogeneration allows the APR agent to generate BRTs for at least as many bugs as a dedicated BRT agent, without compromising the generation rate of plausible fixes, thereby reducing engineering effort in maintaining and coordinating separate generation pipelines for fix and BRT at scale.
Agentic Bug Reproduction for Effective Automated Program Repair at Google
Feb 03, 2025



Bug reports often lack sufficient detail for developers to reproduce and fix the underlying defects. Bug Reproduction Tests (BRTs), tests that fail when the bug is present and pass when it has been resolved, are crucial for debugging, but they are rarely included in bug reports, both in open-source and in industrial settings. Thus, automatically generating BRTs from bug reports has the potential to accelerate the debugging process and lower time to repair. This paper investigates automated BRT generation within an industry setting, specifically at Google, focusing on the challenges of a large-scale, proprietary codebase and considering real-world industry bugs extracted from Google's internal issue tracker. We adapt and evaluate a state-of-the-art BRT generation technique, LIBRO, and present our agent-based approach, BRT Agent, which makes use of a fine-tuned Large Language Model (LLM) for code editing. Our BRT Agent significantly outperforms LIBRO, achieving a 28% plausible BRT generation rate, compared to 10% by LIBRO, on 80 human-reported bugs from Google's internal issue tracker. We further investigate the practical value of generated BRTs by integrating them with an Automated Program Repair (APR) system at Google. Our results show that providing BRTs to the APR system results in 30% more bugs with plausible fixes. Additionally, we introduce Ensemble Pass Rate (EPR), a metric which leverages the generated BRTs to select the most promising fixes from all fixes generated by APR system. Our evaluation on EPR for Top-K and threshold-based fix selections demonstrates promising results and trade-offs. For example, EPR correctly selects a plausible fix from a pool of 20 candidates in 70% of cases, based on its top-1 ranking.
Evaluating Agent-based Program Repair at Google
Jan 13, 2025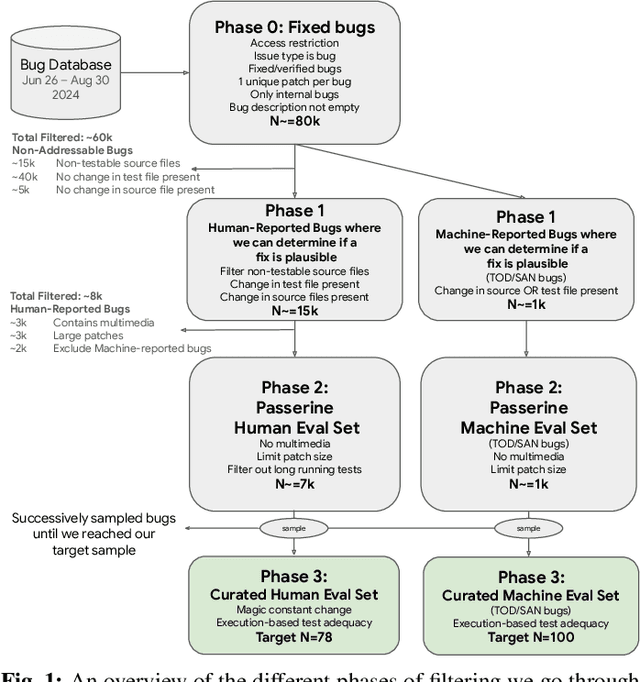



Agent-based program repair offers to automatically resolve complex bugs end-to-end by combining the planning, tool use, and code generation abilities of modern LLMs. Recent work has explored the use of agent-based repair approaches on the popular open-source SWE-Bench, a collection of bugs from highly-rated GitHub Python projects. In addition, various agentic approaches such as SWE-Agent have been proposed to solve bugs in this benchmark. This paper explores the viability of using an agentic approach to address bugs in an enterprise context. To investigate this, we curate an evaluation set of 178 bugs drawn from Google's issue tracking system. This dataset spans both human-reported (78) and machine-reported bugs (100). To establish a repair performance baseline on this benchmark, we implement Passerine, an agent similar in spirit to SWE-Agent that can work within Google's development environment. We show that with 20 trajectory samples and Gemini 1.5 Pro, Passerine can produce a patch that passes bug tests (i.e., plausible) for 73% of machine-reported and 25.6% of human-reported bugs in our evaluation set. After manual examination, we found that 43% of machine-reported bugs and 17.9% of human-reported bugs have at least one patch that is semantically equivalent to the ground-truth patch. These results establish a baseline on an industrially relevant benchmark, which as we show, contains bugs drawn from a different distribution -- in terms of language diversity, size, and spread of changes, etc. -- compared to those in the popular SWE-Bench dataset.