 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRealBirdID: Benchmarking Bird Species Identification in the Era of MLLMs
Mar 27, 2026Fine-grained bird species identification in the wild is frequently unanswerable from a single image: key cues may be non-visual (e.g. vocalization), or obscured due to occlusion, camera angle, or low resolution. Yet today's multimodal systems are typically judged on answerable, in-schema cases, encouraging confident guesses rather than principled abstention. We propose the RealBirdID benchmark: given an image of a bird, a system should either answer with a species or abstain with a concrete, evidence-based rationale: "requires vocalization," "low quality image," or "view obstructed". For each genus, the dataset includes a validation split composed of curated unanswerable examples with labeled rationales, paired with a companion set of clearly answerable instances. We find that (1) the species identification on the answerable set is challenging for a variety of open-source and proprietary models (less than 13% accuracy for MLLMs including GPT-5 and Gemini-2.5 Pro), (2) models with greater classification ability are not necessarily more calibrated to abstain from unanswerable examples, and (3) that MLLMs generally fail at providing correct reasons even when they do abstain. RealBirdID establishes a focused target for abstention-aware fine-grained recognition and a recipe for measuring progress.
Agentic Bug Reproduction for Effective Automated Program Repair at Google
Feb 03, 2025



Bug reports often lack sufficient detail for developers to reproduce and fix the underlying defects. Bug Reproduction Tests (BRTs), tests that fail when the bug is present and pass when it has been resolved, are crucial for debugging, but they are rarely included in bug reports, both in open-source and in industrial settings. Thus, automatically generating BRTs from bug reports has the potential to accelerate the debugging process and lower time to repair. This paper investigates automated BRT generation within an industry setting, specifically at Google, focusing on the challenges of a large-scale, proprietary codebase and considering real-world industry bugs extracted from Google's internal issue tracker. We adapt and evaluate a state-of-the-art BRT generation technique, LIBRO, and present our agent-based approach, BRT Agent, which makes use of a fine-tuned Large Language Model (LLM) for code editing. Our BRT Agent significantly outperforms LIBRO, achieving a 28% plausible BRT generation rate, compared to 10% by LIBRO, on 80 human-reported bugs from Google's internal issue tracker. We further investigate the practical value of generated BRTs by integrating them with an Automated Program Repair (APR) system at Google. Our results show that providing BRTs to the APR system results in 30% more bugs with plausible fixes. Additionally, we introduce Ensemble Pass Rate (EPR), a metric which leverages the generated BRTs to select the most promising fixes from all fixes generated by APR system. Our evaluation on EPR for Top-K and threshold-based fix selections demonstrates promising results and trade-offs. For example, EPR correctly selects a plausible fix from a pool of 20 candidates in 70% of cases, based on its top-1 ranking.
Evaluating Agent-based Program Repair at Google
Jan 13, 2025



Agent-based program repair offers to automatically resolve complex bugs end-to-end by combining the planning, tool use, and code generation abilities of modern LLMs. Recent work has explored the use of agent-based repair approaches on the popular open-source SWE-Bench, a collection of bugs from highly-rated GitHub Python projects. In addition, various agentic approaches such as SWE-Agent have been proposed to solve bugs in this benchmark. This paper explores the viability of using an agentic approach to address bugs in an enterprise context. To investigate this, we curate an evaluation set of 178 bugs drawn from Google's issue tracking system. This dataset spans both human-reported (78) and machine-reported bugs (100). To establish a repair performance baseline on this benchmark, we implement Passerine, an agent similar in spirit to SWE-Agent that can work within Google's development environment. We show that with 20 trajectory samples and Gemini 1.5 Pro, Passerine can produce a patch that passes bug tests (i.e., plausible) for 73% of machine-reported and 25.6% of human-reported bugs in our evaluation set. After manual examination, we found that 43% of machine-reported bugs and 17.9% of human-reported bugs have at least one patch that is semantically equivalent to the ground-truth patch. These results establish a baseline on an industrially relevant benchmark, which as we show, contains bugs drawn from a different distribution -- in terms of language diversity, size, and spread of changes, etc. -- compared to those in the popular SWE-Bench dataset.
Task2Box: Box Embeddings for Modeling Asymmetric Task Relationships
Mar 29, 2024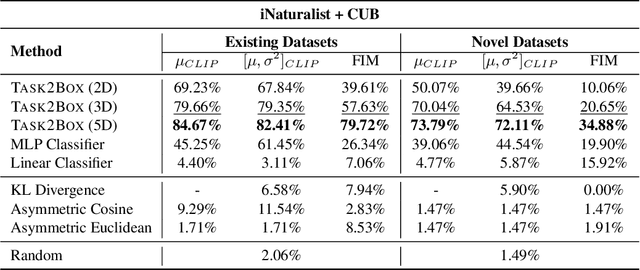
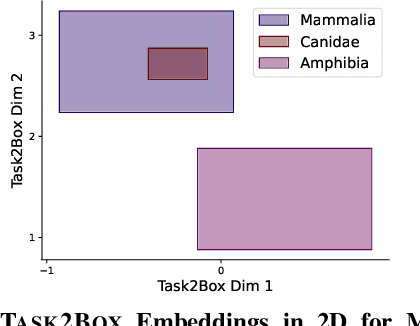
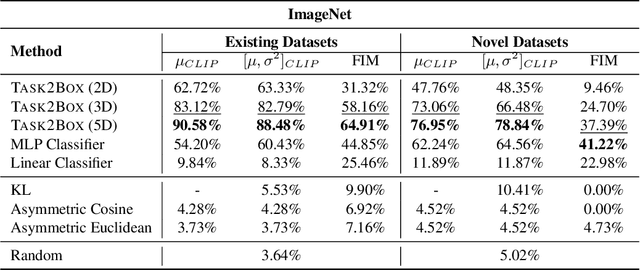
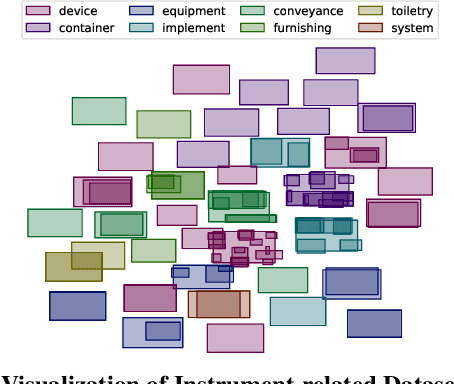
Modeling and visualizing relationships between tasks or datasets is an important step towards solving various meta-tasks such as dataset discovery, multi-tasking, and transfer learning. However, many relationships, such as containment and transferability, are naturally asymmetric and current approaches for representation and visualization (e.g., t-SNE) do not readily support this. We propose Task2Box, an approach to represent tasks using box embeddings -- axis-aligned hyperrectangles in low dimensional spaces -- that can capture asymmetric relationships between them through volumetric overlaps. We show that Task2Box accurately predicts unseen hierarchical relationships between nodes in ImageNet and iNaturalist datasets, as well as transferability between tasks in the Taskonomy benchmark. We also show that box embeddings estimated from task representations (e.g., CLIP, Task2Vec, or attribute based) can be used to predict relationships between unseen tasks more accurately than classifiers trained on the same representations, as well as handcrafted asymmetric distances (e.g., KL divergence). This suggests that low-dimensional box embeddings can effectively capture these task relationships and have the added advantage of being interpretable. We use the approach to visualize relationships among publicly available image classification datasets on popular dataset hosting platform called Hugging Face.
COSE: A Consistency-Sensitivity Metric for Saliency on Image Classification
Sep 20, 2023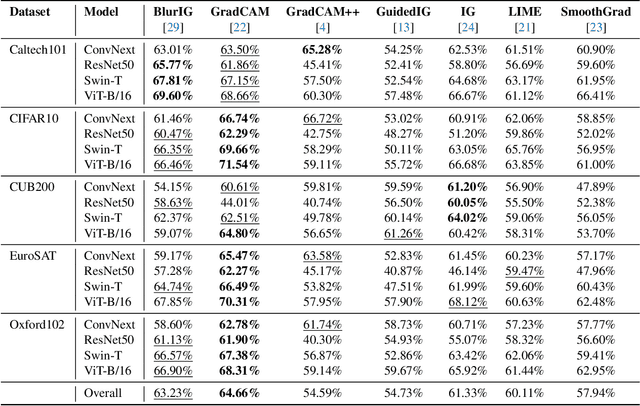
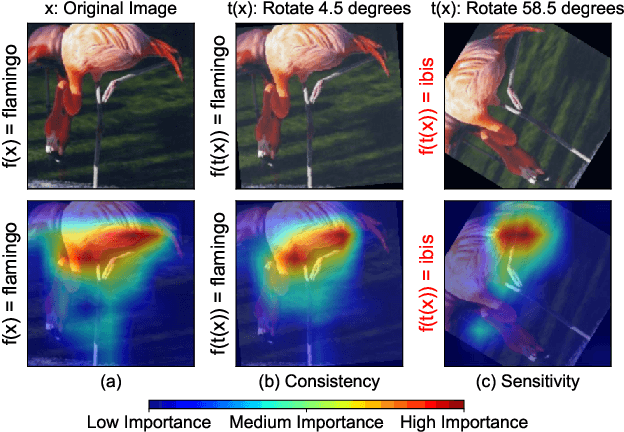
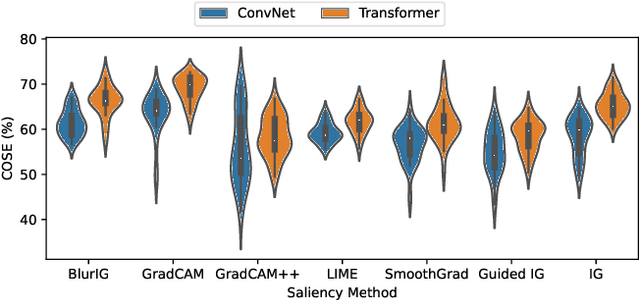
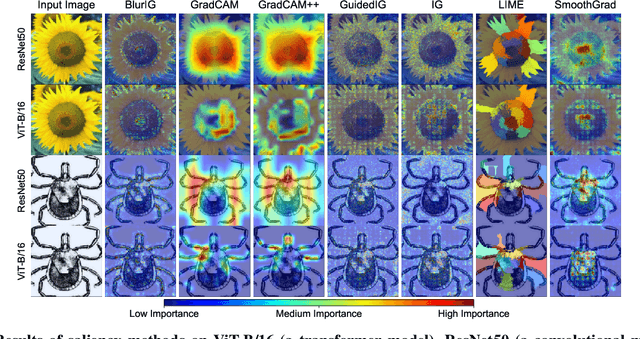
We present a set of metrics that utilize vision priors to effectively assess the performance of saliency methods on image classification tasks. To understand behavior in deep learning models, many methods provide visual saliency maps emphasizing image regions that most contribute to a model prediction. However, there is limited work on analyzing the reliability of saliency methods in explaining model decisions. We propose the metric COnsistency-SEnsitivity (COSE) that quantifies the equivariant and invariant properties of visual model explanations using simple data augmentations. Through our metrics, we show that although saliency methods are thought to be architecture-independent, most methods could better explain transformer-based models over convolutional-based models. In addition, GradCAM was found to outperform other methods in terms of COSE but was shown to have limitations such as lack of variability for fine-grained datasets. The duality between consistency and sensitivity allow the analysis of saliency methods from different angles. Ultimately, we find that it is important to balance these two metrics for a saliency map to faithfully show model behavior.