 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSuperRivolution: Fine-Scale Rivers from Coarse Temporal Satellite Imagery
Nov 12, 2025
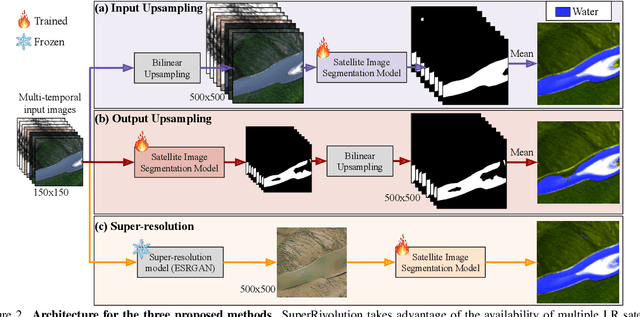
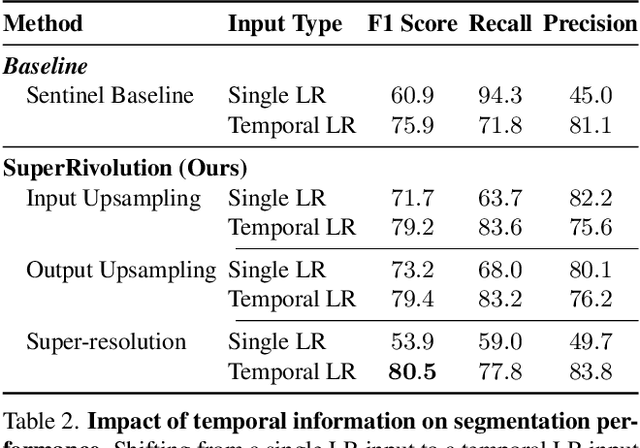
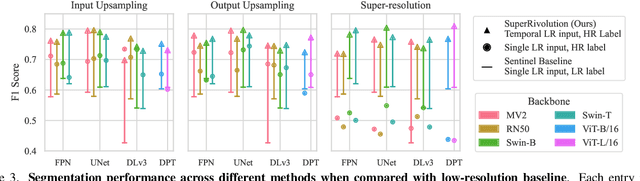
Satellite missions provide valuable optical data for monitoring rivers at diverse spatial and temporal scales. However, accessibility remains a challenge: high-resolution imagery is ideal for fine-grained monitoring but is typically scarce and expensive compared to low-resolution imagery. To address this gap, we introduce SuperRivolution, a framework that improves river segmentation resolution by leveraging information from time series of low-resolution satellite images. We contribute a new benchmark dataset of 9,810 low-resolution temporal images paired with high-resolution labels from an existing river monitoring dataset. Using this benchmark, we investigate multiple strategies for river segmentation, including ensembling single-image models, applying image super-resolution, and developing end-to-end models trained on temporal sequences. SuperRivolution significantly outperforms single-image methods and baseline temporal approaches, narrowing the gap with supervised high-resolution models. For example, the F1 score for river segmentation improves from 60.9% to 80.5%, while the state-of-the-art model operating on high-resolution images achieves 94.1%. Similar improvements are also observed in river width estimation tasks. Our results highlight the potential of publicly available low-resolution satellite archives for fine-scale river monitoring.
WildSAT: Learning Satellite Image Representations from Wildlife Observations
Dec 19, 2024What does the presence of a species reveal about a geographic location? We posit that habitat, climate, and environmental preferences reflected in species distributions provide a rich source of supervision for learning satellite image representations. We introduce WildSAT, which pairs satellite images with millions of geo-tagged wildlife observations readily-available on citizen science platforms. WildSAT uses a contrastive learning framework to combine information from species distribution maps with text descriptions that capture habitat and range details, alongside satellite images, to train or fine-tune models. On a range of downstream satellite image recognition tasks, this significantly improves the performance of both randomly initialized models and pre-trained models from sources like ImageNet or specialized satellite image datasets. Additionally, the alignment with text enables zero-shot retrieval, allowing for search based on general descriptions of locations. We demonstrate that WildSAT achieves better representations than recent methods that utilize other forms of cross-modal supervision, such as aligning satellite images with ground images or wildlife photos. Finally, we analyze the impact of various design choices on downstream performance, highlighting the general applicability of our approach.
Improving Satellite Imagery Masking using Multi-task and Transfer Learning
Dec 11, 2024



Many remote sensing applications employ masking of pixels in satellite imagery for subsequent measurements. For example, estimating water quality variables, such as Suspended Sediment Concentration (SSC) requires isolating pixels depicting water bodies unaffected by clouds, their shadows, terrain shadows, and snow and ice formation. A significant bottleneck is the reliance on a variety of data products (e.g., satellite imagery, elevation maps), and a lack of precision in individual steps affecting estimation accuracy. We propose to improve both the accuracy and computational efficiency of masking by developing a system that predicts all required masks from Harmonized Landsat and Sentinel (HLS) imagery. Our model employs multi-tasking to share computation and enable higher accuracy across tasks. We experiment with recent advances in deep network architectures and show that masking models can benefit from these, especially when combined with pre-training on large satellite imagery datasets. We present a collection of models offering different speed/accuracy trade-offs for masking. MobileNet variants are the fastest, and perform competitively with larger architectures. Transformer-based architectures are the slowest, but benefit the most from pre-training on large satellite imagery datasets. Our models provide a 9% F1 score improvement compared to previous work on water pixel identification. When integrated with an SSC estimation system, our models result in a 30x speedup while reducing estimation error by 2.64 mg/L, allowing for global-scale analysis. We also evaluate our model on a recently proposed cloud and cloud shadow estimation benchmark, where we outperform the current state-of-the-art model by at least 6% in F1 score.
Task2Box: Box Embeddings for Modeling Asymmetric Task Relationships
Mar 29, 2024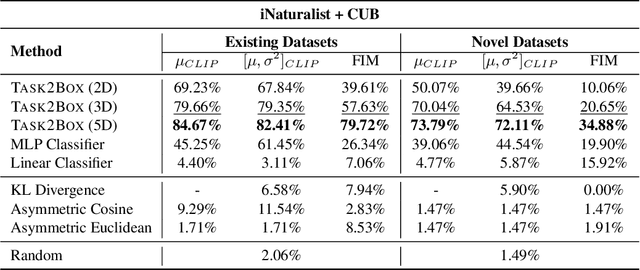
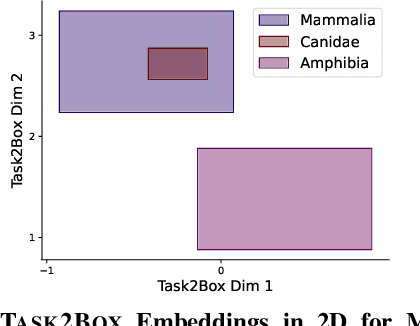
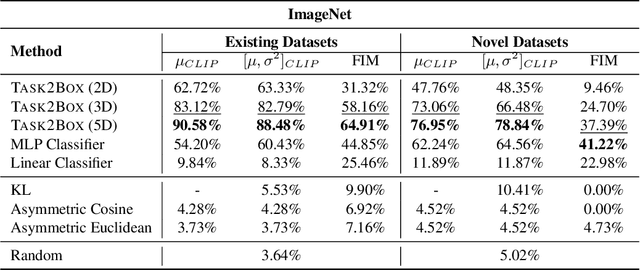
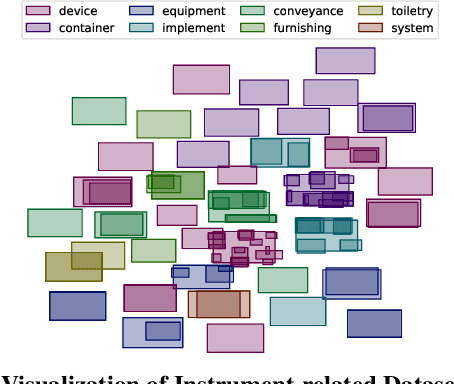
Modeling and visualizing relationships between tasks or datasets is an important step towards solving various meta-tasks such as dataset discovery, multi-tasking, and transfer learning. However, many relationships, such as containment and transferability, are naturally asymmetric and current approaches for representation and visualization (e.g., t-SNE) do not readily support this. We propose Task2Box, an approach to represent tasks using box embeddings -- axis-aligned hyperrectangles in low dimensional spaces -- that can capture asymmetric relationships between them through volumetric overlaps. We show that Task2Box accurately predicts unseen hierarchical relationships between nodes in ImageNet and iNaturalist datasets, as well as transferability between tasks in the Taskonomy benchmark. We also show that box embeddings estimated from task representations (e.g., CLIP, Task2Vec, or attribute based) can be used to predict relationships between unseen tasks more accurately than classifiers trained on the same representations, as well as handcrafted asymmetric distances (e.g., KL divergence). This suggests that low-dimensional box embeddings can effectively capture these task relationships and have the added advantage of being interpretable. We use the approach to visualize relationships among publicly available image classification datasets on popular dataset hosting platform called Hugging Face.
COSE: A Consistency-Sensitivity Metric for Saliency on Image Classification
Sep 20, 2023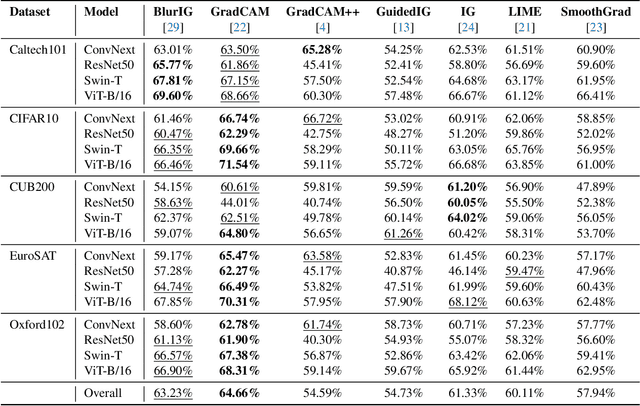
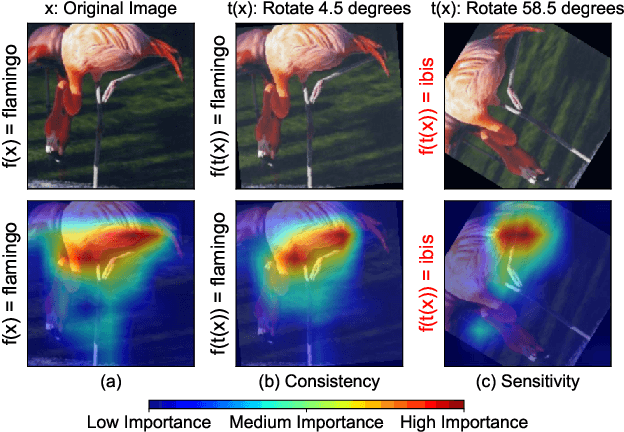
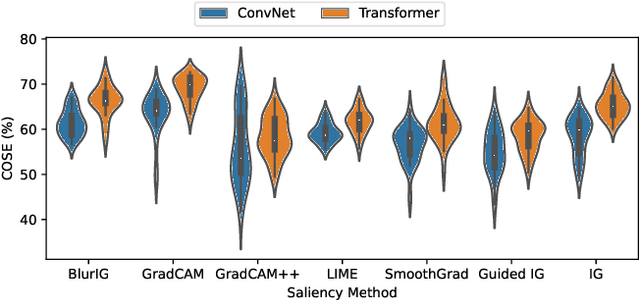
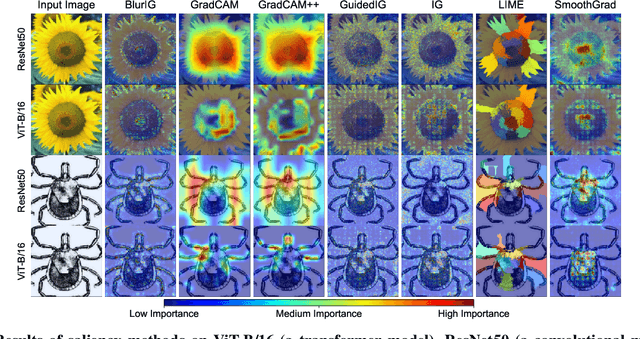
We present a set of metrics that utilize vision priors to effectively assess the performance of saliency methods on image classification tasks. To understand behavior in deep learning models, many methods provide visual saliency maps emphasizing image regions that most contribute to a model prediction. However, there is limited work on analyzing the reliability of saliency methods in explaining model decisions. We propose the metric COnsistency-SEnsitivity (COSE) that quantifies the equivariant and invariant properties of visual model explanations using simple data augmentations. Through our metrics, we show that although saliency methods are thought to be architecture-independent, most methods could better explain transformer-based models over convolutional-based models. In addition, GradCAM was found to outperform other methods in terms of COSE but was shown to have limitations such as lack of variability for fine-grained datasets. The duality between consistency and sensitivity allow the analysis of saliency methods from different angles. Ultimately, we find that it is important to balance these two metrics for a saliency map to faithfully show model behavior.