 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDynamic Cogeneration of Bug Reproduction Test in Agentic Program Repair
Jan 27, 2026Bug Reproduction Tests (BRTs) have been used in many agentic Automated Program Repair (APR) systems, primarily for validating promising fixes and aiding fix generation. In practice, when developers submit a patch, they often implement the BRT alongside the fix. Our experience deploying agentic APR reveals that developers similarly desire a BRT within AI-generated patches to increase their confidence. However, canonical APR systems tend to generate BRTs and fixes separately, or focus on producing only the fix in the final patch. In this paper, we study agentic APR in the context of cogeneration, where the APR agent is instructed to generate both a fix and a BRT in the same patch. We evaluate the effectiveness of different cogeneration strategies on 120 human-reported bugs at Google and characterize different cogeneration strategies by their influence on APR agent behavior. We develop and evaluate patch selectors that account for test change information to select patches with plausible fixes (and plausible BRTs). Finally, we analyze the root causes of failed cogeneration trajectories. Importantly, we show that cogeneration allows the APR agent to generate BRTs for at least as many bugs as a dedicated BRT agent, without compromising the generation rate of plausible fixes, thereby reducing engineering effort in maintaining and coordinating separate generation pipelines for fix and BRT at scale.
Agentic Bug Reproduction for Effective Automated Program Repair at Google
Feb 03, 2025



Bug reports often lack sufficient detail for developers to reproduce and fix the underlying defects. Bug Reproduction Tests (BRTs), tests that fail when the bug is present and pass when it has been resolved, are crucial for debugging, but they are rarely included in bug reports, both in open-source and in industrial settings. Thus, automatically generating BRTs from bug reports has the potential to accelerate the debugging process and lower time to repair. This paper investigates automated BRT generation within an industry setting, specifically at Google, focusing on the challenges of a large-scale, proprietary codebase and considering real-world industry bugs extracted from Google's internal issue tracker. We adapt and evaluate a state-of-the-art BRT generation technique, LIBRO, and present our agent-based approach, BRT Agent, which makes use of a fine-tuned Large Language Model (LLM) for code editing. Our BRT Agent significantly outperforms LIBRO, achieving a 28% plausible BRT generation rate, compared to 10% by LIBRO, on 80 human-reported bugs from Google's internal issue tracker. We further investigate the practical value of generated BRTs by integrating them with an Automated Program Repair (APR) system at Google. Our results show that providing BRTs to the APR system results in 30% more bugs with plausible fixes. Additionally, we introduce Ensemble Pass Rate (EPR), a metric which leverages the generated BRTs to select the most promising fixes from all fixes generated by APR system. Our evaluation on EPR for Top-K and threshold-based fix selections demonstrates promising results and trade-offs. For example, EPR correctly selects a plausible fix from a pool of 20 candidates in 70% of cases, based on its top-1 ranking.
Configuration Validation with Large Language Models
Oct 15, 2023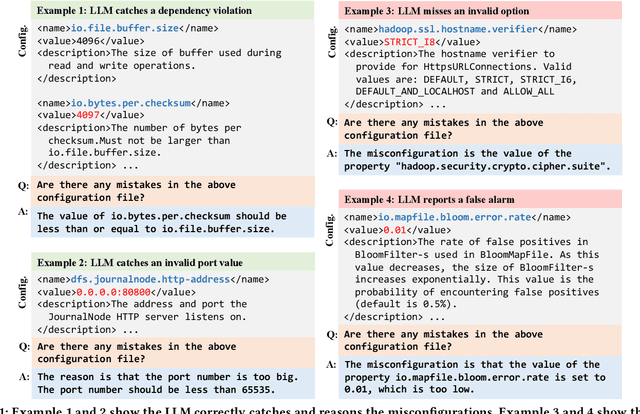

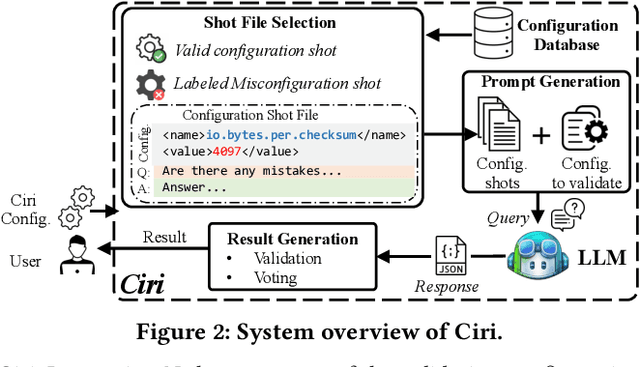
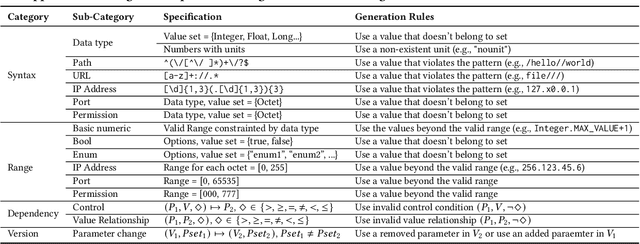
Misconfigurations are the major causes of software failures. Existing configuration validation techniques rely on manually written rules or test cases, which are expensive to implement and maintain, and are hard to be comprehensive. Leveraging machine learning (ML) and natural language processing (NLP) for configuration validation is considered a promising direction, but has been facing challenges such as the need of not only large-scale configuration data, but also system-specific features and models which are hard to generalize. Recent advances in Large Language Models (LLMs) show the promises to address some of the long-lasting limitations of ML/NLP-based configuration validation techniques. In this paper, we present an exploratory analysis on the feasibility and effectiveness of using LLMs like GPT and Codex for configuration validation. Specifically, we take a first step to empirically evaluate LLMs as configuration validators without additional fine-tuning or code generation. We develop a generic LLM-based validation framework, named Ciri, which integrates different LLMs. Ciri devises effective prompt engineering with few-shot learning based on both valid configuration and misconfiguration data. Ciri also validates and aggregates the outputs of LLMs to generate validation results, coping with known hallucination and nondeterminism of LLMs. We evaluate the validation effectiveness of Ciri on five popular LLMs using configuration data of six mature, widely deployed open-source systems. Our analysis (1) confirms the potential of using LLMs for configuration validation, (2) understands the design space of LLMbased validators like Ciri, especially in terms of prompt engineering with few-shot learning, and (3) reveals open challenges such as ineffectiveness in detecting certain types of misconfigurations and biases to popular configuration parameters.
Greedy Modality Selection via Approximate Submodular Maximization
Oct 22, 2022Multimodal learning considers learning from multi-modality data, aiming to fuse heterogeneous sources of information. However, it is not always feasible to leverage all available modalities due to memory constraints. Further, training on all the modalities may be inefficient when redundant information exists within data, such as different subsets of modalities providing similar performance. In light of these challenges, we study modality selection, intending to efficiently select the most informative and complementary modalities under certain computational constraints. We formulate a theoretical framework for optimizing modality selection in multimodal learning and introduce a utility measure to quantify the benefit of selecting a modality. For this optimization problem, we present efficient algorithms when the utility measure exhibits monotonicity and approximate submodularity. We also connect the utility measure with existing Shapley-value-based feature importance scores. Last, we demonstrate the efficacy of our algorithm on synthetic (Patch-MNIST) and two real-world (PEMS-SF, CMU-MOSI) datasets.
A Visual Attention Grounding Neural Model for Multimodal Machine Translation
Aug 28, 2018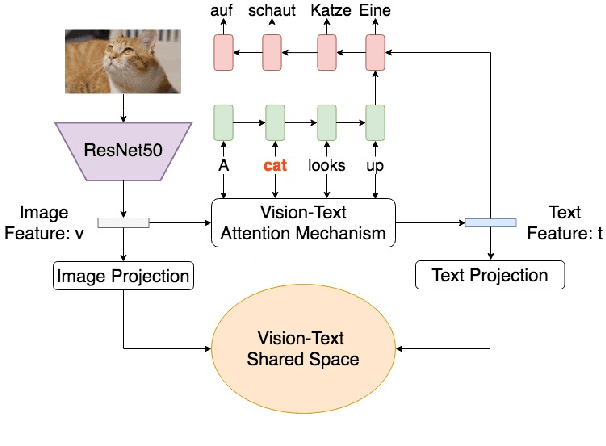



We introduce a novel multimodal machine translation model that utilizes parallel visual and textual information. Our model jointly optimizes the learning of a shared visual-language embedding and a translator. The model leverages a visual attention grounding mechanism that links the visual semantics with the corresponding textual semantics. Our approach achieves competitive state-of-the-art results on the Multi30K and the Ambiguous COCO datasets. We also collected a new multilingual multimodal product description dataset to simulate a real-world international online shopping scenario. On this dataset, our visual attention grounding model outperforms other methods by a large margin.