 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBenchmarking Practices in LLM-driven Offensive Security: Testbeds, Metrics, and Experiment Design
Apr 14, 2025Large Language Models (LLMs) have emerged as a powerful approach for driving offensive penetration-testing tooling. This paper analyzes the methodology and benchmarking practices used for evaluating Large Language Model (LLM)-driven attacks, focusing on offensive uses of LLMs in cybersecurity. We review 16 research papers detailing 15 prototypes and their respective testbeds. We detail our findings and provide actionable recommendations for future research, emphasizing the importance of extending existing testbeds, creating baselines, and including comprehensive metrics and qualitative analysis. We also note the distinction between security research and practice, suggesting that CTF-based challenges may not fully represent real-world penetration testing scenarios.
Agentic Bug Reproduction for Effective Automated Program Repair at Google
Feb 03, 2025



Bug reports often lack sufficient detail for developers to reproduce and fix the underlying defects. Bug Reproduction Tests (BRTs), tests that fail when the bug is present and pass when it has been resolved, are crucial for debugging, but they are rarely included in bug reports, both in open-source and in industrial settings. Thus, automatically generating BRTs from bug reports has the potential to accelerate the debugging process and lower time to repair. This paper investigates automated BRT generation within an industry setting, specifically at Google, focusing on the challenges of a large-scale, proprietary codebase and considering real-world industry bugs extracted from Google's internal issue tracker. We adapt and evaluate a state-of-the-art BRT generation technique, LIBRO, and present our agent-based approach, BRT Agent, which makes use of a fine-tuned Large Language Model (LLM) for code editing. Our BRT Agent significantly outperforms LIBRO, achieving a 28% plausible BRT generation rate, compared to 10% by LIBRO, on 80 human-reported bugs from Google's internal issue tracker. We further investigate the practical value of generated BRTs by integrating them with an Automated Program Repair (APR) system at Google. Our results show that providing BRTs to the APR system results in 30% more bugs with plausible fixes. Additionally, we introduce Ensemble Pass Rate (EPR), a metric which leverages the generated BRTs to select the most promising fixes from all fixes generated by APR system. Our evaluation on EPR for Top-K and threshold-based fix selections demonstrates promising results and trade-offs. For example, EPR correctly selects a plausible fix from a pool of 20 candidates in 70% of cases, based on its top-1 ranking.
Evaluating Agent-based Program Repair at Google
Jan 13, 2025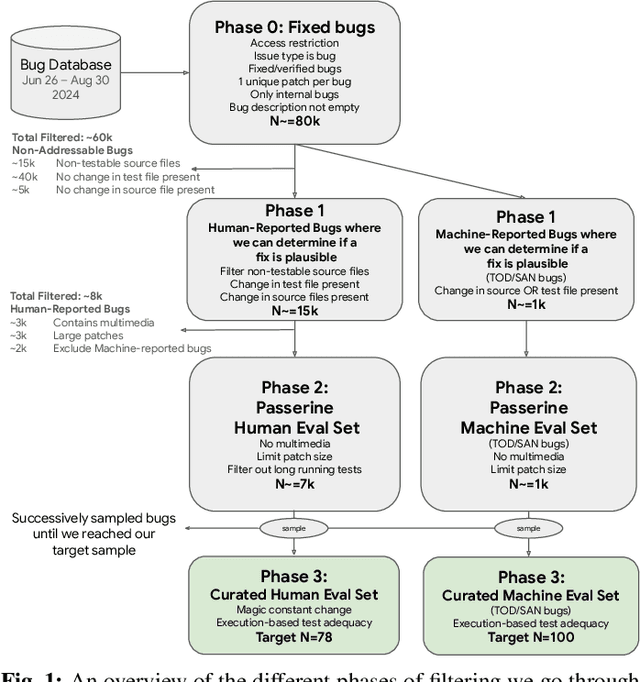



Agent-based program repair offers to automatically resolve complex bugs end-to-end by combining the planning, tool use, and code generation abilities of modern LLMs. Recent work has explored the use of agent-based repair approaches on the popular open-source SWE-Bench, a collection of bugs from highly-rated GitHub Python projects. In addition, various agentic approaches such as SWE-Agent have been proposed to solve bugs in this benchmark. This paper explores the viability of using an agentic approach to address bugs in an enterprise context. To investigate this, we curate an evaluation set of 178 bugs drawn from Google's issue tracking system. This dataset spans both human-reported (78) and machine-reported bugs (100). To establish a repair performance baseline on this benchmark, we implement Passerine, an agent similar in spirit to SWE-Agent that can work within Google's development environment. We show that with 20 trajectory samples and Gemini 1.5 Pro, Passerine can produce a patch that passes bug tests (i.e., plausible) for 73% of machine-reported and 25.6% of human-reported bugs in our evaluation set. After manual examination, we found that 43% of machine-reported bugs and 17.9% of human-reported bugs have at least one patch that is semantically equivalent to the ground-truth patch. These results establish a baseline on an industrially relevant benchmark, which as we show, contains bugs drawn from a different distribution -- in terms of language diversity, size, and spread of changes, etc. -- compared to those in the popular SWE-Bench dataset.
Evaluating LLMs for Privilege-Escalation Scenarios
Oct 23, 2023Penetration testing, an essential component of cybersecurity, allows organizations to proactively identify and remediate vulnerabilities in their systems, thus bolstering their defense mechanisms against potential cyberattacks. One recent advancement in the realm of penetration testing is the utilization of Language Models (LLMs). We explore the intersection of LLMs and penetration testing to gain insight into their capabilities and challenges in the context of privilige escalation. We create an automated Linux privilege-escalation benchmark utilizing local virtual machines. We introduce an LLM-guided privilege-escalation tool designed for evaluating different LLMs and prompt strategies against our benchmark. We analyze the impact of different prompt designs, the benefits of in-context learning, and the advantages of offering high-level guidance to LLMs. We discuss challenging areas for LLMs, including maintaining focus during testing, coping with errors, and finally comparing them with both stochastic parrots as well as with human hackers.
Getting pwn'd by AI: Penetration Testing with Large Language Models
Aug 17, 2023The field of software security testing, more specifically penetration testing, is an activity that requires high levels of expertise and involves many manual testing and analysis steps. This paper explores the potential usage of large-language models, such as GPT3.5, to augment penetration testers with AI sparring partners. We explore the feasibility of supplementing penetration testers with AI models for two distinct use cases: high-level task planning for security testing assignments and low-level vulnerability hunting within a vulnerable virtual machine. For the latter, we implemented a closed-feedback loop between LLM-generated low-level actions with a vulnerable virtual machine (connected through SSH) and allowed the LLM to analyze the machine state for vulnerabilities and suggest concrete attack vectors which were automatically executed within the virtual machine. We discuss promising initial results, detail avenues for improvement, and close deliberating on the ethics of providing AI-based sparring partners.
Learning to Learn to Predict Performance Regressions in Production at Meta
Aug 08, 2022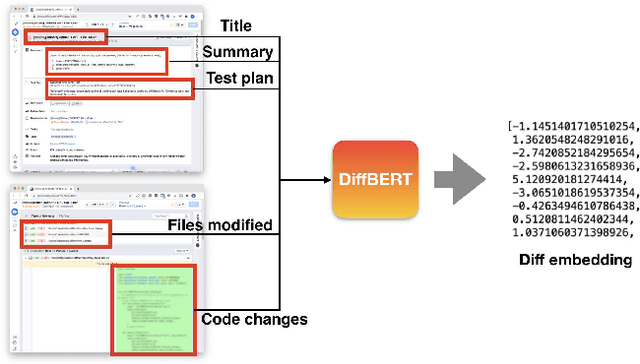
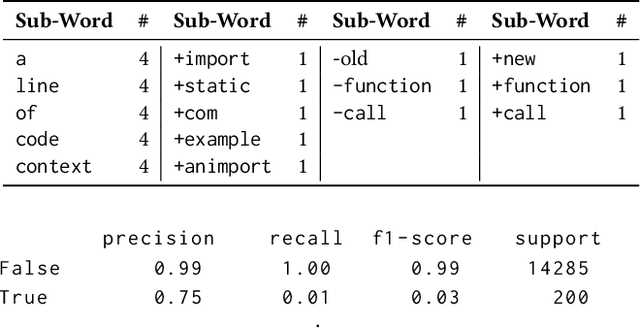
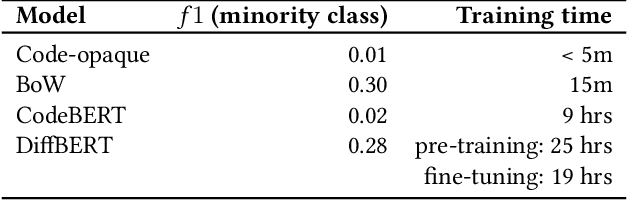
Catching and attributing code change-induced performance regressions in production is hard; predicting them beforehand, even harder. A primer on automatically learning to predict performance regressions in software, this article gives an account of the experiences we gained when researching and deploying an ML-based regression prediction pipeline at Meta. In this paper, we report on a comparative study with four ML models of increasing complexity, from (1) code-opaque, over (2) Bag of Words, (3) off-the-shelve Transformer-based, to (4) a bespoke Transformer-based model, coined SuperPerforator. Our investigation shows the inherent difficulty of the performance prediction problem, which is characterized by a large imbalance of benign onto regressing changes. Our results also call into question the general applicability of Transformer-based architectures for performance prediction: an off-the-shelve CodeBERT-based approach had surprisingly poor performance; our highly customized SuperPerforator architecture initially achieved prediction performance that was just on par with simpler Bag of Words models, and only outperformed them for down-stream use cases. This ability of SuperPerforator to transfer to an application with few learning examples afforded an opportunity to deploy it in practice at Meta: it can act as a pre-filter to sort out changes that are unlikely to introduce a regression, truncating the space of changes to search a regression in by up to 43%, a 45x improvement over a random baseline. To gain further insight into SuperPerforator, we explored it via a series of experiments computing counterfactual explanations. These highlight which parts of a code change the model deems important, thereby validating the learned black-box model.
Counterfactual Explanations for Models of Code
Nov 10, 2021

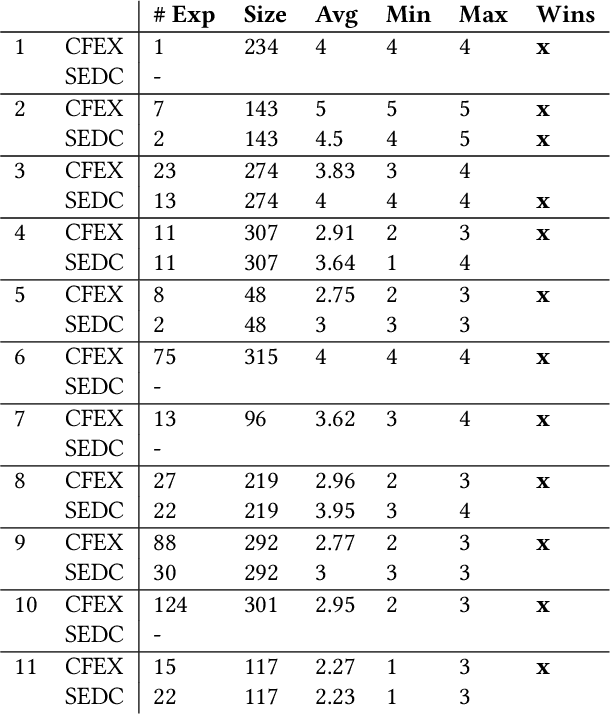
Machine learning (ML) models play an increasingly prevalent role in many software engineering tasks. However, because most models are now powered by opaque deep neural networks, it can be difficult for developers to understand why the model came to a certain conclusion and how to act upon the model's prediction. Motivated by this problem, this paper explores counterfactual explanations for models of source code. Such counterfactual explanations constitute minimal changes to the source code under which the model "changes its mind". We integrate counterfactual explanation generation to models of source code in a real-world setting. We describe considerations that impact both the ability to find realistic and plausible counterfactual explanations, as well as the usefulness of such explanation to the user of the model. In a series of experiments we investigate the efficacy of our approach on three different models, each based on a BERT-like architecture operating over source code.
Enabling collaborative data science development with the Ballet framework
Dec 14, 2020


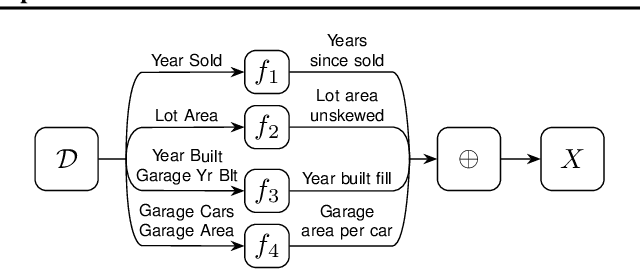
While the open-source model for software development has led to successful large-scale collaborations in building software systems, data science projects are frequently developed by individuals or small groups. We describe challenges to scaling data science collaborations and present a novel ML programming model to address them. We instantiate these ideas in Ballet, a lightweight software framework for collaborative open-source data science and a cloud-based development environment, with a plugin for collaborative feature engineering. Using our framework, collaborators incrementally propose feature definitions to a repository which are each subjected to an ML evaluation and can be automatically merged into an executable feature engineering pipeline. We leverage Ballet to conduct an extensive case study analysis of a real-world income prediction problem, and discuss implications for collaborative projects.