 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning to Learn to Predict Performance Regressions in Production at Meta
Paper and Code
Aug 08, 2022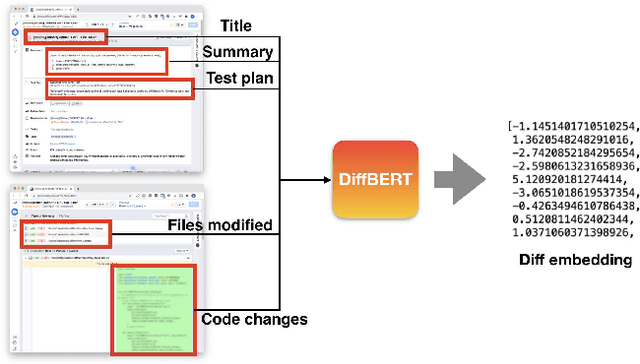
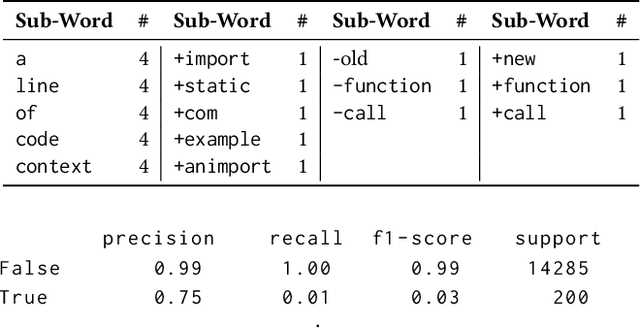
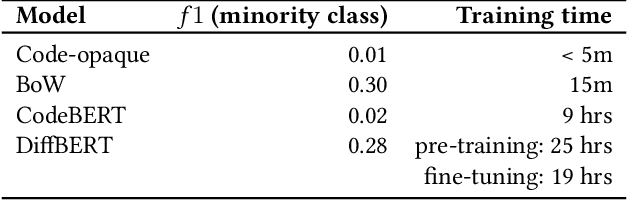
Catching and attributing code change-induced performance regressions in production is hard; predicting them beforehand, even harder. A primer on automatically learning to predict performance regressions in software, this article gives an account of the experiences we gained when researching and deploying an ML-based regression prediction pipeline at Meta. In this paper, we report on a comparative study with four ML models of increasing complexity, from (1) code-opaque, over (2) Bag of Words, (3) off-the-shelve Transformer-based, to (4) a bespoke Transformer-based model, coined SuperPerforator. Our investigation shows the inherent difficulty of the performance prediction problem, which is characterized by a large imbalance of benign onto regressing changes. Our results also call into question the general applicability of Transformer-based architectures for performance prediction: an off-the-shelve CodeBERT-based approach had surprisingly poor performance; our highly customized SuperPerforator architecture initially achieved prediction performance that was just on par with simpler Bag of Words models, and only outperformed them for down-stream use cases. This ability of SuperPerforator to transfer to an application with few learning examples afforded an opportunity to deploy it in practice at Meta: it can act as a pre-filter to sort out changes that are unlikely to introduce a regression, truncating the space of changes to search a regression in by up to 43%, a 45x improvement over a random baseline. To gain further insight into SuperPerforator, we explored it via a series of experiments computing counterfactual explanations. These highlight which parts of a code change the model deems important, thereby validating the learned black-box model.