 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeProdCodeBench: A Production-Derived Benchmark for Evaluating AI Coding Agents
Apr 02, 2026Benchmarks that reflect production workloads are better for evaluating AI coding agents in industrial settings, yet existing benchmarks differ from real usage in programming language distribution, prompt style and codebase structure. This paper presents a methodology for curating production-derived benchmarks, illustrated through ProdCodeBench - a benchmark built from real sessions with a production AI coding assistant. We detail our data collection and curation practices including LLM-based task classification, test relevance validation, and multi-run stability checks which address challenges in constructing reliable evaluation signals from monorepo environments. Each curated sample consists of a verbatim prompt, a committed code change and fail-to-pass tests spanning seven programming languages. Our systematic analysis of four foundation models yields solve rates from 53.2% to 72.2% revealing that models making greater use of work validation tools, such as executing tests and invoking static analysis, achieve higher solve rates. This suggests that iterative verification helps achieve effective agent behavior and that exposing codebase-specific verification mechanisms may significantly improve the performance of externally trained agents operating in unfamiliar environments. We share our methodology and lessons learned to enable other organizations to construct similar production-derived benchmarks.
AI-Assisted Fixes to Code Review Comments at Scale
Jul 17, 2025Aim. There are 10s of thousands of code review comments each week at Meta. We developed Metamate for Code Review (MetaMateCR) that provides AI-assisted fixes for reviewer comments in production at scale. Method. We developed an internal benchmark of 64k <review comment, patch> data points to fine-tune Llama models. Once our models achieve reasonable offline results, we roll them into production. To ensure that our AI-assisted fixes do not negatively impact the time it takes to do code reviews, we conduct randomized controlled safety trials as well as full production experiments. Offline Results. As a baseline, we compare GPT-4o to our small and large Llama models. In offline results, our LargeLSFT model creates an exact match patch 68% of the time outperforming GPT-4o by 9 percentage points (pp). The internal models also use more modern Hack functions when compared to the PHP functions suggested by GPT-4o. Safety Trial. When we roll MetaMateCR into production in a safety trial that compares no AI patches with AI patch suggestions, we see a large regression with reviewers taking over 5% longer to conduct reviews. After investigation, we modify the UX to only show authors the AI patches, and see no regressions in the time for reviews. Production. When we roll LargeLSFT into production, we see an ActionableToApplied rate of 19.7%, which is a 9.2pp improvement over GPT-4o. Our results illustrate the importance of safety trials in ensuring that AI does not inadvertently slow down engineers, and a successful review comment to AI patch product running at scale.
Multi-line AI-assisted Code Authoring
Feb 06, 2024
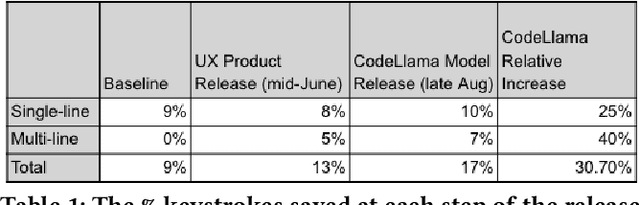

CodeCompose is an AI-assisted code authoring tool powered by large language models (LLMs) that provides inline suggestions to 10's of thousands of developers at Meta. In this paper, we present how we scaled the product from displaying single-line suggestions to multi-line suggestions. This evolution required us to overcome several unique challenges in improving the usability of these suggestions for developers. First, we discuss how multi-line suggestions can have a 'jarring' effect, as the LLM's suggestions constantly move around the developer's existing code, which would otherwise result in decreased productivity and satisfaction. Second, multi-line suggestions take significantly longer to generate; hence we present several innovative investments we made to reduce the perceived latency for users. These model-hosting optimizations sped up multi-line suggestion latency by 2.5x. Finally, we conduct experiments on 10's of thousands of engineers to understand how multi-line suggestions impact the user experience and contrast this with single-line suggestions. Our experiments reveal that (i) multi-line suggestions account for 42% of total characters accepted (despite only accounting for 16% for displayed suggestions) (ii) multi-line suggestions almost doubled the percentage of keystrokes saved for users from 9% to 17%. Multi-line CodeCompose has been rolled out to all engineers at Meta, and less than 1% of engineers have opted out of multi-line suggestions.
CodeCompose: A Large-Scale Industrial Deployment of AI-assisted Code Authoring
May 20, 2023



The rise of large language models (LLMs) has unlocked various applications of this technology in software development. In particular, generative LLMs have been shown to effectively power AI-based code authoring tools that can suggest entire statements or blocks of code during code authoring. In this paper we present CodeCompose, an AI-assisted code authoring tool developed and deployed at Meta internally. CodeCompose is based on the InCoder LLM that merges generative capabilities with bi-directionality. We have scaled up CodeCompose to serve tens of thousands of developers at Meta, across 10+ programming languages and several coding surfaces. We discuss unique challenges in terms of user experience and metrics that arise when deploying such tools in large-scale industrial settings. We present our experience in making design decisions about the model and system architecture for CodeCompose that addresses these challenges. Finally, we present metrics from our large-scale deployment of CodeCompose that shows its impact on Meta's internal code authoring experience over a 15-day time window, where 4.5 million suggestions were made by CodeCompose. Quantitative metrics reveal that (i) CodeCompose has an acceptance rate of 22% across several languages, and (ii) 8% of the code typed by users of CodeCompose is through accepting code suggestions from CodeCompose. Qualitative feedback indicates an overwhelming 91.5% positive reception for CodeCompose. In addition to assisting with code authoring, CodeCompose is also introducing other positive side effects such as encouraging developers to generate more in-code documentation, helping them with the discovery of new APIs, etc.
Learning to Learn to Predict Performance Regressions in Production at Meta
Aug 08, 2022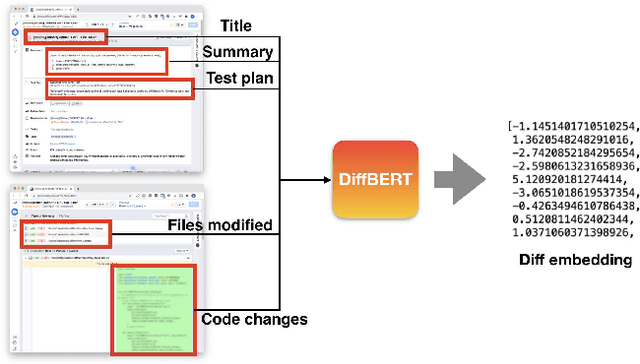
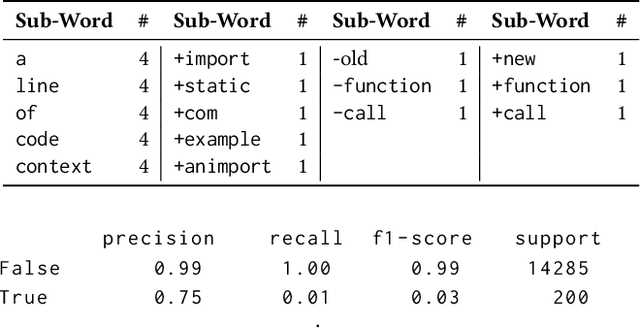
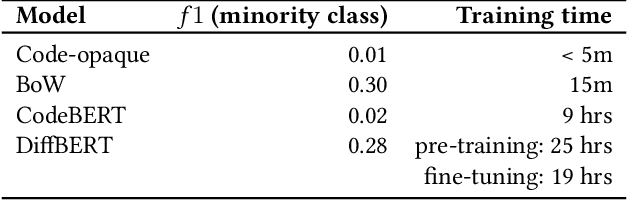
Catching and attributing code change-induced performance regressions in production is hard; predicting them beforehand, even harder. A primer on automatically learning to predict performance regressions in software, this article gives an account of the experiences we gained when researching and deploying an ML-based regression prediction pipeline at Meta. In this paper, we report on a comparative study with four ML models of increasing complexity, from (1) code-opaque, over (2) Bag of Words, (3) off-the-shelve Transformer-based, to (4) a bespoke Transformer-based model, coined SuperPerforator. Our investigation shows the inherent difficulty of the performance prediction problem, which is characterized by a large imbalance of benign onto regressing changes. Our results also call into question the general applicability of Transformer-based architectures for performance prediction: an off-the-shelve CodeBERT-based approach had surprisingly poor performance; our highly customized SuperPerforator architecture initially achieved prediction performance that was just on par with simpler Bag of Words models, and only outperformed them for down-stream use cases. This ability of SuperPerforator to transfer to an application with few learning examples afforded an opportunity to deploy it in practice at Meta: it can act as a pre-filter to sort out changes that are unlikely to introduce a regression, truncating the space of changes to search a regression in by up to 43%, a 45x improvement over a random baseline. To gain further insight into SuperPerforator, we explored it via a series of experiments computing counterfactual explanations. These highlight which parts of a code change the model deems important, thereby validating the learned black-box model.
Counterfactual Explanations for Models of Code
Nov 10, 2021

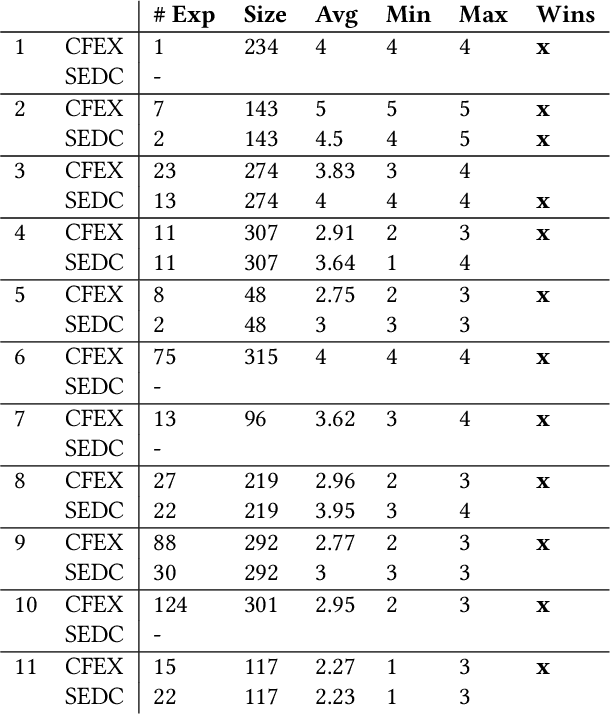
Machine learning (ML) models play an increasingly prevalent role in many software engineering tasks. However, because most models are now powered by opaque deep neural networks, it can be difficult for developers to understand why the model came to a certain conclusion and how to act upon the model's prediction. Motivated by this problem, this paper explores counterfactual explanations for models of source code. Such counterfactual explanations constitute minimal changes to the source code under which the model "changes its mind". We integrate counterfactual explanation generation to models of source code in a real-world setting. We describe considerations that impact both the ability to find realistic and plausible counterfactual explanations, as well as the usefulness of such explanation to the user of the model. In a series of experiments we investigate the efficacy of our approach on three different models, each based on a BERT-like architecture operating over source code.
Improving Code Autocompletion with Transfer Learning
May 12, 2021
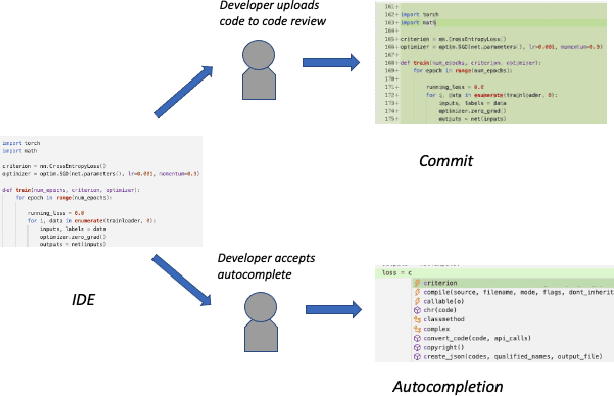
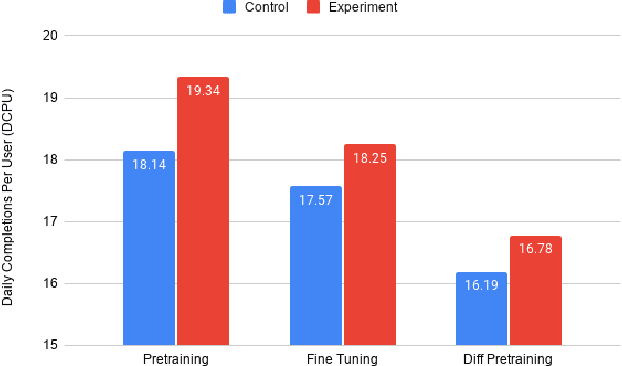
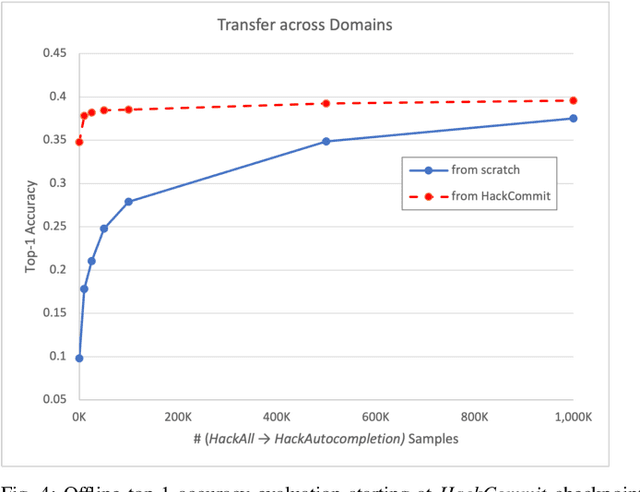
Software language models have achieved promising results predicting code completion usages, and several industry studies have described successful IDE integrations. Recently, accuracy in autocompletion prediction improved 12.8% from training on a real-world dataset collected from programmers' IDE activity. But what if limited examples of IDE autocompletion in the target programming language are available for model training? In this paper, we investigate the efficacy of pretraining autocompletion models on non-IDE, non-autocompletion, and different-language example code sequences. We find that these unsupervised pretrainings improve model accuracy by over 50% on very small fine-tuning datasets and over 10% on 50k labeled examples. We confirm the real-world impact of these pretrainings in an online setting through A/B testing on thousands of IDE autocompletion users, finding that pretraining is responsible for increases of up to 6.63% autocompletion usage.
Programmatically Interpretable Reinforcement Learning
Jun 08, 2018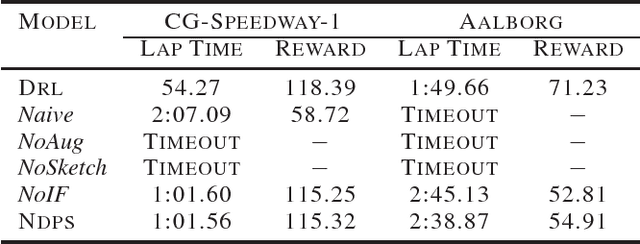


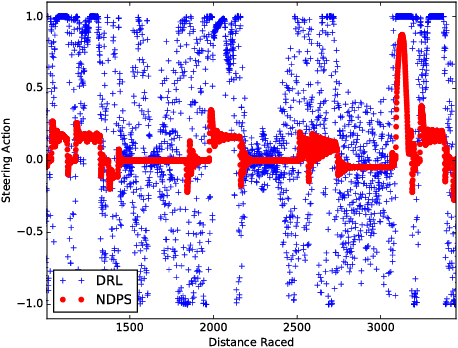
We present a reinforcement learning framework, called Programmatically Interpretable Reinforcement Learning (PIRL), that is designed to generate interpretable and verifiable agent policies. Unlike the popular Deep Reinforcement Learning (DRL) paradigm, which represents policies by neural networks, PIRL represents policies using a high-level, domain-specific programming language. Such programmatic policies have the benefits of being more easily interpreted than neural networks, and being amenable to verification by symbolic methods. We propose a new method, called Neurally Directed Program Search (NDPS), for solving the challenging nonsmooth optimization problem of finding a programmatic policy with maximal reward. NDPS works by first learning a neural policy network using DRL, and then performing a local search over programmatic policies that seeks to minimize a distance from this neural "oracle". We evaluate NDPS on the task of learning to drive a simulated car in the TORCS car-racing environment. We demonstrate that NDPS is able to discover human-readable policies that pass some significant performance bars. We also show that PIRL policies can have smoother trajectories, and can be more easily transferred to environments not encountered during training, than corresponding policies discovered by DRL.
Neural Sketch Learning for Conditional Program Generation
Apr 12, 2018
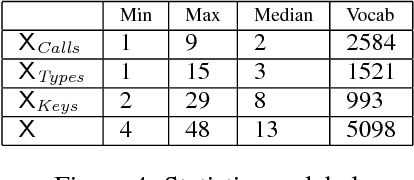
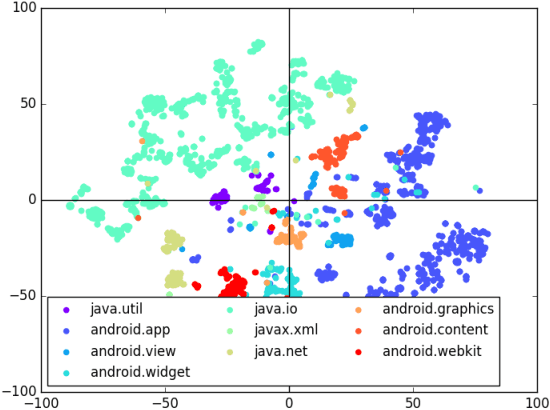
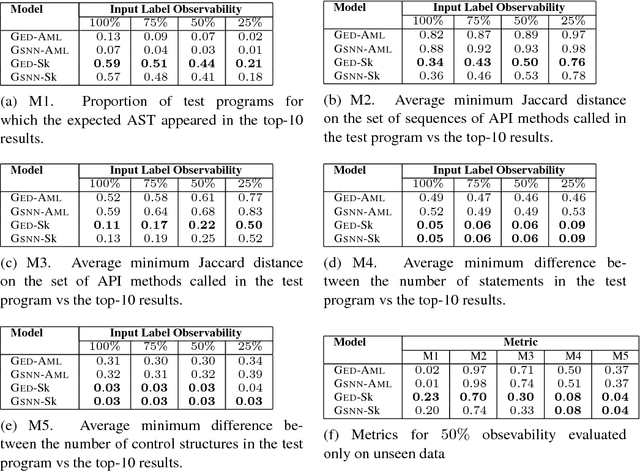
We study the problem of generating source code in a strongly typed, Java-like programming language, given a label (for example a set of API calls or types) carrying a small amount of information about the code that is desired. The generated programs are expected to respect a "realistic" relationship between programs and labels, as exemplified by a corpus of labeled programs available during training. Two challenges in such conditional program generation are that the generated programs must satisfy a rich set of syntactic and semantic constraints, and that source code contains many low-level features that impede learning. We address these problems by training a neural generator not on code but on program sketches, or models of program syntax that abstract out names and operations that do not generalize across programs. During generation, we infer a posterior distribution over sketches, then concretize samples from this distribution into type-safe programs using combinatorial techniques. We implement our ideas in a system for generating API-heavy Java code, and show that it can often predict the entire body of a method given just a few API calls or data types that appear in the method.