 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeImproving Code Autocompletion with Transfer Learning
Paper and Code
May 12, 2021
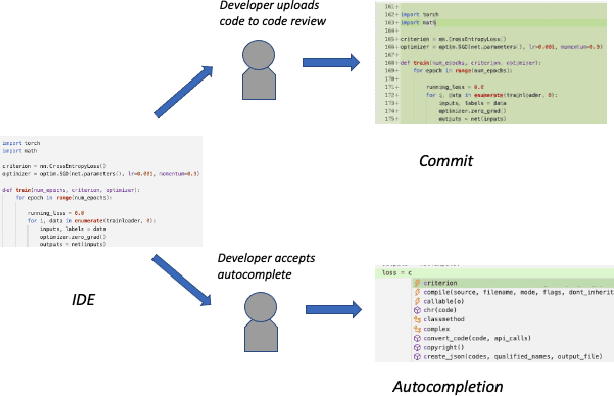
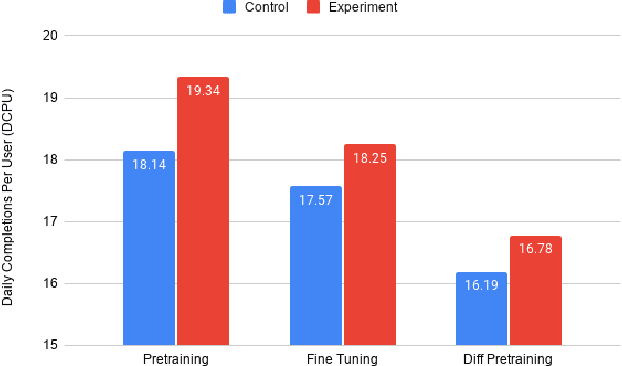
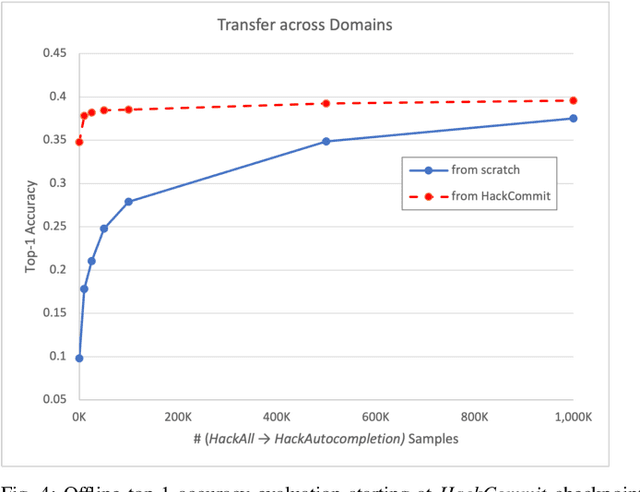
Software language models have achieved promising results predicting code completion usages, and several industry studies have described successful IDE integrations. Recently, accuracy in autocompletion prediction improved 12.8% from training on a real-world dataset collected from programmers' IDE activity. But what if limited examples of IDE autocompletion in the target programming language are available for model training? In this paper, we investigate the efficacy of pretraining autocompletion models on non-IDE, non-autocompletion, and different-language example code sequences. We find that these unsupervised pretrainings improve model accuracy by over 50% on very small fine-tuning datasets and over 10% on 50k labeled examples. We confirm the real-world impact of these pretrainings in an online setting through A/B testing on thousands of IDE autocompletion users, finding that pretraining is responsible for increases of up to 6.63% autocompletion usage.