 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeImproving Code Autocompletion with Transfer Learning
May 12, 2021
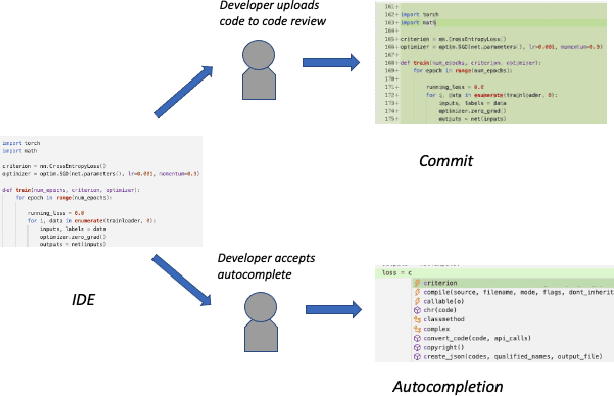
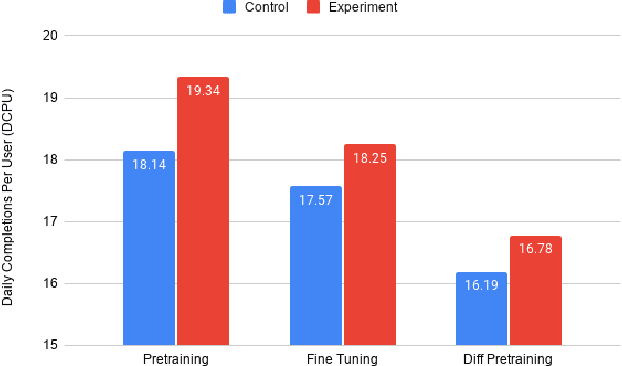
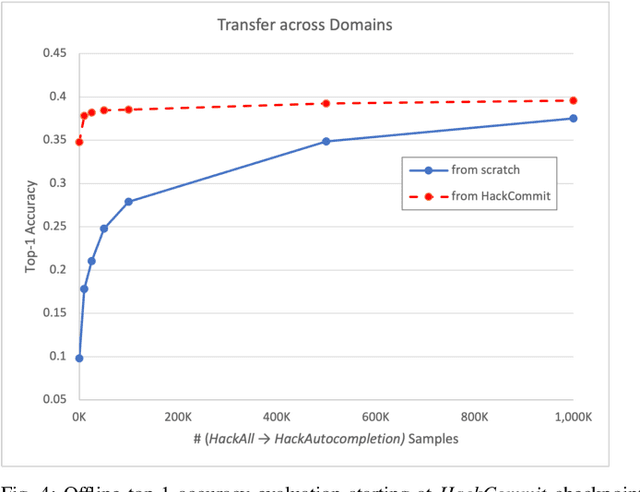
Software language models have achieved promising results predicting code completion usages, and several industry studies have described successful IDE integrations. Recently, accuracy in autocompletion prediction improved 12.8% from training on a real-world dataset collected from programmers' IDE activity. But what if limited examples of IDE autocompletion in the target programming language are available for model training? In this paper, we investigate the efficacy of pretraining autocompletion models on non-IDE, non-autocompletion, and different-language example code sequences. We find that these unsupervised pretrainings improve model accuracy by over 50% on very small fine-tuning datasets and over 10% on 50k labeled examples. We confirm the real-world impact of these pretrainings in an online setting through A/B testing on thousands of IDE autocompletion users, finding that pretraining is responsible for increases of up to 6.63% autocompletion usage.
Rotation-Invariant Local-to-Global Representation Learning for 3D Point Cloud
Oct 23, 2020

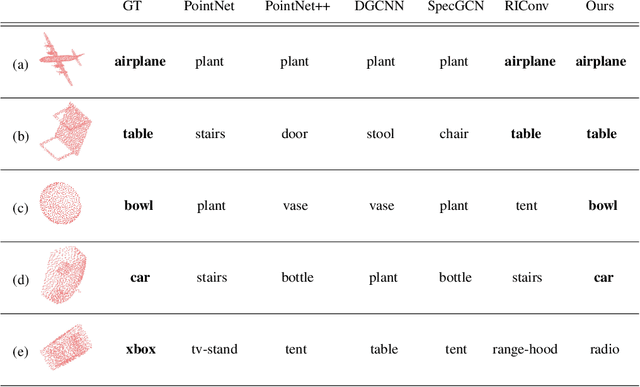
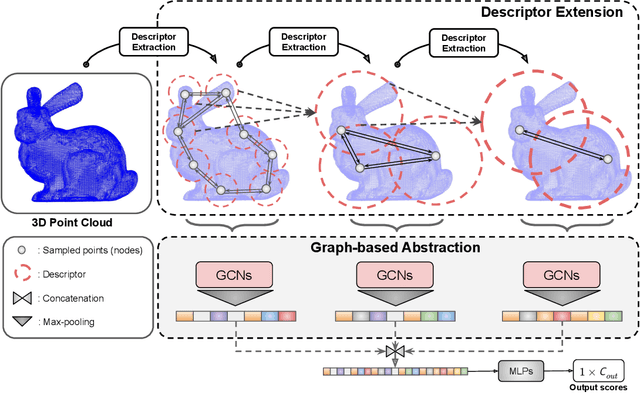
We propose a local-to-global representation learning algorithm for 3D point cloud data, which is appropriate to handle various geometric transformations, especially rotation, without explicit data augmentation with respect to the transformations. Our model takes advantage of multi-level abstraction based on graph convolutional neural networks, which constructs a descriptor hierarchy to encode rotation-invariant shape information of an input object in a bottom-up manner. The descriptors in each level are obtained from a neural network based on a graph via stochastic sampling of 3D points, which is effective in making the learned representations robust to the variations of input data. The proposed algorithm presents the state-of-the-art performance on the rotation-augmented 3D object recognition and segmentation benchmarks, and we further analyze its characteristics through comprehensive ablative experiments.
Weakly Supervised Instance Segmentation by Deep Community Learning
Mar 06, 2020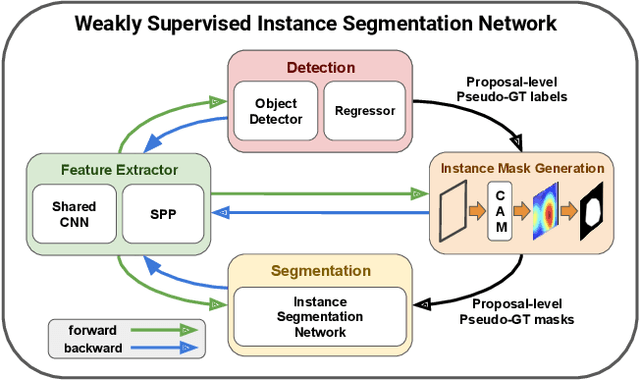
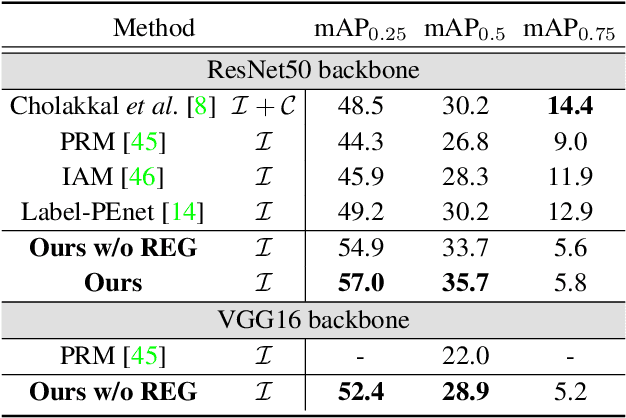
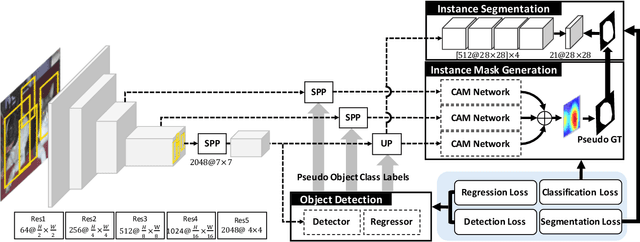
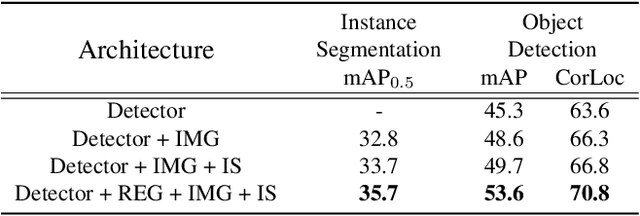
We present a weakly supervised instance segmentation algorithm based on deep community learning with multiple tasks. This task is formulated as a combination of weakly supervised object detection and semantic segmentation, where individual objects of the same class are identified and segmented separately. We address this problem by designing a unified deep neural network architecture, which has a positive feedback loop of object detection with bounding box regression, instance mask generation, instance segmentation, and feature extraction. Each component of the network makes active interactions with others to improve accuracy, and the end-to-end trainability of our model makes our results more robust and reproducible. The proposed algorithm achieves state-of-the-art performance in the weakly supervised setting without any additional training such as Fast R-CNN and Mask R-CNN on the standard benchmark dataset.
When Deep Learning Met Code Search
May 09, 2019

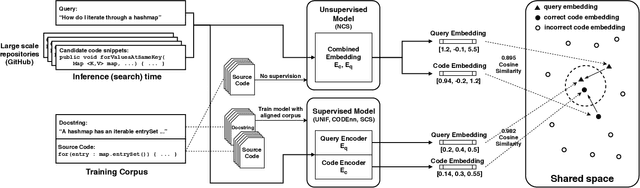
There have been multiple recent proposals on using deep neural networks for code search using natural language. Common across these proposals is the idea of $\mathit{embedding}$ code and natural language queries, into real vectors and then using vector distance to approximate semantic correlation between code and the query. Multiple approaches exist for learning these embeddings, including $\mathit{unsupervised}$ techniques, which rely only on a corpus of code examples, and $\mathit{supervised}$ techniques, which use an $\mathit{aligned}$ corpus of paired code and natural language descriptions. The goal of this supervision is to produce embeddings that are more similar for a query and the corresponding desired code snippet. Clearly, there are choices in whether to use supervised techniques at all, and if one does, what sort of network and training to use for supervision. This paper is the first to evaluate these choices systematically. To this end, we assembled implementations of state-of-the-art techniques to run on a common platform, training and evaluation corpora. To explore the design space in network complexity, we also introduced a new design point that is a $\mathit{minimal}$ supervision extension to an existing unsupervised technique. Our evaluation shows that: 1. adding supervision to an existing unsupervised technique can improve performance, though not necessarily by much; 2. simple networks for supervision can be more effective that more sophisticated sequence-based networks for code search; 3. while it is common to use docstrings to carry out supervision, there is a sizeable gap between the effectiveness of docstrings and a more query-appropriate supervision corpus.