 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEmergence of Text Readability in Vision Language Models
Jun 24, 2025We investigate how the ability to recognize textual content within images emerges during the training of Vision-Language Models (VLMs). Our analysis reveals a critical phenomenon: the ability to read textual information in a given image \textbf{(text readability)} emerges abruptly after substantial training iterations, in contrast to semantic content understanding which develops gradually from the early stages of training. This delayed emergence may reflect how contrastive learning tends to initially prioritize general semantic understanding, with text-specific symbolic processing developing later. Interestingly, the ability to match images with rendered text develops even slower, indicating a deeper need for semantic integration. These findings highlight the need for tailored training strategies to accelerate robust text comprehension in VLMs, laying the groundwork for future research on optimizing multimodal learning.
Hierarchical Visual Feature Aggregation for OCR-Free Document Understanding
Nov 08, 2024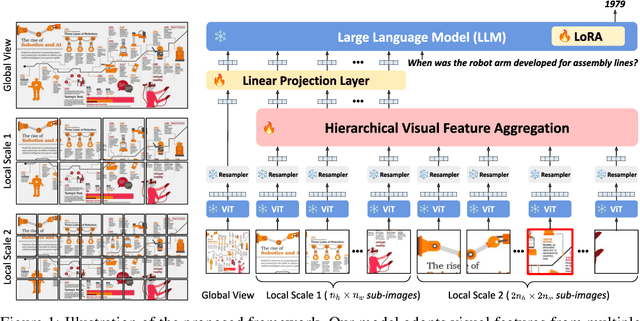

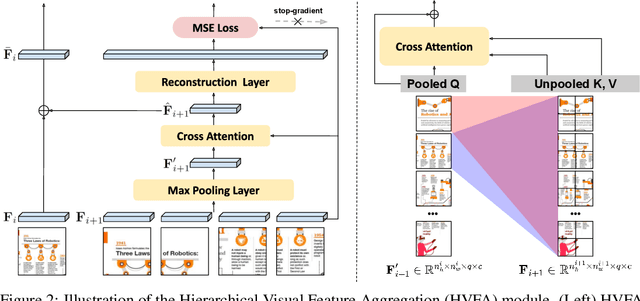
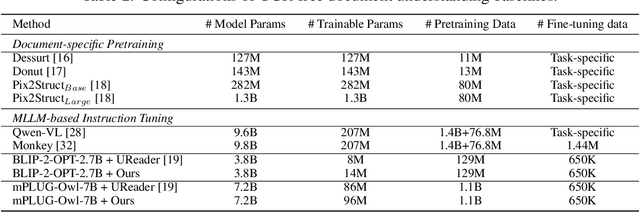
We present a novel OCR-free document understanding framework based on pretrained Multimodal Large Language Models (MLLMs). Our approach employs multi-scale visual features to effectively handle various font sizes within document images. To address the increasing costs of considering the multi-scale visual inputs for MLLMs, we propose the Hierarchical Visual Feature Aggregation (HVFA) module, designed to reduce the number of input tokens to LLMs. Leveraging a feature pyramid with cross-attentive pooling, our approach effectively manages the trade-off between information loss and efficiency without being affected by varying document image sizes. Furthermore, we introduce a novel instruction tuning task, which facilitates the model's text-reading capability by learning to predict the relative positions of input text, eventually minimizing the risk of truncated text caused by the limited capacity of LLMs. Comprehensive experiments validate the effectiveness of our approach, demonstrating superior performance in various document understanding tasks.
Cross-Class Feature Augmentation for Class Incremental Learning
Apr 04, 2023



We propose a novel class incremental learning approach by incorporating a feature augmentation technique motivated by adversarial attacks. We employ a classifier learned in the past to complement training examples rather than simply play a role as a teacher for knowledge distillation towards subsequent models. The proposed approach has a unique perspective to utilize the previous knowledge in class incremental learning since it augments features of arbitrary target classes using examples in other classes via adversarial attacks on a previously learned classifier. By allowing the cross-class feature augmentations, each class in the old tasks conveniently populates samples in the feature space, which alleviates the collapse of the decision boundaries caused by sample deficiency for the previous tasks, especially when the number of stored exemplars is small. This idea can be easily incorporated into existing class incremental learning algorithms without any architecture modification. Extensive experiments on the standard benchmarks show that our method consistently outperforms existing class incremental learning methods by significant margins in various scenarios, especially under an environment with an extremely limited memory budget.
Multi-Modal Representation Learning with Text-Driven Soft Masks
Apr 03, 2023



We propose a visual-linguistic representation learning approach within a self-supervised learning framework by introducing a new operation, loss, and data augmentation strategy. First, we generate diverse features for the image-text matching (ITM) task via soft-masking the regions in an image, which are most relevant to a certain word in the corresponding caption, instead of completely removing them. Since our framework relies only on image-caption pairs with no fine-grained annotations, we identify the relevant regions to each word by computing the word-conditional visual attention using multi-modal encoder. Second, we encourage the model to focus more on hard but diverse examples by proposing a focal loss for the image-text contrastive learning (ITC) objective, which alleviates the inherent limitations of overfitting and bias issues. Last, we perform multi-modal data augmentations for self-supervised learning via mining various examples by masking texts and rendering distortions on images. We show that the combination of these three innovations is effective for learning a pretrained model, leading to outstanding performance on multiple vision-language downstream tasks.
Class-Incremental Learning by Knowledge Distillation with Adaptive Feature Consolidation
Apr 02, 2022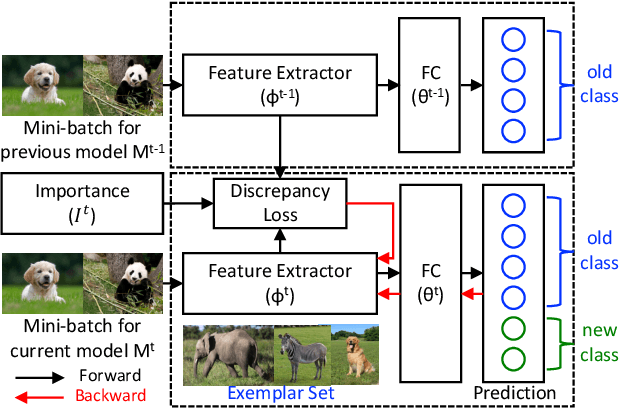
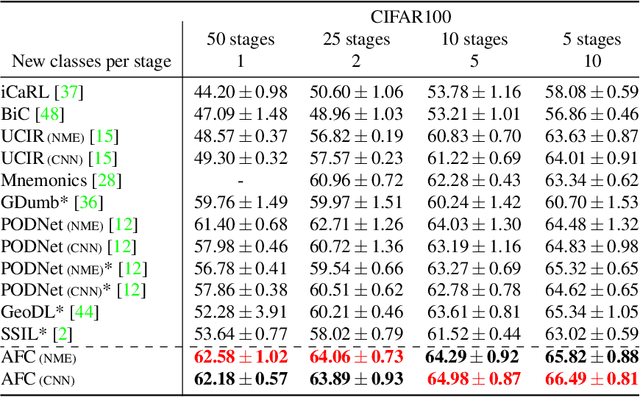
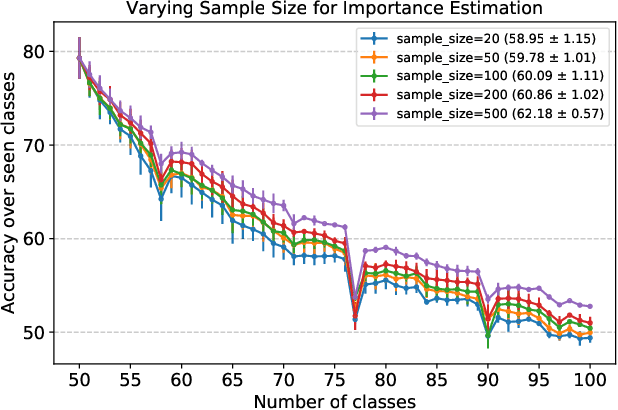
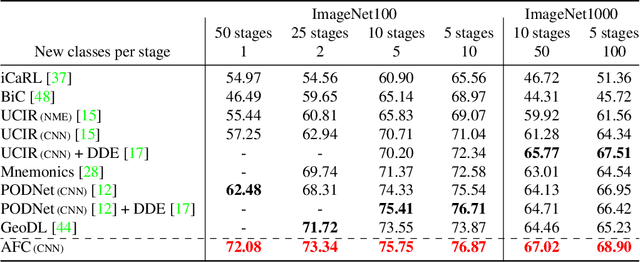
We present a novel class incremental learning approach based on deep neural networks, which continually learns new tasks with limited memory for storing examples in the previous tasks. Our algorithm is based on knowledge distillation and provides a principled way to maintain the representations of old models while adjusting to new tasks effectively. The proposed method estimates the relationship between the representation changes and the resulting loss increases incurred by model updates. It minimizes the upper bound of the loss increases using the representations, which exploits the estimated importance of each feature map within a backbone model. Based on the importance, the model restricts updates of important features for robustness while allowing changes in less critical features for flexibility. This optimization strategy effectively alleviates the notorious catastrophic forgetting problem despite the limited accessibility of data in the previous tasks. The experimental results show significant accuracy improvement of the proposed algorithm over the existing methods on the standard datasets. Code is available.
Class-Incremental Learning for Action Recognition in Videos
Mar 25, 2022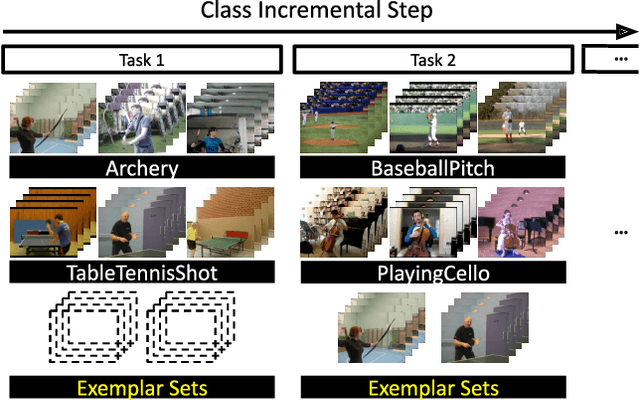
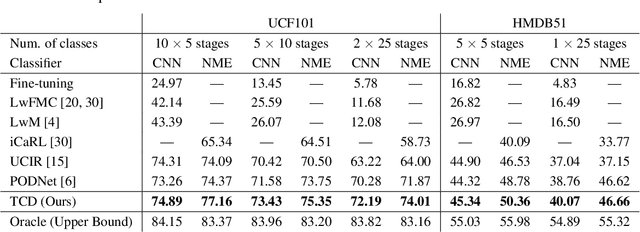

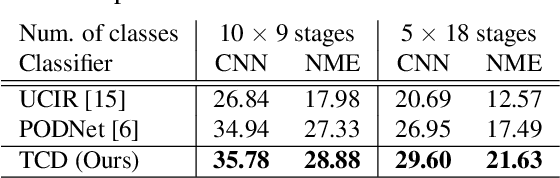
We tackle catastrophic forgetting problem in the context of class-incremental learning for video recognition, which has not been explored actively despite the popularity of continual learning. Our framework addresses this challenging task by introducing time-channel importance maps and exploiting the importance maps for learning the representations of incoming examples via knowledge distillation. We also incorporate a regularization scheme in our objective function, which encourages individual features obtained from different time steps in a video to be uncorrelated and eventually improves accuracy by alleviating catastrophic forgetting. We evaluate the proposed approach on brand-new splits of class-incremental action recognition benchmarks constructed upon the UCF101, HMDB51, and Something-Something V2 datasets, and demonstrate the effectiveness of our algorithm in comparison to the existing continual learning methods that are originally designed for image data.
Learning to Adapt to Unseen Abnormal Activities under Weak Supervision
Mar 25, 2022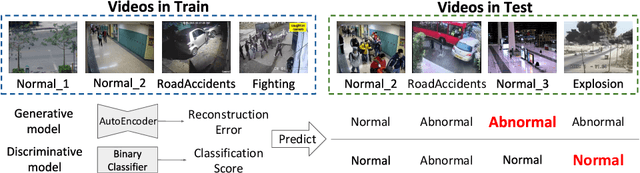

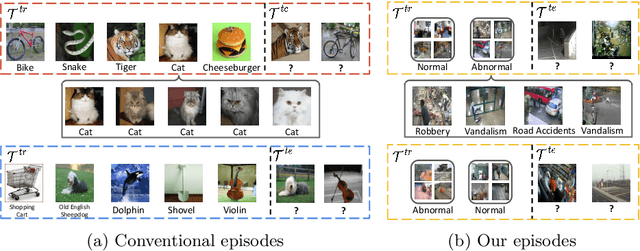
We present a meta-learning framework for weakly supervised anomaly detection in videos, where the detector learns to adapt to unseen types of abnormal activities effectively when only video-level annotations of binary labels are available. Our work is motivated by the fact that existing methods suffer from poor generalization to diverse unseen examples. We claim that an anomaly detector equipped with a meta-learning scheme alleviates the limitation by leading the model to an initialization point for better optimization. We evaluate the performance of our framework on two challenging datasets, UCF-Crime and ShanghaiTech. The experimental results demonstrate that our algorithm boosts the capability to localize unseen abnormal events in a weakly supervised setting. Besides the technical contributions, we perform the annotation of missing labels in the UCF-Crime dataset and make our task evaluated effectively.
Rotation-Invariant Local-to-Global Representation Learning for 3D Point Cloud
Oct 23, 2020

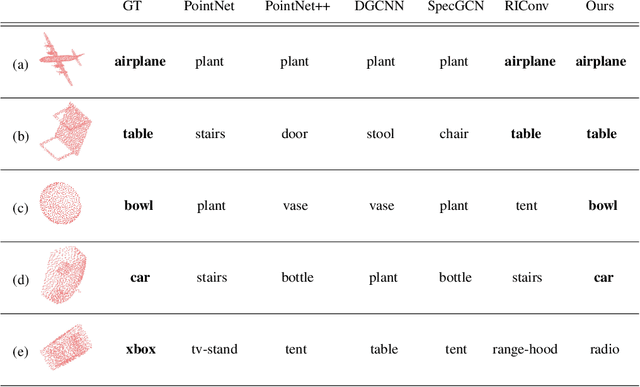
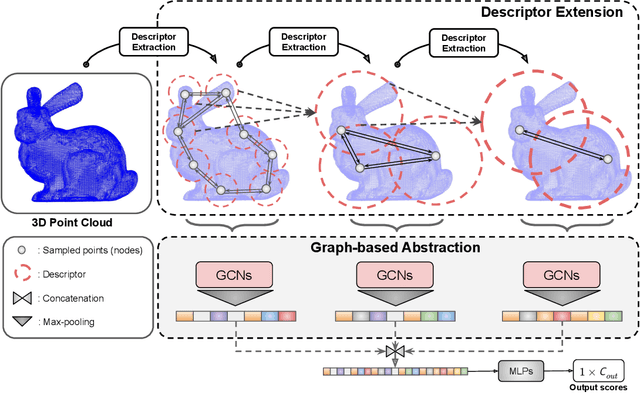
We propose a local-to-global representation learning algorithm for 3D point cloud data, which is appropriate to handle various geometric transformations, especially rotation, without explicit data augmentation with respect to the transformations. Our model takes advantage of multi-level abstraction based on graph convolutional neural networks, which constructs a descriptor hierarchy to encode rotation-invariant shape information of an input object in a bottom-up manner. The descriptors in each level are obtained from a neural network based on a graph via stochastic sampling of 3D points, which is effective in making the learned representations robust to the variations of input data. The proposed algorithm presents the state-of-the-art performance on the rotation-augmented 3D object recognition and segmentation benchmarks, and we further analyze its characteristics through comprehensive ablative experiments.