 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHierarchical Visual Feature Aggregation for OCR-Free Document Understanding
Nov 08, 2024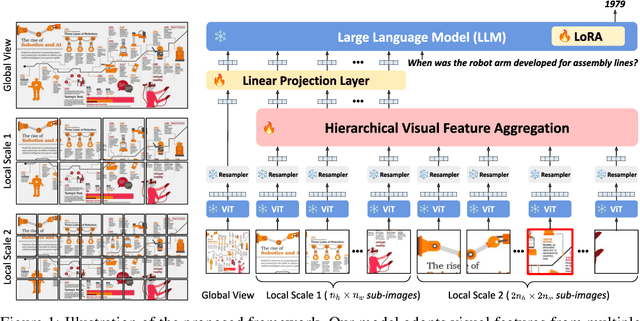

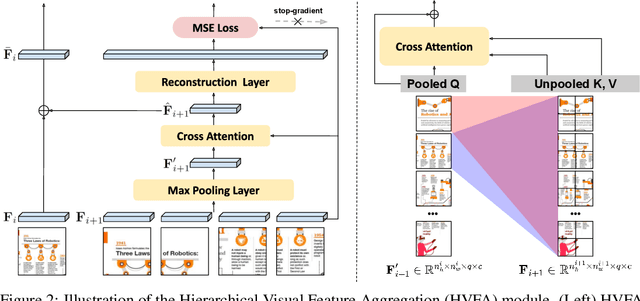
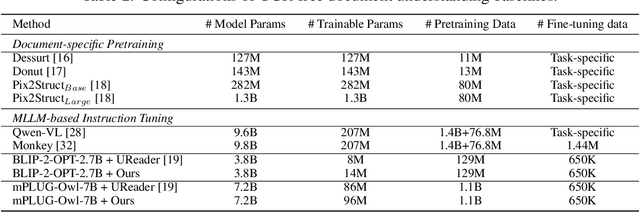
We present a novel OCR-free document understanding framework based on pretrained Multimodal Large Language Models (MLLMs). Our approach employs multi-scale visual features to effectively handle various font sizes within document images. To address the increasing costs of considering the multi-scale visual inputs for MLLMs, we propose the Hierarchical Visual Feature Aggregation (HVFA) module, designed to reduce the number of input tokens to LLMs. Leveraging a feature pyramid with cross-attentive pooling, our approach effectively manages the trade-off between information loss and efficiency without being affected by varying document image sizes. Furthermore, we introduce a novel instruction tuning task, which facilitates the model's text-reading capability by learning to predict the relative positions of input text, eventually minimizing the risk of truncated text caused by the limited capacity of LLMs. Comprehensive experiments validate the effectiveness of our approach, demonstrating superior performance in various document understanding tasks.