 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWhen Deep Learning Met Code Search
Paper and Code


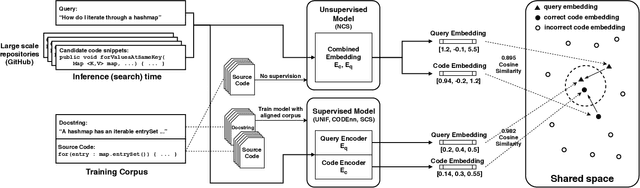
There have been multiple recent proposals on using deep neural networks for code search using natural language. Common across these proposals is the idea of $\mathit{embedding}$ code and natural language queries, into real vectors and then using vector distance to approximate semantic correlation between code and the query. Multiple approaches exist for learning these embeddings, including $\mathit{unsupervised}$ techniques, which rely only on a corpus of code examples, and $\mathit{supervised}$ techniques, which use an $\mathit{aligned}$ corpus of paired code and natural language descriptions. The goal of this supervision is to produce embeddings that are more similar for a query and the corresponding desired code snippet. Clearly, there are choices in whether to use supervised techniques at all, and if one does, what sort of network and training to use for supervision. This paper is the first to evaluate these choices systematically. To this end, we assembled implementations of state-of-the-art techniques to run on a common platform, training and evaluation corpora. To explore the design space in network complexity, we also introduced a new design point that is a $\mathit{minimal}$ supervision extension to an existing unsupervised technique. Our evaluation shows that: 1. adding supervision to an existing unsupervised technique can improve performance, though not necessarily by much; 2. simple networks for supervision can be more effective that more sophisticated sequence-based networks for code search; 3. while it is common to use docstrings to carry out supervision, there is a sizeable gap between the effectiveness of docstrings and a more query-appropriate supervision corpus.