 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDemonstration of CORNET: A System For Learning Spreadsheet Formatting Rules By Example
Aug 14, 2023

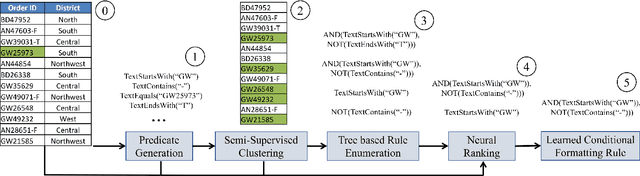

Data management and analysis tasks are often carried out using spreadsheet software. A popular feature in most spreadsheet platforms is the ability to define data-dependent formatting rules. These rules can express actions such as "color red all entries in a column that are negative" or "bold all rows not containing error or failure." Unfortunately, users who want to exercise this functionality need to manually write these conditional formatting (CF) rules. We introduce CORNET, a system that automatically learns such conditional formatting rules from user examples. CORNET takes inspiration from inductive program synthesis and combines symbolic rule enumeration, based on semi-supervised clustering and iterative decision tree learning, with a neural ranker to produce accurate conditional formatting rules. In this demonstration, we show CORNET in action as a simple add-in to Microsoft Excel. After the user provides one or two formatted cells as examples, CORNET generates formatting rule suggestions for the user to apply to the spreadsheet.
When Deep Learning Met Code Search
May 09, 2019

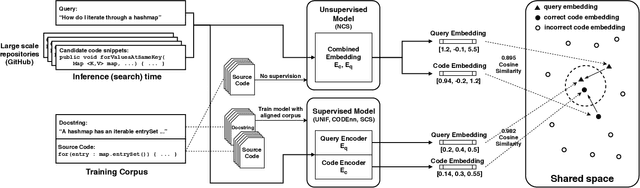
There have been multiple recent proposals on using deep neural networks for code search using natural language. Common across these proposals is the idea of $\mathit{embedding}$ code and natural language queries, into real vectors and then using vector distance to approximate semantic correlation between code and the query. Multiple approaches exist for learning these embeddings, including $\mathit{unsupervised}$ techniques, which rely only on a corpus of code examples, and $\mathit{supervised}$ techniques, which use an $\mathit{aligned}$ corpus of paired code and natural language descriptions. The goal of this supervision is to produce embeddings that are more similar for a query and the corresponding desired code snippet. Clearly, there are choices in whether to use supervised techniques at all, and if one does, what sort of network and training to use for supervision. This paper is the first to evaluate these choices systematically. To this end, we assembled implementations of state-of-the-art techniques to run on a common platform, training and evaluation corpora. To explore the design space in network complexity, we also introduced a new design point that is a $\mathit{minimal}$ supervision extension to an existing unsupervised technique. Our evaluation shows that: 1. adding supervision to an existing unsupervised technique can improve performance, though not necessarily by much; 2. simple networks for supervision can be more effective that more sophisticated sequence-based networks for code search; 3. while it is common to use docstrings to carry out supervision, there is a sizeable gap between the effectiveness of docstrings and a more query-appropriate supervision corpus.
Incremental Color Quantization for Color-Vision-Deficient Observers Using Mobile Gaming Data
Mar 22, 2018
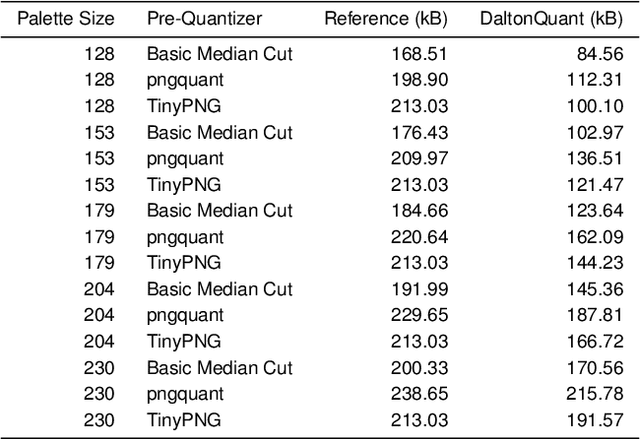

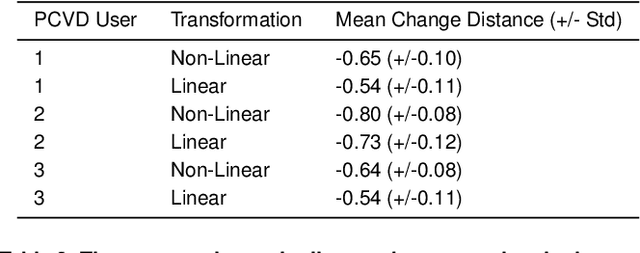
The sizes of compressed images depend on their spatial resolution (number of pixels) and on their color resolution (number of color quantization levels). We introduce DaltonQuant, a new color quantization technique for image compression that cloud services can apply to images destined for a specific user with known color vision deficiencies. DaltonQuant improves compression in a user-specific but reversible manner thereby improving a user's network bandwidth and data storage efficiency. DaltonQuant quantizes image data to account for user-specific color perception anomalies, using a new method for incremental color quantization based on a large corpus of color vision acuity data obtained from a popular mobile game. Servers that host images can revert DaltonQuant's image requantization and compression when those images must be transmitted to a different user, making the technique practical to deploy on a large scale. We evaluate DaltonQuant's compression performance on the Kodak PC reference image set and show that it improves compression by an additional 22%-29% over the state-of-the-art compressors TinyPNG and pngquant.