 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeProgrammatically Interpretable Reinforcement Learning
Paper and Code
Jun 08, 2018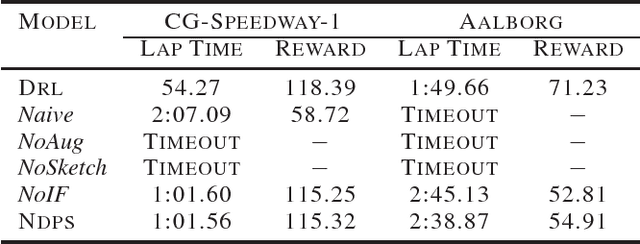


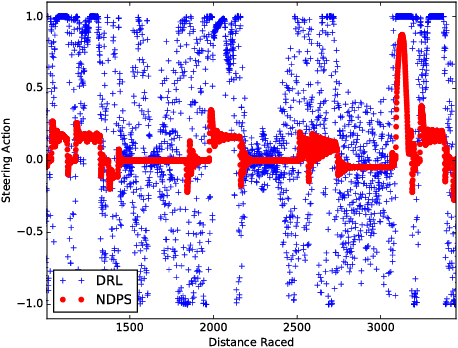
We present a reinforcement learning framework, called Programmatically Interpretable Reinforcement Learning (PIRL), that is designed to generate interpretable and verifiable agent policies. Unlike the popular Deep Reinforcement Learning (DRL) paradigm, which represents policies by neural networks, PIRL represents policies using a high-level, domain-specific programming language. Such programmatic policies have the benefits of being more easily interpreted than neural networks, and being amenable to verification by symbolic methods. We propose a new method, called Neurally Directed Program Search (NDPS), for solving the challenging nonsmooth optimization problem of finding a programmatic policy with maximal reward. NDPS works by first learning a neural policy network using DRL, and then performing a local search over programmatic policies that seeks to minimize a distance from this neural "oracle". We evaluate NDPS on the task of learning to drive a simulated car in the TORCS car-racing environment. We demonstrate that NDPS is able to discover human-readable policies that pass some significant performance bars. We also show that PIRL policies can have smoother trajectories, and can be more easily transferred to environments not encountered during training, than corresponding policies discovered by DRL.