 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMulti-line AI-assisted Code Authoring
Feb 06, 2024
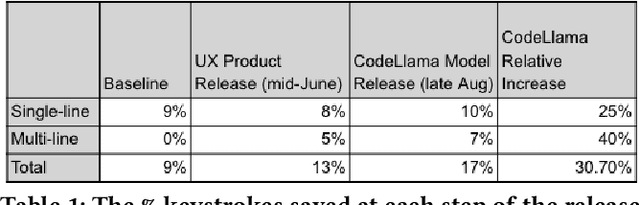
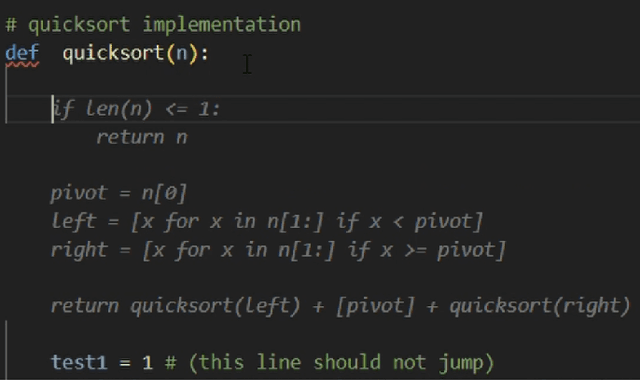

CodeCompose is an AI-assisted code authoring tool powered by large language models (LLMs) that provides inline suggestions to 10's of thousands of developers at Meta. In this paper, we present how we scaled the product from displaying single-line suggestions to multi-line suggestions. This evolution required us to overcome several unique challenges in improving the usability of these suggestions for developers. First, we discuss how multi-line suggestions can have a 'jarring' effect, as the LLM's suggestions constantly move around the developer's existing code, which would otherwise result in decreased productivity and satisfaction. Second, multi-line suggestions take significantly longer to generate; hence we present several innovative investments we made to reduce the perceived latency for users. These model-hosting optimizations sped up multi-line suggestion latency by 2.5x. Finally, we conduct experiments on 10's of thousands of engineers to understand how multi-line suggestions impact the user experience and contrast this with single-line suggestions. Our experiments reveal that (i) multi-line suggestions account for 42% of total characters accepted (despite only accounting for 16% for displayed suggestions) (ii) multi-line suggestions almost doubled the percentage of keystrokes saved for users from 9% to 17%. Multi-line CodeCompose has been rolled out to all engineers at Meta, and less than 1% of engineers have opted out of multi-line suggestions.
CodeCompose: A Large-Scale Industrial Deployment of AI-assisted Code Authoring
May 20, 2023



The rise of large language models (LLMs) has unlocked various applications of this technology in software development. In particular, generative LLMs have been shown to effectively power AI-based code authoring tools that can suggest entire statements or blocks of code during code authoring. In this paper we present CodeCompose, an AI-assisted code authoring tool developed and deployed at Meta internally. CodeCompose is based on the InCoder LLM that merges generative capabilities with bi-directionality. We have scaled up CodeCompose to serve tens of thousands of developers at Meta, across 10+ programming languages and several coding surfaces. We discuss unique challenges in terms of user experience and metrics that arise when deploying such tools in large-scale industrial settings. We present our experience in making design decisions about the model and system architecture for CodeCompose that addresses these challenges. Finally, we present metrics from our large-scale deployment of CodeCompose that shows its impact on Meta's internal code authoring experience over a 15-day time window, where 4.5 million suggestions were made by CodeCompose. Quantitative metrics reveal that (i) CodeCompose has an acceptance rate of 22% across several languages, and (ii) 8% of the code typed by users of CodeCompose is through accepting code suggestions from CodeCompose. Qualitative feedback indicates an overwhelming 91.5% positive reception for CodeCompose. In addition to assisting with code authoring, CodeCompose is also introducing other positive side effects such as encouraging developers to generate more in-code documentation, helping them with the discovery of new APIs, etc.
Learning to Learn to Predict Performance Regressions in Production at Meta
Aug 08, 2022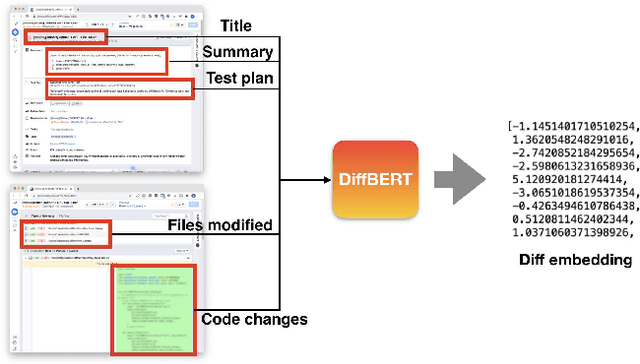
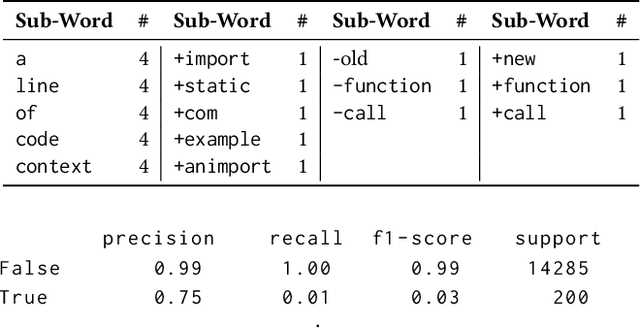
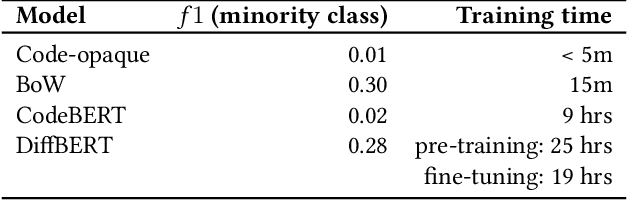
Catching and attributing code change-induced performance regressions in production is hard; predicting them beforehand, even harder. A primer on automatically learning to predict performance regressions in software, this article gives an account of the experiences we gained when researching and deploying an ML-based regression prediction pipeline at Meta. In this paper, we report on a comparative study with four ML models of increasing complexity, from (1) code-opaque, over (2) Bag of Words, (3) off-the-shelve Transformer-based, to (4) a bespoke Transformer-based model, coined SuperPerforator. Our investigation shows the inherent difficulty of the performance prediction problem, which is characterized by a large imbalance of benign onto regressing changes. Our results also call into question the general applicability of Transformer-based architectures for performance prediction: an off-the-shelve CodeBERT-based approach had surprisingly poor performance; our highly customized SuperPerforator architecture initially achieved prediction performance that was just on par with simpler Bag of Words models, and only outperformed them for down-stream use cases. This ability of SuperPerforator to transfer to an application with few learning examples afforded an opportunity to deploy it in practice at Meta: it can act as a pre-filter to sort out changes that are unlikely to introduce a regression, truncating the space of changes to search a regression in by up to 43%, a 45x improvement over a random baseline. To gain further insight into SuperPerforator, we explored it via a series of experiments computing counterfactual explanations. These highlight which parts of a code change the model deems important, thereby validating the learned black-box model.