 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAI-Assisted Fixes to Code Review Comments at Scale
Jul 17, 2025Aim. There are 10s of thousands of code review comments each week at Meta. We developed Metamate for Code Review (MetaMateCR) that provides AI-assisted fixes for reviewer comments in production at scale. Method. We developed an internal benchmark of 64k <review comment, patch> data points to fine-tune Llama models. Once our models achieve reasonable offline results, we roll them into production. To ensure that our AI-assisted fixes do not negatively impact the time it takes to do code reviews, we conduct randomized controlled safety trials as well as full production experiments. Offline Results. As a baseline, we compare GPT-4o to our small and large Llama models. In offline results, our LargeLSFT model creates an exact match patch 68% of the time outperforming GPT-4o by 9 percentage points (pp). The internal models also use more modern Hack functions when compared to the PHP functions suggested by GPT-4o. Safety Trial. When we roll MetaMateCR into production in a safety trial that compares no AI patches with AI patch suggestions, we see a large regression with reviewers taking over 5% longer to conduct reviews. After investigation, we modify the UX to only show authors the AI patches, and see no regressions in the time for reviews. Production. When we roll LargeLSFT into production, we see an ActionableToApplied rate of 19.7%, which is a 9.2pp improvement over GPT-4o. Our results illustrate the importance of safety trials in ensuring that AI does not inadvertently slow down engineers, and a successful review comment to AI patch product running at scale.
Multi-line AI-assisted Code Authoring
Feb 06, 2024
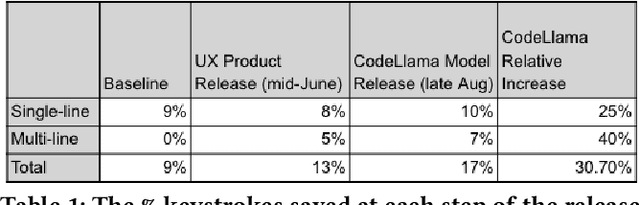

CodeCompose is an AI-assisted code authoring tool powered by large language models (LLMs) that provides inline suggestions to 10's of thousands of developers at Meta. In this paper, we present how we scaled the product from displaying single-line suggestions to multi-line suggestions. This evolution required us to overcome several unique challenges in improving the usability of these suggestions for developers. First, we discuss how multi-line suggestions can have a 'jarring' effect, as the LLM's suggestions constantly move around the developer's existing code, which would otherwise result in decreased productivity and satisfaction. Second, multi-line suggestions take significantly longer to generate; hence we present several innovative investments we made to reduce the perceived latency for users. These model-hosting optimizations sped up multi-line suggestion latency by 2.5x. Finally, we conduct experiments on 10's of thousands of engineers to understand how multi-line suggestions impact the user experience and contrast this with single-line suggestions. Our experiments reveal that (i) multi-line suggestions account for 42% of total characters accepted (despite only accounting for 16% for displayed suggestions) (ii) multi-line suggestions almost doubled the percentage of keystrokes saved for users from 9% to 17%. Multi-line CodeCompose has been rolled out to all engineers at Meta, and less than 1% of engineers have opted out of multi-line suggestions.
CodeCompose: A Large-Scale Industrial Deployment of AI-assisted Code Authoring
May 20, 2023



The rise of large language models (LLMs) has unlocked various applications of this technology in software development. In particular, generative LLMs have been shown to effectively power AI-based code authoring tools that can suggest entire statements or blocks of code during code authoring. In this paper we present CodeCompose, an AI-assisted code authoring tool developed and deployed at Meta internally. CodeCompose is based on the InCoder LLM that merges generative capabilities with bi-directionality. We have scaled up CodeCompose to serve tens of thousands of developers at Meta, across 10+ programming languages and several coding surfaces. We discuss unique challenges in terms of user experience and metrics that arise when deploying such tools in large-scale industrial settings. We present our experience in making design decisions about the model and system architecture for CodeCompose that addresses these challenges. Finally, we present metrics from our large-scale deployment of CodeCompose that shows its impact on Meta's internal code authoring experience over a 15-day time window, where 4.5 million suggestions were made by CodeCompose. Quantitative metrics reveal that (i) CodeCompose has an acceptance rate of 22% across several languages, and (ii) 8% of the code typed by users of CodeCompose is through accepting code suggestions from CodeCompose. Qualitative feedback indicates an overwhelming 91.5% positive reception for CodeCompose. In addition to assisting with code authoring, CodeCompose is also introducing other positive side effects such as encouraging developers to generate more in-code documentation, helping them with the discovery of new APIs, etc.
Code Smells in Machine Learning Systems
Mar 02, 2022
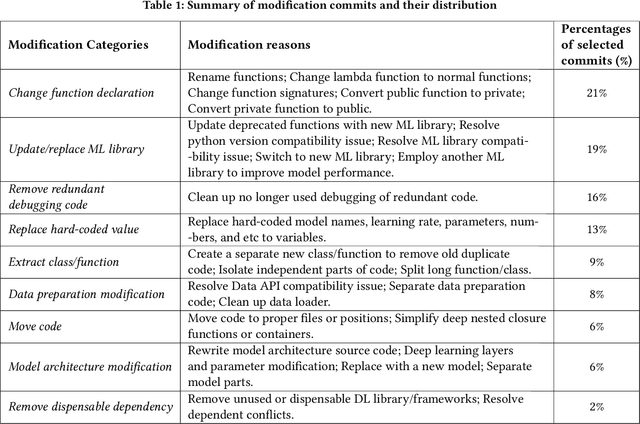
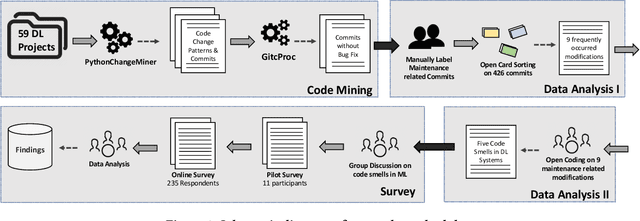

As Deep learning (DL) systems continuously evolve and grow, assuring their quality becomes an important yet challenging task. Compared to non-DL systems, DL systems have more complex team compositions and heavier data dependency. These inherent characteristics would potentially cause DL systems to be more vulnerable to bugs and, in the long run, to maintenance issues. Code smells are empirically tested as efficient indicators of non-DL systems. Therefore, we took a step forward into identifying code smells, and understanding their impact on maintenance in this comprehensive study. This is the first study on investigating code smells in the context of DL software systems, which helps researchers and practitioners to get a first look at what kind of maintenance modification made and what code smells developers have been dealing with. Our paper has three major contributions. First, we comprehensively investigated the maintenance modifications that have been made by DL developers via studying the evolution of DL systems, and we identified nine frequently occurred maintenance-related modification categories in DL systems. Second, we summarized five code smells in DL systems. Third, we validated the prevalence, and the impact of our newly identified code smells through a mixture of qualitative and quantitative analysis. We found that our newly identified code smells are prevalent and impactful on the maintenance of DL systems from the developer's perspective.
ConE: A Concurrent Edit Detection Tool for Large ScaleSoftware Development
Jan 16, 2021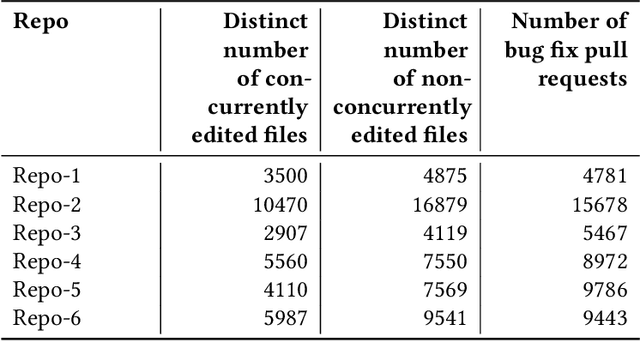
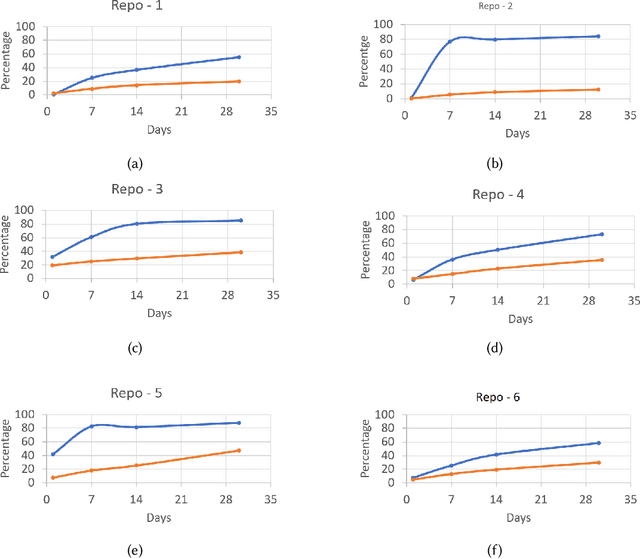

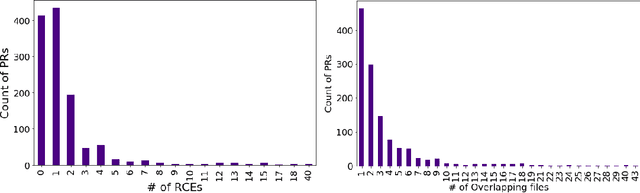
Developers from different teams or organizations, co-located or distributed, making changes to the same source code files or areas, through pull requests that are active in the same time period, is an essential part of developing complex software systems. With such a dynamically changing environment spanning several boundaries, geographic and organizational, there is little awareness about the changes that are flowing in through other active pull requests in the system leading to complex merge conflicts, hard-to-detect logical bugs or duplication of work and wasted developer productivity. In order to address this problem, we studied changes produced in eight very large repositories, in Microsoft to understand the extent of concurrent edits and their relation to subsequent bugs and bug fixes. Motivated by our findings, we developed a system called ConE (Concurrent Edit Detector) that proactively detects concurrent edits to help mitigate the problems caused by them. We present the results of ConE's deployment through early intervention techniques such as pull request notifications, by which ConE facilitates better communication among all the stakeholders participating in collaborative software development, helping avoid future problems.
Nudge: Accelerating Overdue Pull Requests Towards Completion
Nov 25, 2020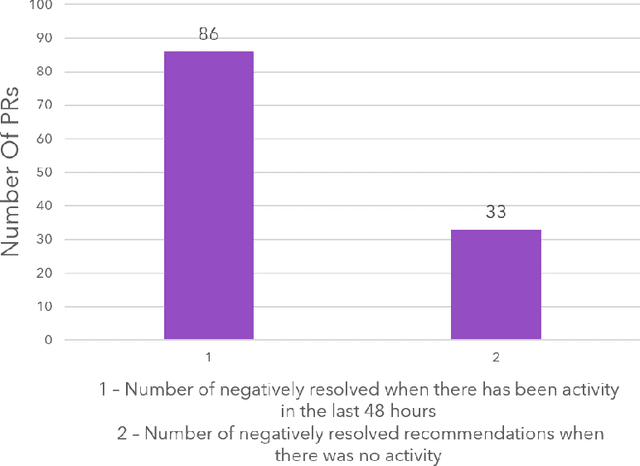
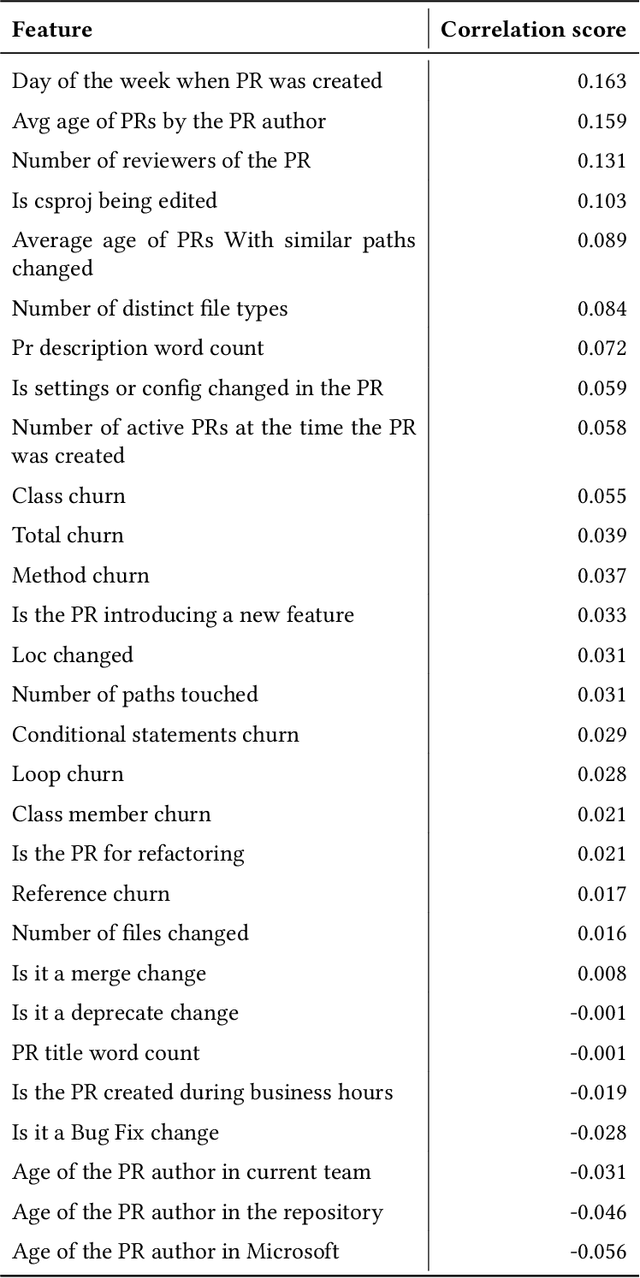
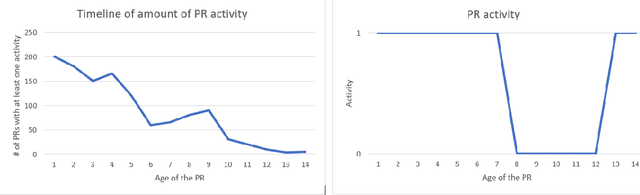
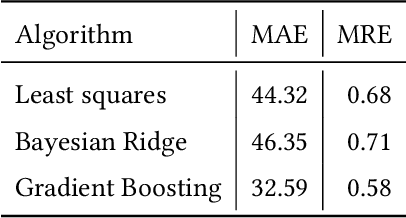
Pull requests are a key part of the collaborative software development and code review process today. However, pull requests can also slow down the software development process when the reviewer(s) or the author do not actively engage with the pull request. In this work, we design an end-to-end service, Nudge, for accelerating overdue pull requests towards completion by reminding the author or the reviewer(s) to engage with their overdue pull requests. First, we use models based on effort estimation and machine learning to predict the completion time for a given pull request. Second, we use activity detection to reduce false positives. Lastly, we use dependency determination to understand the blocker of the pull request and nudge the appropriate actor(author or reviewer(s)). We also do a correlation analysis to understand the statistical relationship between the pull request completion times and various pull request and developer related attributes. Nudge has been deployed on 147 repositories at Microsoft since 2019. We do a large scale evaluation based on the implicit and explicit feedback we received from sending the Nudge notifications on 8,500 pull requests. We observe significant reduction in completion time, by over 60%, for pull requests which were nudged thus increasing the efficiency of the code review process and accelerating the pull request progression.
Neural Knowledge Extraction From Cloud Service Incidents
Jul 15, 2020
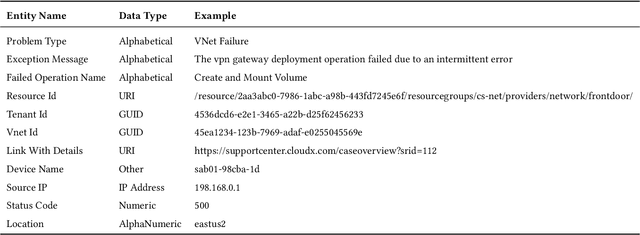

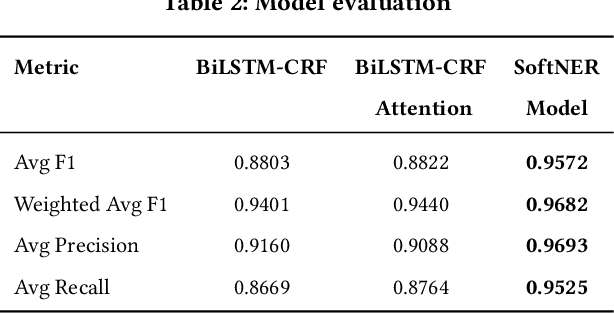
In the last decade, two paradigm shifts have reshaped the software industry - the move from boxed products to services and the widespread adoption of cloud computing. This has had a huge impact on the software development life cycle and the DevOps processes. Particularly, incident management has become critical for developing and operating large-scale services. Incidents are created to ensure timely communication of service issues and, also, their resolution. Prior work on incident management has been heavily focused on the challenges with incident triaging and de-duplication. In this work, we address the fundamental problem of structured knowledge extraction from service incidents. We have built SoftNER, a framework for unsupervised knowledge extraction from service incidents. We frame the knowledge extraction problem as a Named-entity Recognition task for extracting factual information. SoftNER leverages structural patterns like key,value pairs and tables for bootstrapping the training data. Further, we build a novel multi-task learning based BiLSTM-CRF model which leverages not just the semantic context but also the data-types for named-entity extraction. We have deployed SoftNER at Microsoft, a major cloud service provider and have evaluated it on more than 2 months of cloud incidents. We show that the unsupervised machine learning based approach has a high precision of 0.96. Our multi-task learning based deep learning model also outperforms the state of the art NER models. Lastly, using the knowledge extracted by SoftNER we are able to build significantly more accurate models for important downstream tasks like incident triaging.