 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCodeFill: Multi-token Code Completion by Jointly Learning from Structure and Naming Sequences
Feb 14, 2022



Code completion is an essential feature of IDEs, yet current autocompleters are restricted to either grammar-based or NLP-based single token completions. Both approaches have significant drawbacks: grammar-based autocompletion is restricted in dynamically-typed language environments, whereas NLP-based autocompleters struggle to understand the semantics of the programming language and the developer's code context. In this work, we present CodeFill, a language model for autocompletion that combines learned structure and naming information. Using a parallel Transformer architecture and multi-task learning, CodeFill consumes sequences of source code token names and their equivalent AST token types. Uniquely, CodeFill is trained both for single-token and multi-token (statement) prediction, which enables it to learn long-range dependencies among grammatical and naming elements. We train CodeFill on two datasets, consisting of 29M and 425M lines of code, respectively. To make the evaluation more realistic, we develop a method to automatically infer points in the source code at which completion matters. We compare CodeFill against four baselines and two state-of-the-art models, GPT-C and TravTrans+.CodeFill surpasses all baselines in single token prediction (MRR: 70.9% vs. 66.2% and 67.8%) and outperforms the state of the art for multi-token prediction (ROUGE-L: 63.7% vs. 52.4% and 59.2%, for n=4 tokens). We publicly release our source code and datasets.
ManyTypes4Py: A Benchmark Python Dataset for Machine Learning-based Type Inference
Apr 10, 2021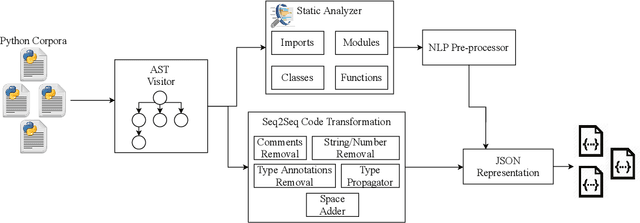
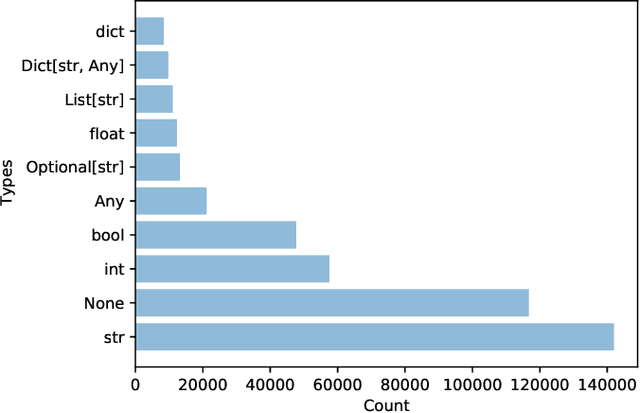

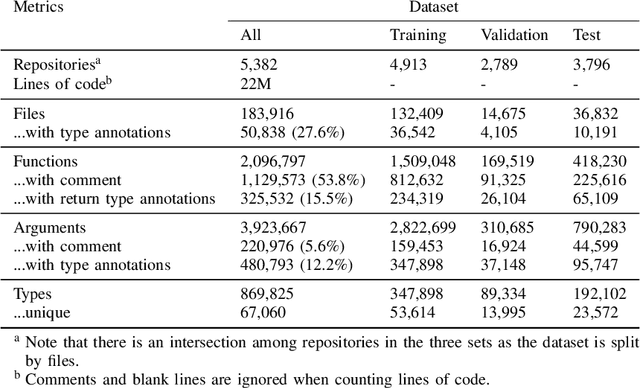
In this paper, we present ManyTypes4Py, a large Python dataset for machine learning (ML)-based type inference. The dataset contains a total of 5,382 Python projects with more than 869K type annotations. Duplicate source code files were removed to eliminate the negative effect of the duplication bias. To facilitate training and evaluation of ML models, the dataset was split into training, validation and test sets by files. To extract type information from abstract syntax trees (ASTs), a lightweight static analyzer pipeline is developed and accompanied with the dataset. Using this pipeline, the collected Python projects were analyzed and the results of the AST analysis were stored in JSON-formatted files. The ManyTypes4Py dataset is shared on zenodo and its tools are publicly available on GitHub.
ConE: A Concurrent Edit Detection Tool for Large ScaleSoftware Development
Jan 16, 2021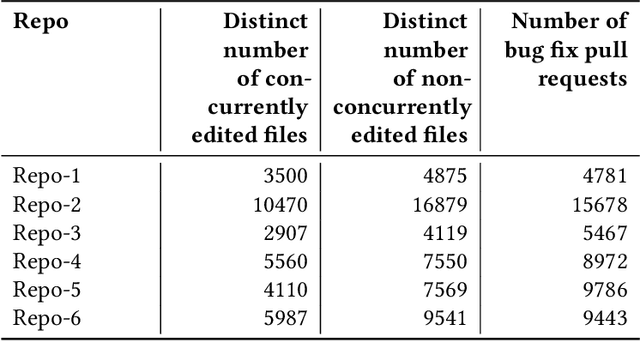
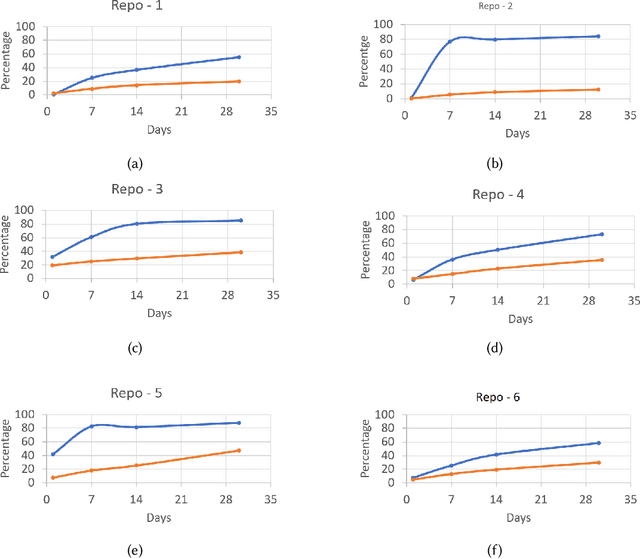

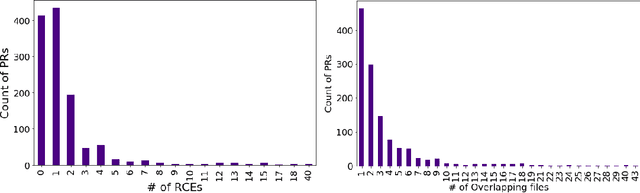
Developers from different teams or organizations, co-located or distributed, making changes to the same source code files or areas, through pull requests that are active in the same time period, is an essential part of developing complex software systems. With such a dynamically changing environment spanning several boundaries, geographic and organizational, there is little awareness about the changes that are flowing in through other active pull requests in the system leading to complex merge conflicts, hard-to-detect logical bugs or duplication of work and wasted developer productivity. In order to address this problem, we studied changes produced in eight very large repositories, in Microsoft to understand the extent of concurrent edits and their relation to subsequent bugs and bug fixes. Motivated by our findings, we developed a system called ConE (Concurrent Edit Detector) that proactively detects concurrent edits to help mitigate the problems caused by them. We present the results of ConE's deployment through early intervention techniques such as pull request notifications, by which ConE facilitates better communication among all the stakeholders participating in collaborative software development, helping avoid future problems.
Type4Py: Deep Similarity Learning-Based Type Inference for Python
Jan 12, 2021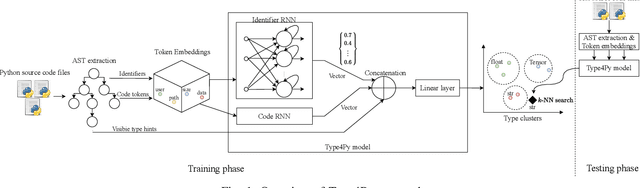
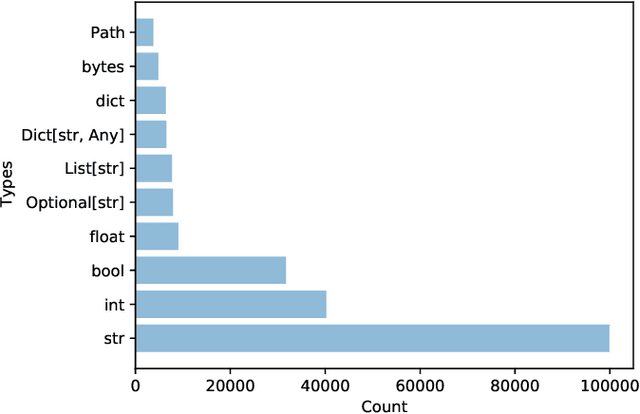

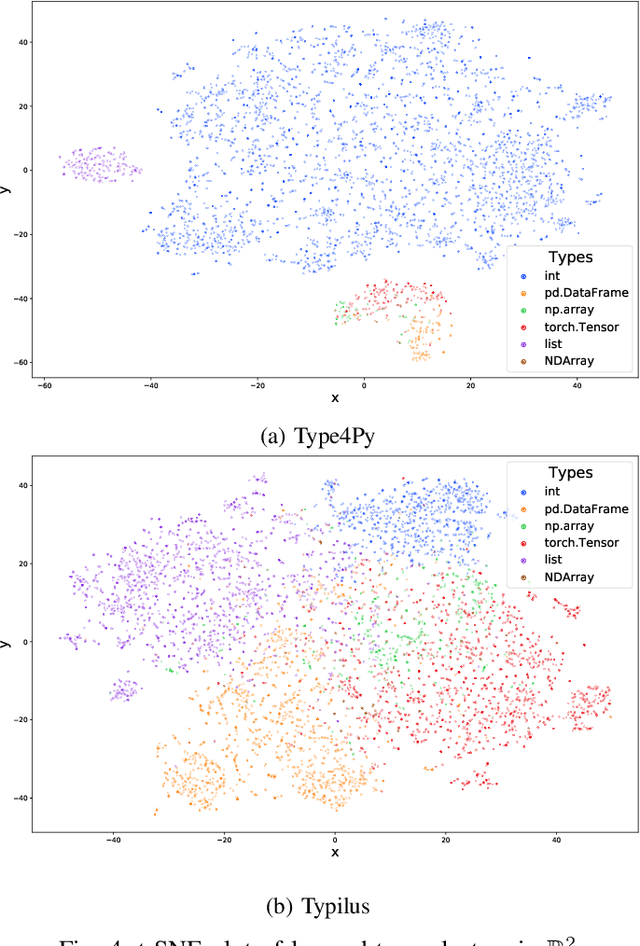
Dynamic languages, such as Python and Javascript, trade static typing for developer flexibility. While this allegedly enables greater productivity, lack of static typing can cause runtime exceptions, type inconsistencies, and is a major factor for weak IDE support. To alleviate these issues, PEP 484 introduced optional type annotations for Python. As retrofitting types to existing codebases is error-prone and laborious, learning-based approaches have been proposed to enable automatic type annotations based on existing, partially annotated codebases. However, the prediction of rare and user-defined types is still challenging. In this paper, we present Type4Py, a deep similarity learning-based type inference model for Python. We design a hierarchical neural network model that learns to discriminate between types of the same kind and dissimilar types in a high-dimensional space, which results in clusters of types. Nearest neighbor search suggests likely type signatures of given Python functions. The types visible to analyzed modules are surfaced using lightweight dependency analysis. The results of quantitative and qualitative evaluation indicate that Type4Py significantly outperforms state-of-the-art approaches at the type prediction task. Considering the Top-1 prediction, Type4Py obtains 19.33% and 13.49% higher precision than Typilus and TypeWriter, respectively, while utilizing a much bigger vocabulary.
Nudge: Accelerating Overdue Pull Requests Towards Completion
Nov 25, 2020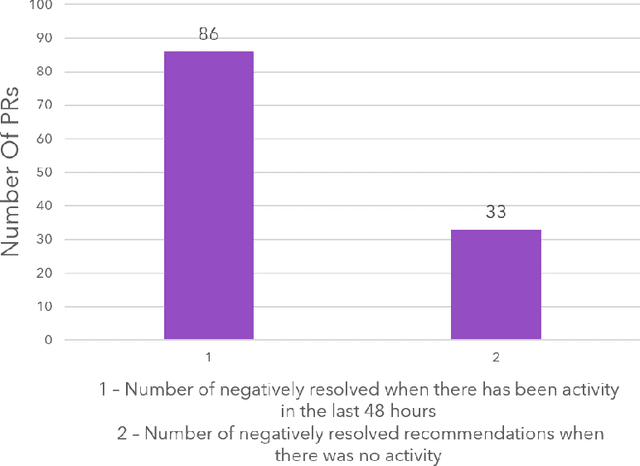
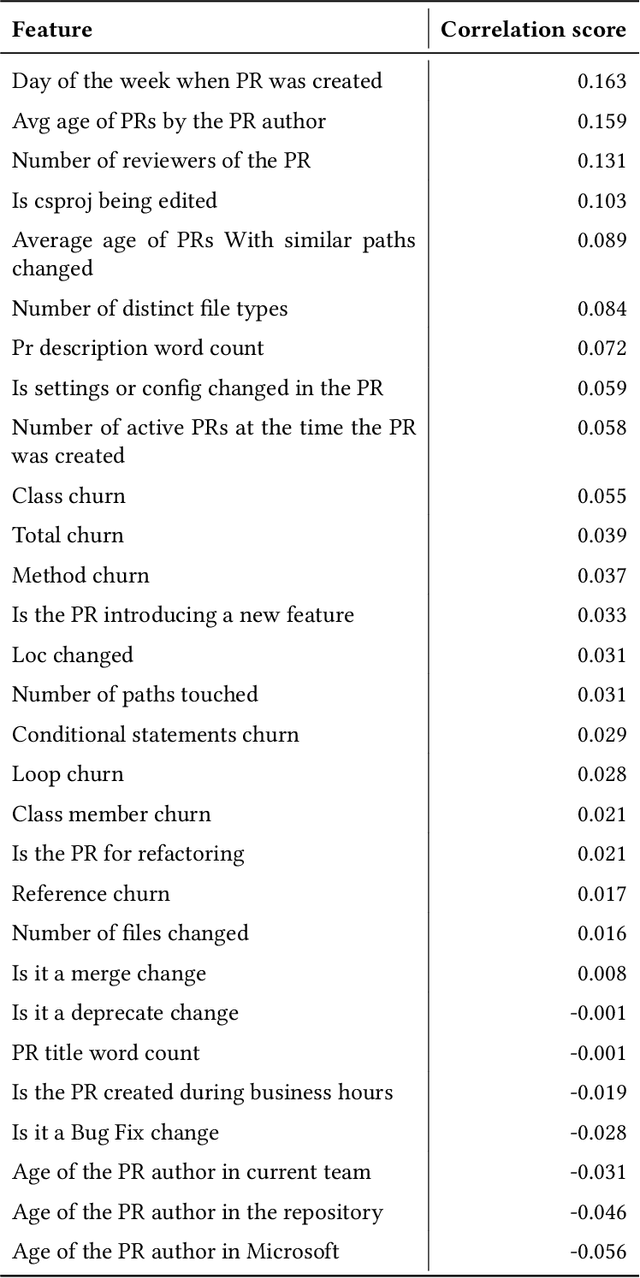
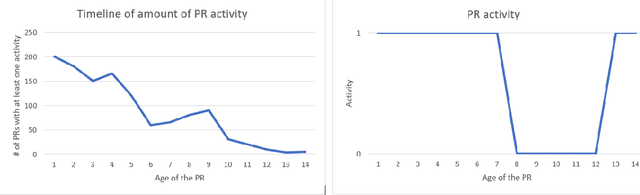
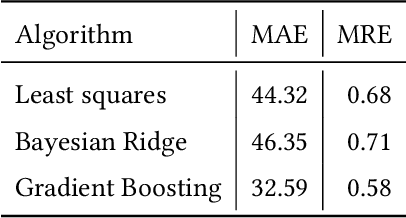
Pull requests are a key part of the collaborative software development and code review process today. However, pull requests can also slow down the software development process when the reviewer(s) or the author do not actively engage with the pull request. In this work, we design an end-to-end service, Nudge, for accelerating overdue pull requests towards completion by reminding the author or the reviewer(s) to engage with their overdue pull requests. First, we use models based on effort estimation and machine learning to predict the completion time for a given pull request. Second, we use activity detection to reduce false positives. Lastly, we use dependency determination to understand the blocker of the pull request and nudge the appropriate actor(author or reviewer(s)). We also do a correlation analysis to understand the statistical relationship between the pull request completion times and various pull request and developer related attributes. Nudge has been deployed on 147 repositories at Microsoft since 2019. We do a large scale evaluation based on the implicit and explicit feedback we received from sending the Nudge notifications on 8,500 pull requests. We observe significant reduction in completion time, by over 60%, for pull requests which were nudged thus increasing the efficiency of the code review process and accelerating the pull request progression.