 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOn the Effectiveness of Machine Learning-based Call Graph Pruning: An Empirical Study
Feb 11, 2024



Static call graph (CG) construction often over-approximates call relations, leading to sound, but imprecise results. Recent research has explored machine learning (ML)-based CG pruning as a means to enhance precision by eliminating false edges. However, current methods suffer from a limited evaluation dataset, imbalanced training data, and reduced recall, which affects practical downstream analyses. Prior results were also not compared with advanced static CG construction techniques yet. This study tackles these issues. We introduce the NYXCorpus, a dataset of real-world Java programs with high test coverage and we collect traces from test executions and build a ground truth of dynamic CGs. We leverage these CGs to explore conservative pruning strategies during the training and inference of ML-based CG pruners. We conduct a comparative analysis of static CGs generated using zero control flow analysis (0-CFA) and those produced by a context-sensitive 1-CFA algorithm, evaluating both with and without pruning. We find that CG pruning is a difficult task for real-world Java projects and substantial improvements in the CG precision (+25%) meet reduced recall (-9%). However, our experiments show promising results: even when we favor recall over precision by using an F2 metric in our experiments, we can show that pruned CGs have comparable quality to a context-sensitive 1-CFA analysis while being computationally less demanding. Resulting CGs are much smaller (69%), and substantially faster (3.5x speed-up), with virtually unchanged results in our downstream analysis.
Type4Py: Deep Similarity Learning-Based Type Inference for Python
Jan 12, 2021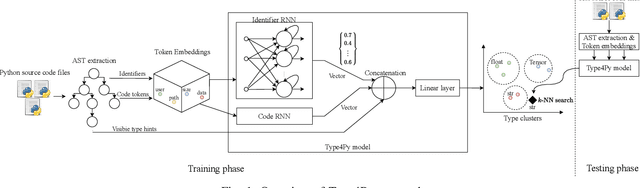
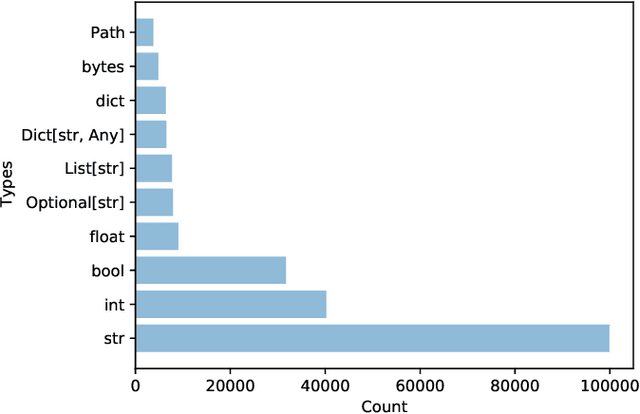

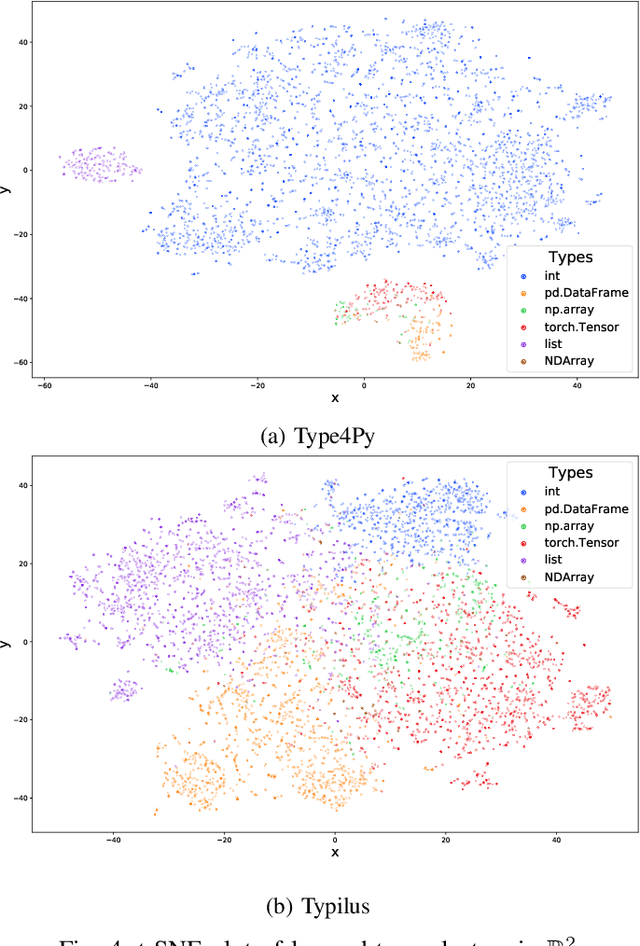
Dynamic languages, such as Python and Javascript, trade static typing for developer flexibility. While this allegedly enables greater productivity, lack of static typing can cause runtime exceptions, type inconsistencies, and is a major factor for weak IDE support. To alleviate these issues, PEP 484 introduced optional type annotations for Python. As retrofitting types to existing codebases is error-prone and laborious, learning-based approaches have been proposed to enable automatic type annotations based on existing, partially annotated codebases. However, the prediction of rare and user-defined types is still challenging. In this paper, we present Type4Py, a deep similarity learning-based type inference model for Python. We design a hierarchical neural network model that learns to discriminate between types of the same kind and dissimilar types in a high-dimensional space, which results in clusters of types. Nearest neighbor search suggests likely type signatures of given Python functions. The types visible to analyzed modules are surfaced using lightweight dependency analysis. The results of quantitative and qualitative evaluation indicate that Type4Py significantly outperforms state-of-the-art approaches at the type prediction task. Considering the Top-1 prediction, Type4Py obtains 19.33% and 13.49% higher precision than Typilus and TypeWriter, respectively, while utilizing a much bigger vocabulary.