 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTFFM: Topology-Aware Feature Fusion Module via Latent Graph Reasoning for Retinal Vessel Segmentation
Jan 27, 2026Precise segmentation of retinal arteries and veins carries the diagnosis of systemic cardiovascular conditions. However, standard convolutional architectures often yield topologically disjointed segmentations, characterized by gaps and discontinuities that render reliable graph-based clinical analysis impossible despite high pixel-level accuracy. To address this, we introduce a topology-aware framework engineered to maintain vascular connectivity. Our architecture fuses a Topological Feature Fusion Module (TFFM) that maps local feature representations into a latent graph space, deploying Graph Attention Networks to capture global structural dependencies often missed by fixed receptive fields. Furthermore, we drive the learning process with a hybrid objective function, coupling Tversky loss for class imbalance with soft clDice loss to explicitly penalize topological disconnects. Evaluation on the Fundus-AVSeg dataset reveals state-of-the-art performance, achieving a combined Dice score of 90.97% and a 95% Hausdorff Distance of 3.50 pixels. Notably, our method decreases vessel fragmentation by approximately 38% relative to baselines, yielding topologically coherent vascular trees viable for automated biomarker quantification. We open-source our code at https://tffm-module.github.io/.
Fine-Tuning vs. RAG for Multi-Hop Question Answering with Novel Knowledge
Jan 11, 2026Multi-hop question answering is widely used to evaluate the reasoning capabilities of large language models (LLMs), as it requires integrating multiple pieces of supporting knowledge to arrive at a correct answer. While prior work has explored different mechanisms for providing knowledge to LLMs, such as finetuning and retrieval-augmented generation (RAG), their relative effectiveness for multi-hop question answering remains insufficiently understood, particularly when the required knowledge is temporally novel. In this paper, we systematically compare parametric and non-parametric knowledge injection methods for open-domain multi-hop question answering. We evaluate unsupervised fine-tuning (continual pretraining), supervised fine-tuning, and retrieval-augmented generation across three 7B-parameter open-source LLMs. Experiments are conducted on two benchmarks: QASC, a standard multi-hop science question answering dataset, and a newly constructed dataset of over 10,000 multi-hop questions derived from Wikipedia events in 2024, designed to test knowledge beyond the models' pretraining cutoff. Our results show that unsupervised fine-tuning provides only limited gains over base models, suggesting that continual pretraining alone is insufficient for improving multi-hop reasoning accuracy. In contrast, retrieval-augmented generation yields substantial and consistent improvements, particularly when answering questions that rely on temporally novel information. Supervised fine-tuning achieves the highest overall accuracy across models and datasets. These findings highlight fundamental differences in how knowledge injection mechanisms support multi-hop question answering and underscore the importance of retrieval-based methods when external or compositional knowledge is required.
Performance Analysis of Machine Learning Algorithms in Chronic Kidney Disease Prediction
Oct 10, 2025Kidneys are the filter of the human body. About 10% of the global population is thought to be affected by Chronic Kidney Disease (CKD), which causes kidney function to decline. To protect in danger patients from additional kidney damage, effective risk evaluation of CKD and appropriate CKD monitoring are crucial. Due to quick and precise detection capabilities, Machine Learning models can help practitioners accomplish this goal efficiently; therefore, an enormous number of diagnosis systems and processes in the healthcare sector nowadays are relying on machine learning due to its disease prediction capability. In this study, we designed and suggested disease predictive computer-aided designs for the diagnosis of CKD. The dataset for CKD is attained from the repository of machine learning of UCL, with a few missing values; those are filled in using "mean-mode" and "Random sampling method" strategies. After successfully achieving the missing data, eight ML techniques (Random Forest, SVM, Naive Bayes, Logistic Regression, KNN, XGBoost, Decision Tree, and AdaBoost) were used to establish models, and the performance evaluation comparisons among the result accuracies are measured by the techniques to find the machine learning models with the highest accuracy. Among them, Random Forest as well as Logistic Regression showed an outstanding 99% accuracy, followed by the Ada Boost, XGBoost, Naive Bayes, Decision Tree, and SVM, whereas the KNN classifier model stands last with an accuracy of 73%.
Empowering Agricultural Insights: RiceLeafBD -- A Novel Dataset and Optimal Model Selection for Rice Leaf Disease Diagnosis through Transfer Learning Technique
Jan 15, 2025



The number of people living in this agricultural nation of ours, which is surrounded by lush greenery, is growing on a daily basis. As a result of this, the level of arable land is decreasing, as well as residential houses and industrial factories. The food crisis is becoming the main threat for us in the upcoming days. Because on the one hand, the population is increasing, and on the other hand, the amount of food crop production is decreasing due to the attack of diseases. Rice is one of the most significant cultivated crops since it provides food for more than half of the world's population. Bangladesh is dependent on rice (Oryza sativa) as a vital crop for its agriculture, but it faces a significant problem as a result of the ongoing decline in rice yield brought on by common diseases. Early disease detection is the main difficulty in rice crop cultivation. In this paper, we proposed our own dataset, which was collected from the Bangladesh field, and also applied deep learning and transfer learning models for the evaluation of the datasets. We elaborately explain our dataset and also give direction for further research work to serve society using this dataset. We applied a light CNN model and pre-trained InceptionNet-V2, EfficientNet-V2, and MobileNet-V2 models, which achieved 91.5% performance for the EfficientNet-V2 model of this work. The results obtained assaulted other models and even exceeded approaches that are considered to be part of the state of the art. It has been demonstrated by this study that it is possible to precisely and effectively identify diseases that affect rice leaves using this unbiased datasets. After analysis of the performance of different models, the proposed datasets are significant for the society for research work to provide solutions for decreasing rice leaf disease.
A Novel Ensemble-Based Deep Learning Model with Explainable AI for Accurate Kidney Disease Diagnosis
Dec 12, 2024Chronic Kidney Disease (CKD) represents a significant global health challenge, characterized by the progressive decline in renal function, leading to the accumulation of waste products and disruptions in fluid balance within the body. Given its pervasive impact on public health, there is a pressing need for effective diagnostic tools to enable timely intervention. Our study delves into the application of cutting-edge transfer learning models for the early detection of CKD. Leveraging a comprehensive and publicly available dataset, we meticulously evaluate the performance of several state-of-the-art models, including EfficientNetV2, InceptionNetV2, MobileNetV2, and the Vision Transformer (ViT) technique. Remarkably, our analysis demonstrates superior accuracy rates, surpassing the 90% threshold with MobileNetV2 and achieving 91.5% accuracy with ViT. Moreover, to enhance predictive capabilities further, we integrate these individual methodologies through ensemble modeling, resulting in our ensemble model exhibiting a remarkable 96% accuracy in the early detection of CKD. This significant advancement holds immense promise for improving clinical outcomes and underscores the critical role of machine learning in addressing complex medical challenges.
A Deep Dive Into Large Language Model Code Generation Mistakes: What and Why?
Nov 03, 2024



Recent advancements in Large Language Models (LLMs) have led to their widespread application in automated code generation. However, these models can still generate defective code that deviates from the specification. Previous research has mainly focused on the mistakes in LLM-generated standalone functions, overlooking real-world software development situations where the successful generation of the code requires software contexts such as external dependencies. In this paper, we considered both of these code generation situations and identified a range of \textit{non-syntactic mistakes} arising from LLMs' misunderstandings of coding question specifications. Seven categories of non-syntactic mistakes were identified through extensive manual analyses, four of which were missed by previous works. To better understand these mistakes, we proposed six reasons behind these mistakes from various perspectives. Moreover, we explored the effectiveness of LLMs in detecting mistakes and their reasons. Our evaluation demonstrated that GPT-4 with the ReAct prompting technique can achieve an F1 score of up to 0.65 when identifying reasons for LLM's mistakes, such as misleading function signatures. We believe that these findings offer valuable insights into enhancing the quality of LLM-generated code.
Using AI-Based Coding Assistants in Practice: State of Affairs, Perceptions, and Ways Forward
Jun 11, 2024The last several years saw the emergence of AI assistants for code -- multi-purpose AI-based helpers in software engineering. Their quick development makes it necessary to better understand how specifically developers are using them, why they are not using them in certain parts of their development workflow, and what needs to be improved. In this work, we carried out a large-scale survey aimed at how AI assistants are used, focusing on specific software development activities and stages. We collected opinions of 481 programmers on five broad activities: (a) implementing new features, (b) writing tests, (c) bug triaging, (d) refactoring, and (e) writing natural-language artifacts, as well as their individual stages. Our results show that usage of AI assistants varies depending on activity and stage. For instance, developers find writing tests and natural-language artifacts to be the least enjoyable activities and want to delegate them the most, currently using AI assistants to generate tests and test data, as well as generating comments and docstrings most of all. This can be a good focus for features aimed to help developers right now. As for why developers do not use assistants, in addition to general things like trust and company policies, there are fixable issues that can serve as a guide for further research, e.g., the lack of project-size context, and lack of awareness about assistants. We believe that our comprehensive and specific results are especially needed now to steer active research toward where users actually need AI assistants.
Beyond Self-learned Attention: Mitigating Attention Bias in Transformer-based Models Using Attention Guidance
Feb 26, 2024Transformer-based models have demonstrated considerable potential for source code modeling tasks in software engineering. However, they are limited by their dependence solely on automatic self-attention weight learning mechanisms. Previous studies have shown that these models overemphasize delimiters added by tokenizers (e.g., [CLS], [SEP]), which may lead to overlooking essential information in the original input source code. To address this challenge, we introduce SyntaGuid, a novel approach that utilizes the observation that attention weights tend to be biased towards specific source code syntax tokens and abstract syntax tree (AST) elements in fine-tuned language models when they make correct predictions. SyntaGuid facilitates the guidance of attention-weight learning, leading to improved model performance on various software engineering tasks. We evaluate the effectiveness of SyntaGuid on multiple tasks and demonstrate that it outperforms existing state-of-the-art models in overall performance without requiring additional data. Experimental result shows that SyntaGuid can improve overall performance up to 3.25% and fix up to 28.3% wrong predictions. Our work represents the first attempt to guide the attention of Transformer-based models towards critical source code tokens during fine-tuning, highlighting the potential for enhancing Transformer-based models in software engineering.
Automated Repair of Declarative Software Specifications in the Era of Large Language Models
Oct 19, 2023The growing adoption of declarative software specification languages, coupled with their inherent difficulty in debugging, has underscored the need for effective and automated repair techniques applicable to such languages. Researchers have recently explored various methods to automatically repair declarative software specifications, such as template-based repair, feedback-driven iterative repair, and bounded exhaustive approaches. The latest developments in large language models provide new opportunities for the automatic repair of declarative specifications. In this study, we assess the effectiveness of utilizing OpenAI's ChatGPT to repair software specifications written in the Alloy declarative language. Unlike imperative languages, specifications in Alloy are not executed but rather translated into logical formulas and evaluated using backend constraint solvers to identify specification instances and counterexamples to assertions. Our evaluation focuses on ChatGPT's ability to improve the correctness and completeness of Alloy declarative specifications through automatic repairs. We analyze the results produced by ChatGPT and compare them with those of leading automatic Alloy repair methods. Our study revealed that while ChatGPT falls short in comparison to existing techniques, it was able to successfully repair bugs that no other technique could address. Our analysis also identified errors in ChatGPT's generated repairs, including improper operator usage, type errors, higher-order logic misuse, and relational arity mismatches. Additionally, we observed instances of hallucinations in ChatGPT-generated repairs and inconsistency in its results. Our study provides valuable insights for software practitioners, researchers, and tool builders considering ChatGPT for declarative specification repairs.
Code Smells in Machine Learning Systems
Mar 02, 2022
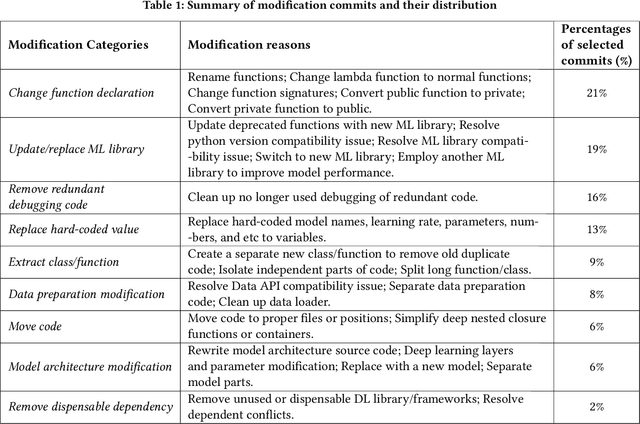
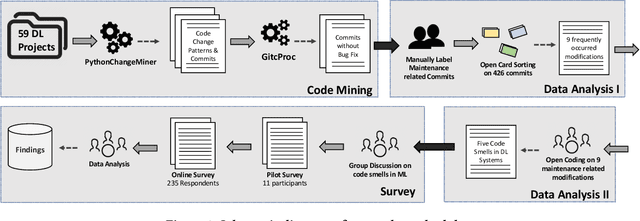

As Deep learning (DL) systems continuously evolve and grow, assuring their quality becomes an important yet challenging task. Compared to non-DL systems, DL systems have more complex team compositions and heavier data dependency. These inherent characteristics would potentially cause DL systems to be more vulnerable to bugs and, in the long run, to maintenance issues. Code smells are empirically tested as efficient indicators of non-DL systems. Therefore, we took a step forward into identifying code smells, and understanding their impact on maintenance in this comprehensive study. This is the first study on investigating code smells in the context of DL software systems, which helps researchers and practitioners to get a first look at what kind of maintenance modification made and what code smells developers have been dealing with. Our paper has three major contributions. First, we comprehensively investigated the maintenance modifications that have been made by DL developers via studying the evolution of DL systems, and we identified nine frequently occurred maintenance-related modification categories in DL systems. Second, we summarized five code smells in DL systems. Third, we validated the prevalence, and the impact of our newly identified code smells through a mixture of qualitative and quantitative analysis. We found that our newly identified code smells are prevalent and impactful on the maintenance of DL systems from the developer's perspective.