 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAI-Assisted Fixes to Code Review Comments at Scale
Jul 17, 2025Aim. There are 10s of thousands of code review comments each week at Meta. We developed Metamate for Code Review (MetaMateCR) that provides AI-assisted fixes for reviewer comments in production at scale. Method. We developed an internal benchmark of 64k <review comment, patch> data points to fine-tune Llama models. Once our models achieve reasonable offline results, we roll them into production. To ensure that our AI-assisted fixes do not negatively impact the time it takes to do code reviews, we conduct randomized controlled safety trials as well as full production experiments. Offline Results. As a baseline, we compare GPT-4o to our small and large Llama models. In offline results, our LargeLSFT model creates an exact match patch 68% of the time outperforming GPT-4o by 9 percentage points (pp). The internal models also use more modern Hack functions when compared to the PHP functions suggested by GPT-4o. Safety Trial. When we roll MetaMateCR into production in a safety trial that compares no AI patches with AI patch suggestions, we see a large regression with reviewers taking over 5% longer to conduct reviews. After investigation, we modify the UX to only show authors the AI patches, and see no regressions in the time for reviews. Production. When we roll LargeLSFT into production, we see an ActionableToApplied rate of 19.7%, which is a 9.2pp improvement over GPT-4o. Our results illustrate the importance of safety trials in ensuring that AI does not inadvertently slow down engineers, and a successful review comment to AI patch product running at scale.
Are Sparse Autoencoders Useful for Java Function Bug Detection?
May 15, 2025Software vulnerabilities such as buffer overflows and SQL injections are a major source of security breaches. Traditional methods for vulnerability detection remain essential but are limited by high false positive rates, scalability issues, and reliance on manual effort. These constraints have driven interest in AI-based approaches to automated vulnerability detection and secure code generation. While Large Language Models (LLMs) have opened new avenues for classification tasks, their complexity and opacity pose challenges for interpretability and deployment. Sparse Autoencoder offer a promising solution to this problem. We explore whether SAEs can serve as a lightweight, interpretable alternative for bug detection in Java functions. We evaluate the effectiveness of SAEs when applied to representations from GPT-2 Small and Gemma 2B, examining their capacity to highlight buggy behaviour without fine-tuning the underlying LLMs. We found that SAE-derived features enable bug detection with an F1 score of up to 89%, consistently outperforming fine-tuned transformer encoder baselines. Our work provides the first empirical evidence that SAEs can be used to detect software bugs directly from the internal representations of pretrained LLMs, without any fine-tuning or task-specific supervision.
An Exploratory Study of ML Sketches and Visual Code Assistants
Dec 17, 2024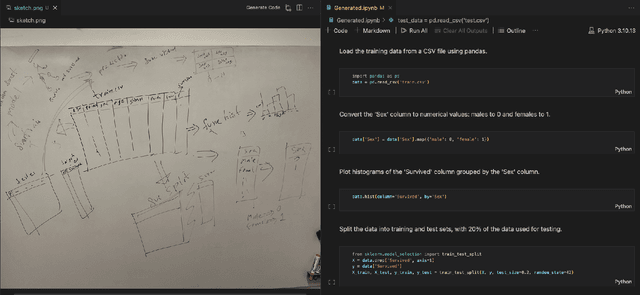

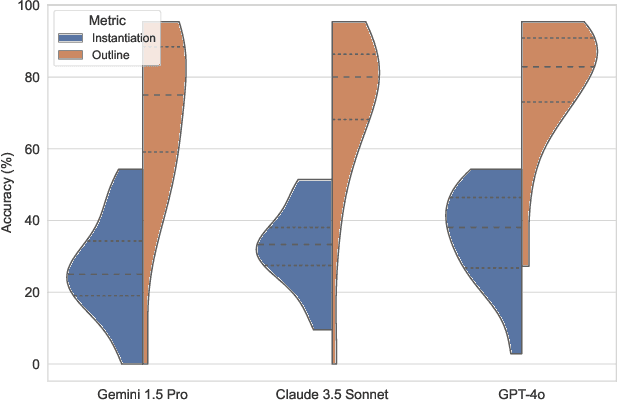
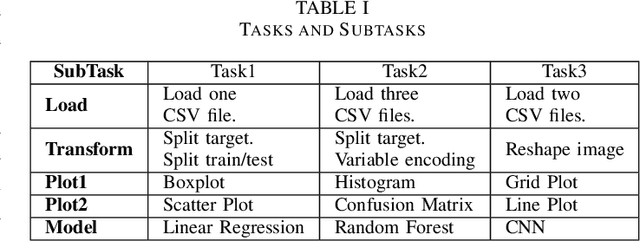
This paper explores the integration of Visual Code Assistants in Integrated Development Environments (IDEs). In Software Engineering, whiteboard sketching is often the initial step before coding, serving as a crucial collaboration tool for developers. Previous studies have investigated patterns in SE sketches and how they are used in practice, yet methods for directly using these sketches for code generation remain limited. The emergence of visually-equipped large language models presents an opportunity to bridge this gap, which is the focus of our research. In this paper, we built a first prototype of a Visual Code Assistant to get user feedback regarding in-IDE sketch-to-code tools. We conduct an experiment with 19 data scientists, most of whom regularly sketch as part of their job. We investigate developers' mental models by analyzing patterns commonly observed in their sketches when developing an ML workflow. Analysis indicates that diagrams were the preferred organizational component (52.6%), often accompanied by lists (42.1%) and numbered points (36.8%). Our tool converts their sketches into a Python notebook by querying an LLM. We use an LLM-as-judge setup to score the quality of the generated code, finding that even brief sketching can effectively generate useful code outlines. We also find a positive correlation between sketch time and the quality of the generated code. We conclude the study by conducting extensive interviews to assess the tool's usefulness, explore potential use cases, and understand developers' needs. As noted by participants, promising applications for these assistants include education, prototyping, and collaborative settings. Our findings signal promise for the next generation of Code Assistants to integrate visual information, both to improve code generation and to better leverage developers' existing sketching practices.
Evaluating Deep Neural Networks in Deployment (A Comparative and Replicability Study)
Jul 11, 2024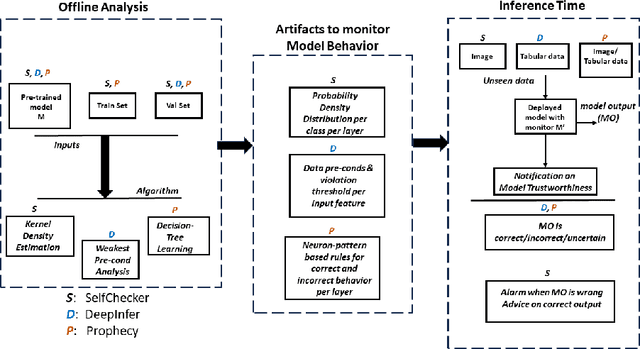
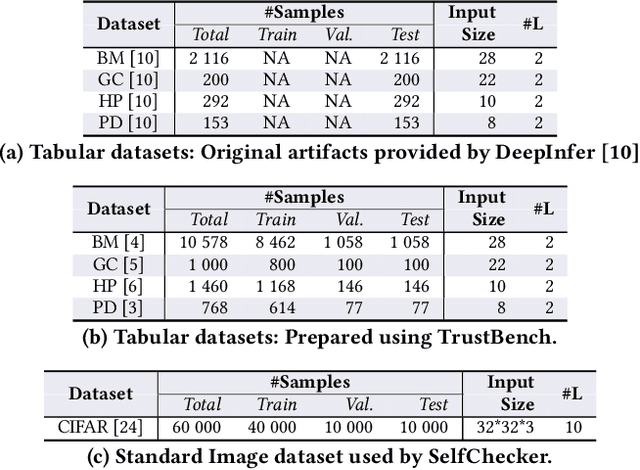
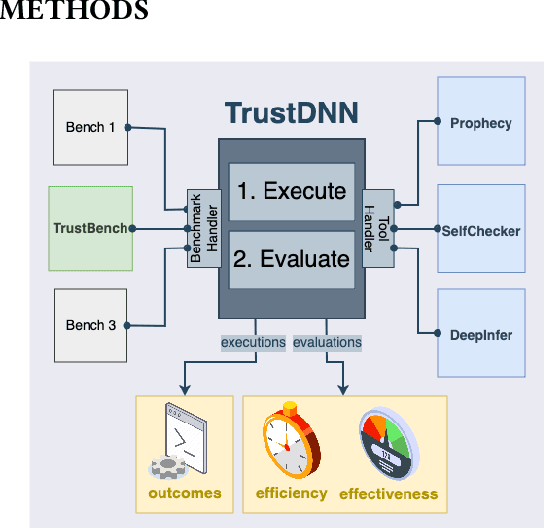
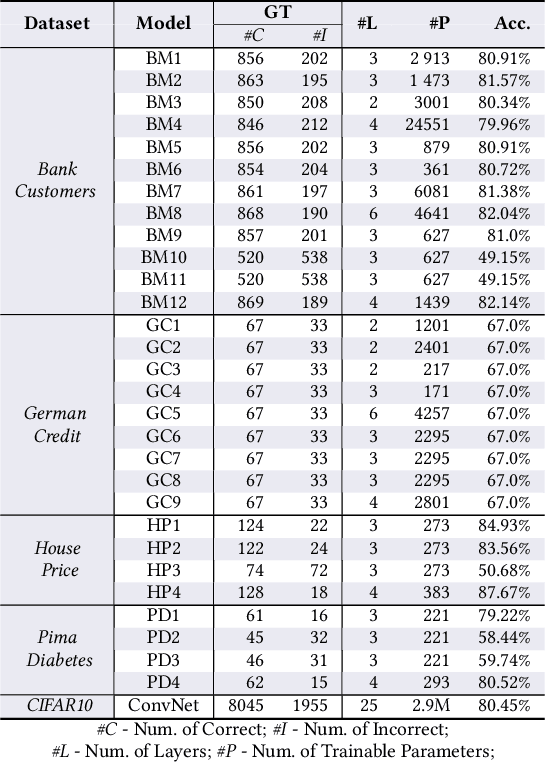
As deep neural networks (DNNs) are increasingly used in safety-critical applications, there is a growing concern for their reliability. Even highly trained, high-performant networks are not 100% accurate. However, it is very difficult to predict their behavior during deployment without ground truth. In this paper, we provide a comparative and replicability study on recent approaches that have been proposed to evaluate the reliability of DNNs in deployment. We find that it is hard to run and reproduce the results for these approaches on their replication packages and even more difficult to run them on artifacts other than their own. Further, it is difficult to compare the effectiveness of the approaches, due to the lack of clearly defined evaluation metrics. Our results indicate that more effort is needed in our research community to obtain sound techniques for evaluating the reliability of neural networks in safety-critical domains. To this end, we contribute an evaluation framework that incorporates the considered approaches and enables evaluation on common benchmarks, using common metrics.
On using distributed representations of source code for the detection of C security vulnerabilities
Jun 01, 2021


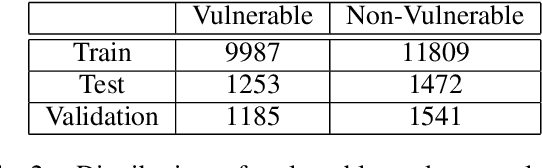
This paper presents an evaluation of the code representation model Code2vec when trained on the task of detecting security vulnerabilities in C source code. We leverage the open-source library astminer to extract path-contexts from the abstract syntax trees of a corpus of labeled C functions. Code2vec is trained on the resulting path-contexts with the task of classifying a function as vulnerable or non-vulnerable. Using the CodeXGLUE benchmark, we show that the accuracy of Code2vec for this task is comparable to simple transformer-based methods such as pre-trained RoBERTa, and outperforms more naive NLP-based methods. We achieved an accuracy of 61.43% while maintaining low computational requirements relative to larger models.
Recognizing Abnormal Heart Sounds Using Deep Learning
Oct 19, 2017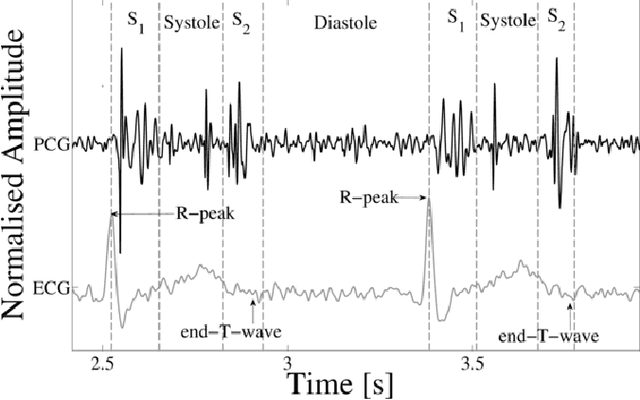
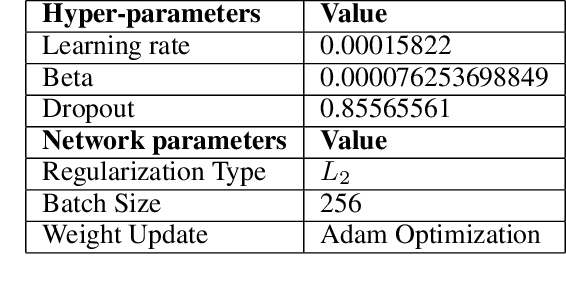

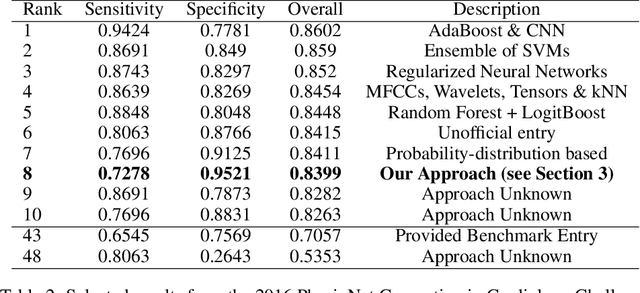
The work presented here applies deep learning to the task of automated cardiac auscultation, i.e. recognizing abnormalities in heart sounds. We describe an automated heart sound classification algorithm that combines the use of time-frequency heat map representations with a deep convolutional neural network (CNN). Given the cost-sensitive nature of misclassification, our CNN architecture is trained using a modified loss function that directly optimizes the trade-off between sensitivity and specificity. We evaluated our algorithm at the 2016 PhysioNet Computing in Cardiology challenge where the objective was to accurately classify normal and abnormal heart sounds from single, short, potentially noisy recordings. Our entry to the challenge achieved a final specificity of 0.95, sensitivity of 0.73 and overall score of 0.84. We achieved the greatest specificity score out of all challenge entries and, using just a single CNN, our algorithm differed in overall score by only 0.02 compared to the top place finisher, which used an ensemble approach.