 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDo We Still Need Clinical Language Models?
Feb 16, 2023



Although recent advances in scaling large language models (LLMs) have resulted in improvements on many NLP tasks, it remains unclear whether these models trained primarily with general web text are the right tool in highly specialized, safety critical domains such as clinical text. Recent results have suggested that LLMs encode a surprising amount of medical knowledge. This raises an important question regarding the utility of smaller domain-specific language models. With the success of general-domain LLMs, is there still a need for specialized clinical models? To investigate this question, we conduct an extensive empirical analysis of 12 language models, ranging from 220M to 175B parameters, measuring their performance on 3 different clinical tasks that test their ability to parse and reason over electronic health records. As part of our experiments, we train T5-Base and T5-Large models from scratch on clinical notes from MIMIC III and IV to directly investigate the efficiency of clinical tokens. We show that relatively small specialized clinical models substantially outperform all in-context learning approaches, even when finetuned on limited annotated data. Further, we find that pretraining on clinical tokens allows for smaller, more parameter-efficient models that either match or outperform much larger language models trained on general text. We release the code and the models used under the PhysioNet Credentialed Health Data license and data use agreement.
Enabling collaborative data science development with the Ballet framework
Dec 14, 2020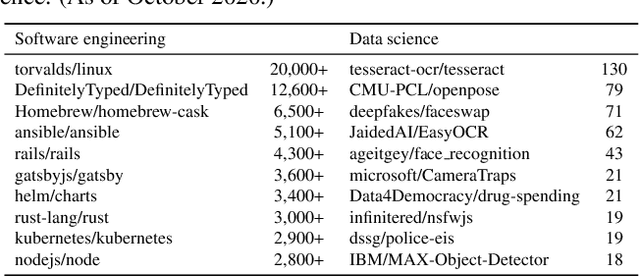


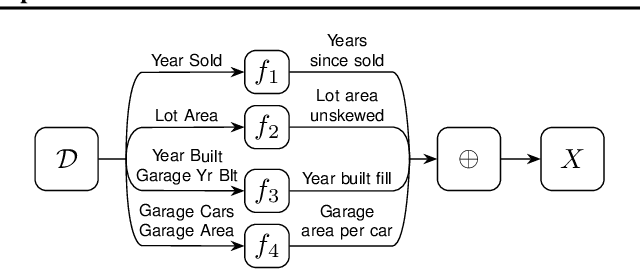
While the open-source model for software development has led to successful large-scale collaborations in building software systems, data science projects are frequently developed by individuals or small groups. We describe challenges to scaling data science collaborations and present a novel ML programming model to address them. We instantiate these ideas in Ballet, a lightweight software framework for collaborative open-source data science and a cloud-based development environment, with a plugin for collaborative feature engineering. Using our framework, collaborators incrementally propose feature definitions to a repository which are each subjected to an ML evaluation and can be automatically merged into an executable feature engineering pipeline. We leverage Ballet to conduct an extensive case study analysis of a real-world income prediction problem, and discuss implications for collaborative projects.
A Level-wise Taxonomic Perspective on Automated Machine Learning to Date and Beyond: Challenges and Opportunities
Nov 01, 2020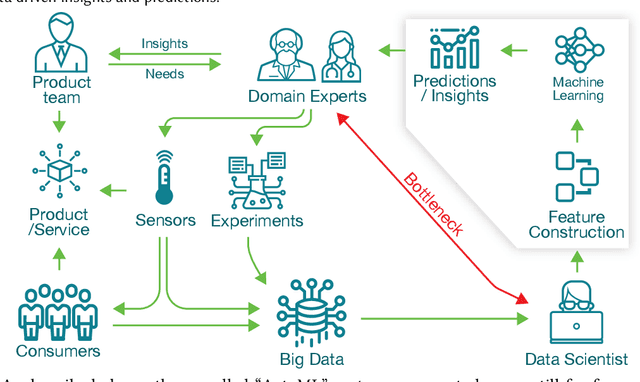
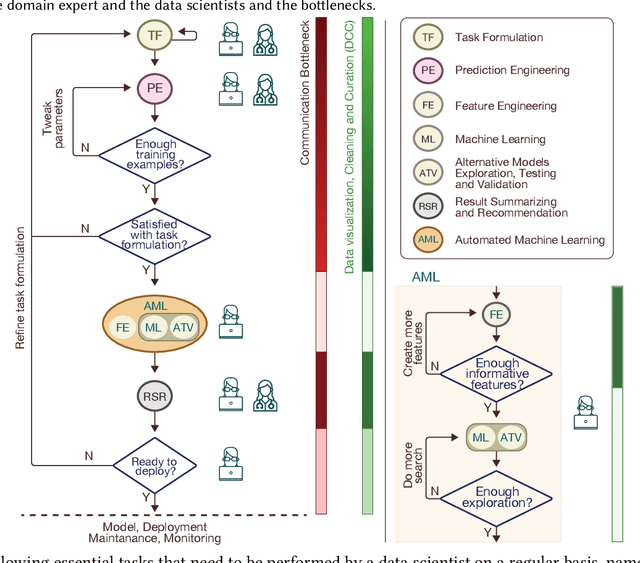
Automated machine learning (AutoML) is essentially automating the process of applying machine learning to real-world problems. The primary goals of AutoML tools are to provide methods and processes to make Machine Learning available for non-Machine Learning experts (domain experts), to improve efficiency of Machine Learning and to accelerate research on Machine Learning. Although automation and efficiency are some of AutoML's main selling points, the process still requires a surprising level of human involvement. A number of vital steps of the machine learning pipeline, including understanding the attributes of domain-specific data, defining prediction problems, creating a suitable training data set etc. still tend to be done manually by a data scientist on an ad-hoc basis. Often, this process requires a lot of back-and-forth between the data scientist and domain experts, making the whole process more difficult and inefficient. Altogether, AutoML systems are still far from a "real automatic system". In this review article, we present a level-wise taxonomic perspective on AutoML systems to-date and beyond, i.e., we introduce a new classification system with seven levels to distinguish AutoML systems based on their level of autonomy. We first start with a discussion on how an end-to-end Machine learning pipeline actually looks like and which sub-tasks of Machine learning Pipeline has indeed been automated so far. Next, we highlight the sub-tasks which are still done manually by a data-scientist in most cases and how that limits a domain expert's access to Machine learning. Then, we introduce the novel level-based taxonomy of AutoML systems and define each level according to their scope of automation support. Finally, we provide a road-map of future research endeavor in the area of AutoML and discuss some important challenges in achieving this ambitious goal.
The Machine Learning Bazaar: Harnessing the ML Ecosystem for Effective System Development
May 22, 2019
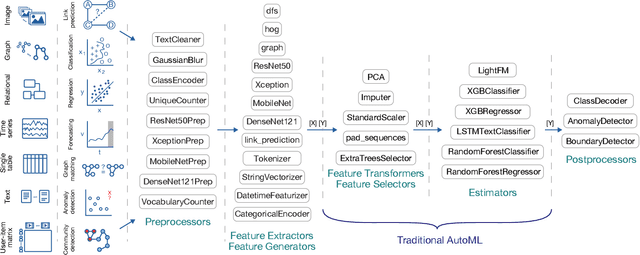
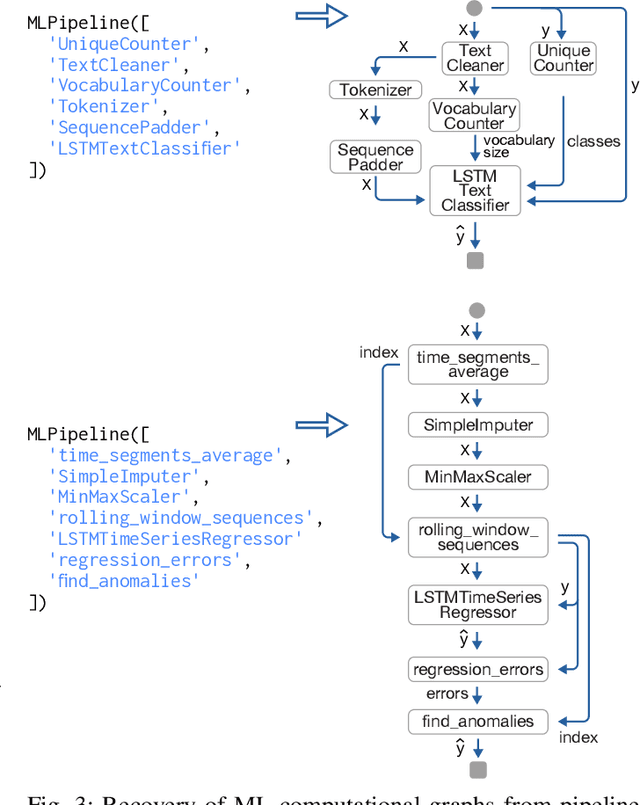

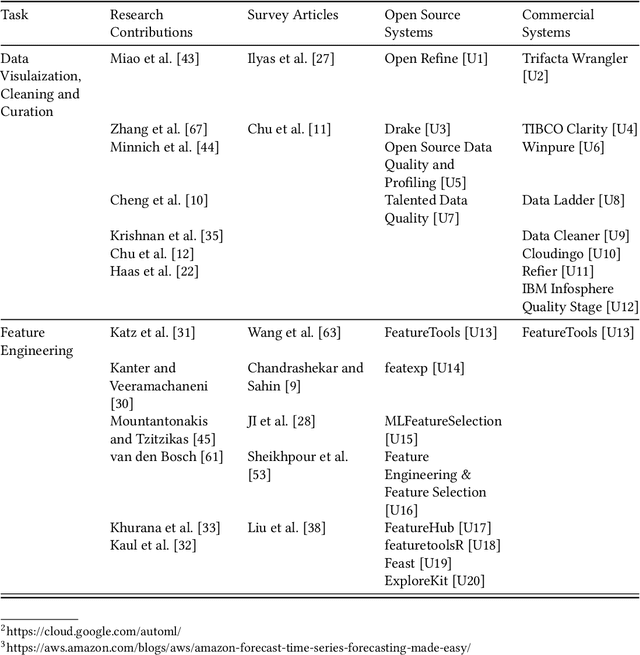
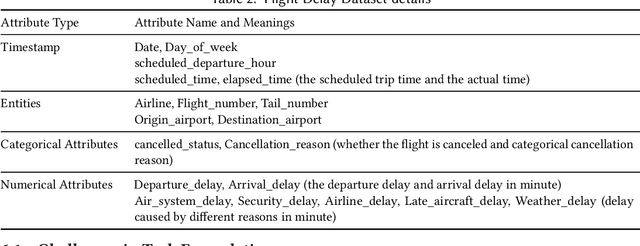
As machine learning is applied more and more widely, data scientists often struggle to find or create end-to-end machine learning systems for specific tasks. The proliferation of libraries and frameworks and the complexity of the tasks have led to the emergence of "pipeline jungles" -- brittle, ad hoc ML systems. To address these problems, we introduce the Machine Learning Bazaar, a new approach to developing machine learning and AutoML software systems. First, we introduce ML primitives, a unified API and specification for data processing and ML components from different software libraries. Next, we compose primitives into usable ML programs, abstracting away glue code, data flow, and data storage. We further pair these programs with a hierarchy of search strategies -- Bayesian optimization and bandit learning. Finally, we create and describe a general-purpose, multi-task, end-to-end AutoML system that provides solutions to a variety of ML problem types (classification, regression, anomaly detection, graph matching, etc.) and data modalities (image, text, graph, tabular, relational, etc.). We both evaluate our approach on a curated collection of 431 real-world ML tasks and search millions of pipelines, and also demonstrate real-world use cases and case studies.
ATMSeer: Increasing Transparency and Controllability in Automated Machine Learning
Feb 13, 2019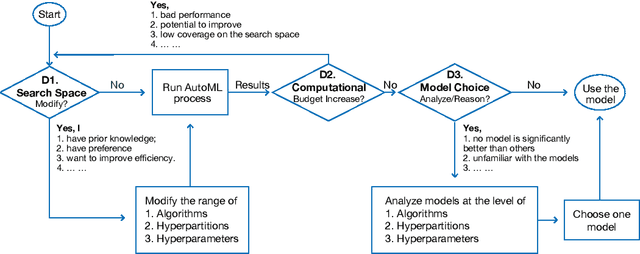
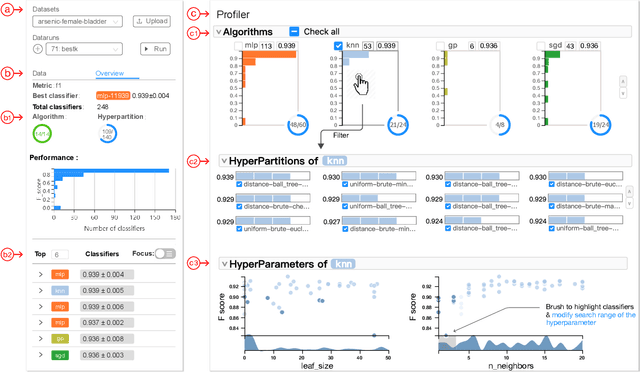
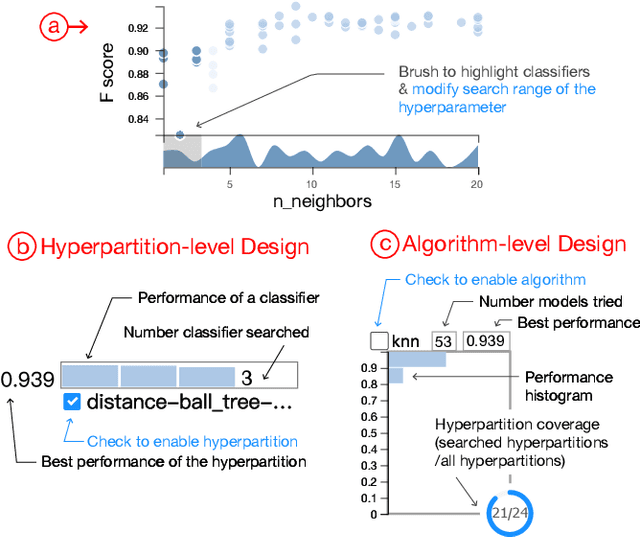
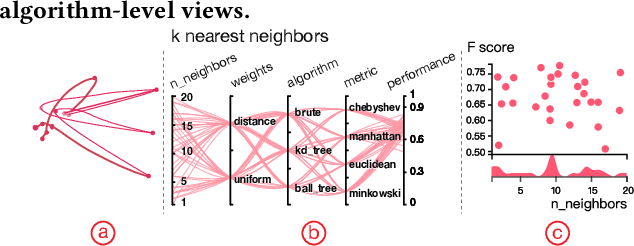
To relieve the pain of manually selecting machine learning algorithms and tuning hyperparameters, automated machine learning (AutoML) methods have been developed to automatically search for good models. Due to the huge model search space, it is impossible to try all models. Users tend to distrust automatic results and increase the search budget as much as they can, thereby undermining the efficiency of AutoML. To address these issues, we design and implement ATMSeer, an interactive visualization tool that supports users in refining the search space of AutoML and analyzing the results. To guide the design of ATMSeer, we derive a workflow of using AutoML based on interviews with machine learning experts. A multi-granularity visualization is proposed to enable users to monitor the AutoML process, analyze the searched models, and refine the search space in real time. We demonstrate the utility and usability of ATMSeer through two case studies, expert interviews, and a user study with 13 end users.