 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Level-wise Taxonomic Perspective on Automated Machine Learning to Date and Beyond: Challenges and Opportunities
Nov 01, 2020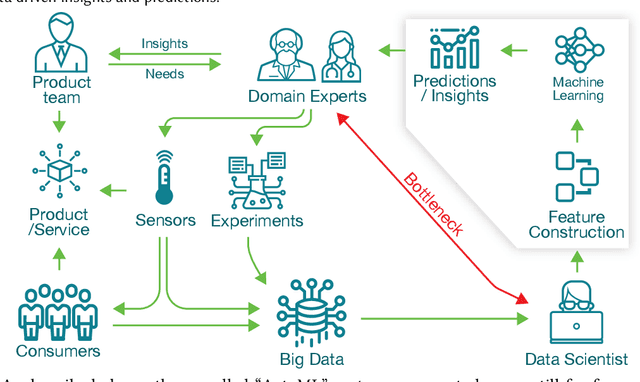
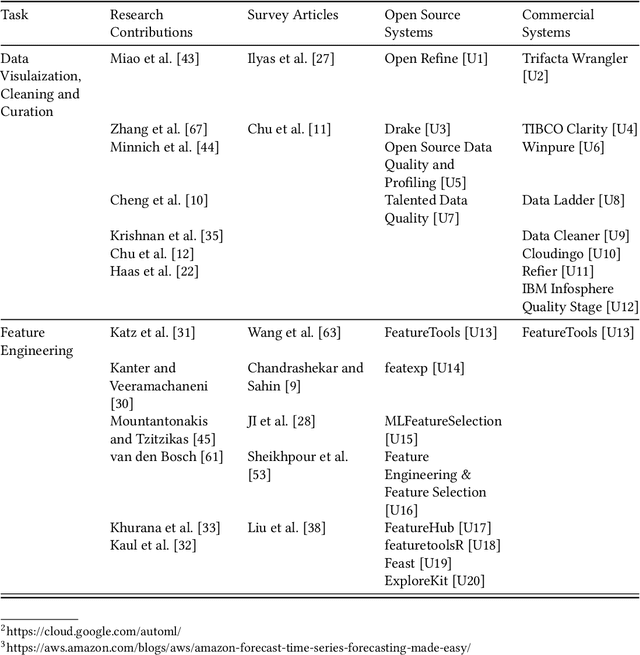
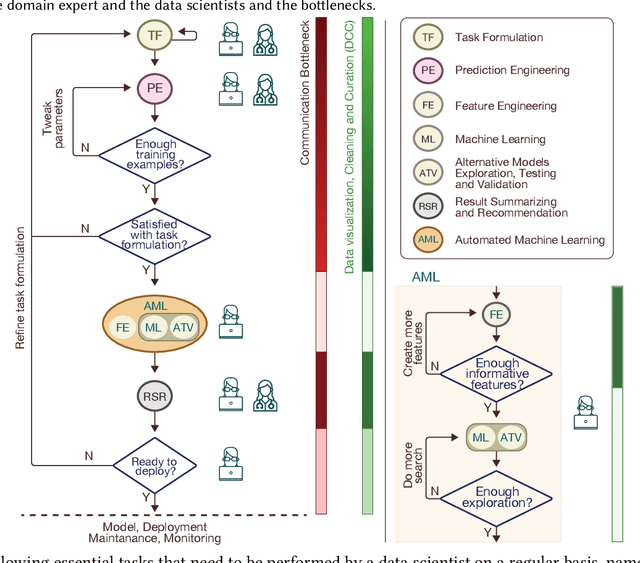
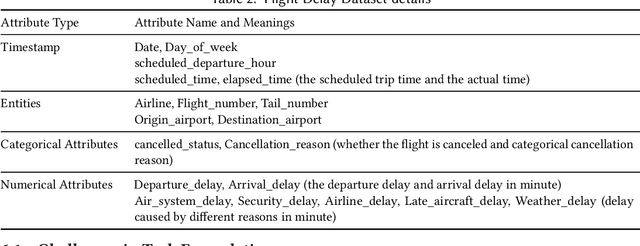
Automated machine learning (AutoML) is essentially automating the process of applying machine learning to real-world problems. The primary goals of AutoML tools are to provide methods and processes to make Machine Learning available for non-Machine Learning experts (domain experts), to improve efficiency of Machine Learning and to accelerate research on Machine Learning. Although automation and efficiency are some of AutoML's main selling points, the process still requires a surprising level of human involvement. A number of vital steps of the machine learning pipeline, including understanding the attributes of domain-specific data, defining prediction problems, creating a suitable training data set etc. still tend to be done manually by a data scientist on an ad-hoc basis. Often, this process requires a lot of back-and-forth between the data scientist and domain experts, making the whole process more difficult and inefficient. Altogether, AutoML systems are still far from a "real automatic system". In this review article, we present a level-wise taxonomic perspective on AutoML systems to-date and beyond, i.e., we introduce a new classification system with seven levels to distinguish AutoML systems based on their level of autonomy. We first start with a discussion on how an end-to-end Machine learning pipeline actually looks like and which sub-tasks of Machine learning Pipeline has indeed been automated so far. Next, we highlight the sub-tasks which are still done manually by a data-scientist in most cases and how that limits a domain expert's access to Machine learning. Then, we introduce the novel level-based taxonomy of AutoML systems and define each level according to their scope of automation support. Finally, we provide a road-map of future research endeavor in the area of AutoML and discuss some important challenges in achieving this ambitious goal.
Optimal Bangla Keyboard Layout using Data Mining Technique
Sep 25, 2010
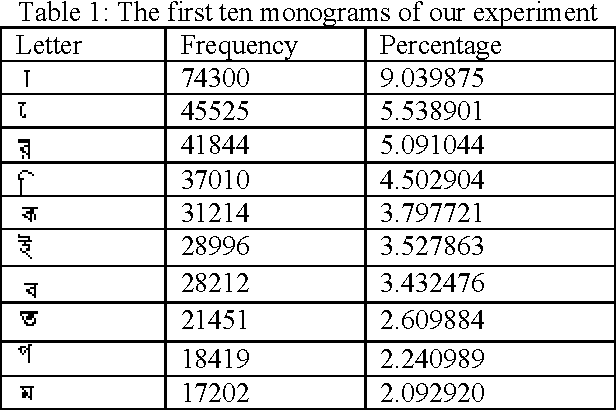
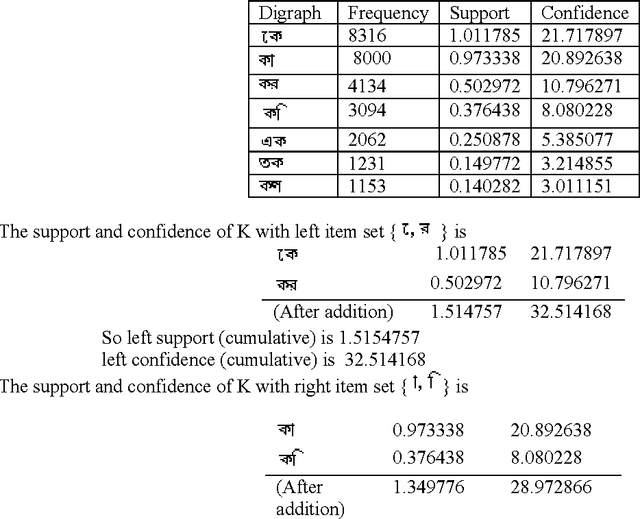
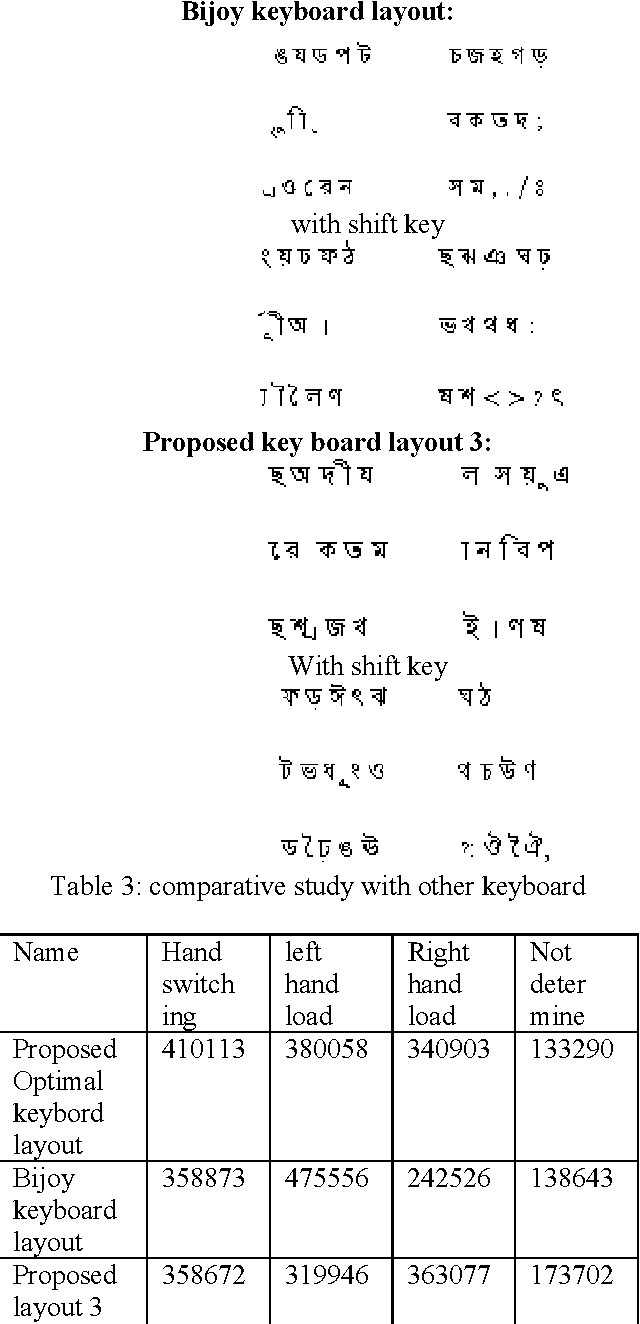
This paper presents an optimal Bangla Keyboard Layout, which distributes the load equally on both hands so that maximizing the ease and minimizing the effort. Bangla alphabet has a large number of letters, for this it is difficult to type faster using Bangla keyboard. Our proposed keyboard will maximize the speed of operator as they can type with both hands parallel. Here we use the association rule of data mining to distribute the Bangla characters in the keyboard. First, we analyze the frequencies of data consisting of monograph, digraph and trigraph, which are derived from data wire-house, and then used association rule of data mining to distribute the Bangla characters in the layout. Experimental results on several data show the effectiveness of the proposed approach with better performance.
* 9 Pages, International Conference