 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Machine Learning Bazaar: Harnessing the ML Ecosystem for Effective System Development
May 22, 2019
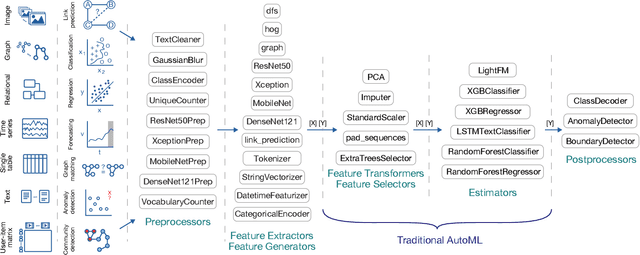
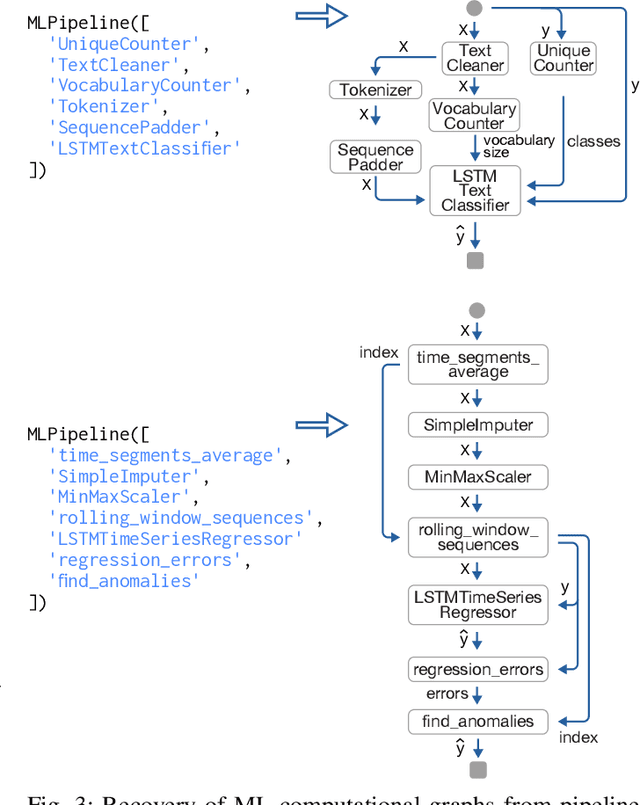

As machine learning is applied more and more widely, data scientists often struggle to find or create end-to-end machine learning systems for specific tasks. The proliferation of libraries and frameworks and the complexity of the tasks have led to the emergence of "pipeline jungles" -- brittle, ad hoc ML systems. To address these problems, we introduce the Machine Learning Bazaar, a new approach to developing machine learning and AutoML software systems. First, we introduce ML primitives, a unified API and specification for data processing and ML components from different software libraries. Next, we compose primitives into usable ML programs, abstracting away glue code, data flow, and data storage. We further pair these programs with a hierarchy of search strategies -- Bayesian optimization and bandit learning. Finally, we create and describe a general-purpose, multi-task, end-to-end AutoML system that provides solutions to a variety of ML problem types (classification, regression, anomaly detection, graph matching, etc.) and data modalities (image, text, graph, tabular, relational, etc.). We both evaluate our approach on a curated collection of 431 real-world ML tasks and search millions of pipelines, and also demonstrate real-world use cases and case studies.
Prediction Factory: automated development and collaborative evaluation of predictive models
Nov 29, 2018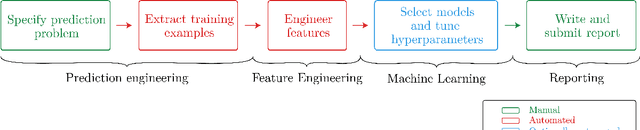



In this paper, we present a data science automation system called Prediction Factory. The system uses several key automation algorithms to enable data scientists to rapidly develop predictive models and share them with domain experts. To assess the system's impact, we implemented 3 different interfaces for creating predictive modeling projects: baseline automation, full automation, and optional automation. With a dataset of online grocery shopper behaviors, we divided data scientists among the interfaces to specify prediction problems, learn and evaluate models, and write a report for domain experts to judge whether or not to fund to continue working on. In total, 22 data scientists created 94 reports that were judged 296 times by 26 experts. In a head-to-head trial, reports generated utilizing full data science automation interface reports were funded 57.5% of the time, while the ones that used baseline automation were only funded 42.5% of the time. An intermediate interface which supports optional automation generated reports were funded 58.6% more often compared to the baseline. Full automation and optional automation reports were funded about equally when put head-to-head. These results demonstrate that Prediction Factory has implemented a critical amount of automation to augment the role of data scientists and improve business outcomes.
Machine learning 2.0 : Engineering Data Driven AI Products
Jul 01, 2018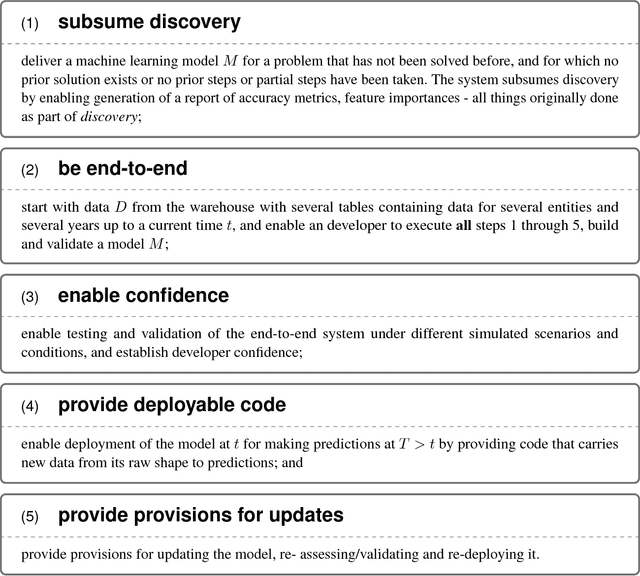

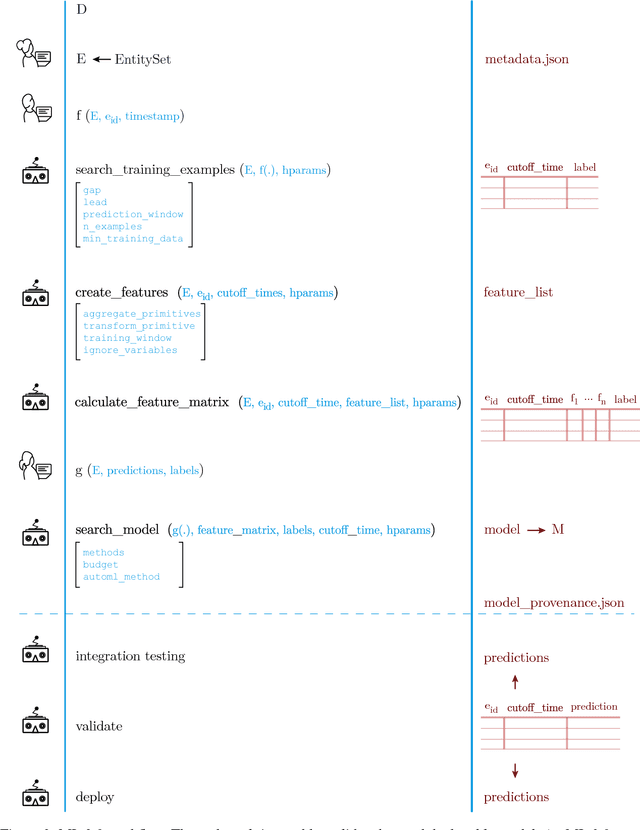

ML 2.0: In this paper, we propose a paradigm shift from the current practice of creating machine learning models - which requires months-long discovery, exploration and "feasibility report" generation, followed by re-engineering for deployment - in favor of a rapid, 8-week process of development, understanding, validation and deployment that can executed by developers or subject matter experts (non-ML experts) using reusable APIs. This accomplishes what we call a "minimum viable data-driven model," delivering a ready-to-use machine learning model for problems that haven't been solved before using machine learning. We provide provisions for the refinement and adaptation of the "model," with strict enforcement and adherence to both the scaffolding/abstractions and the process. We imagine that this will bring forth the second phase in machine learning, in which discovery is subsumed by more targeted goals of delivery and impact.
Solving the "false positives" problem in fraud prediction
Oct 20, 2017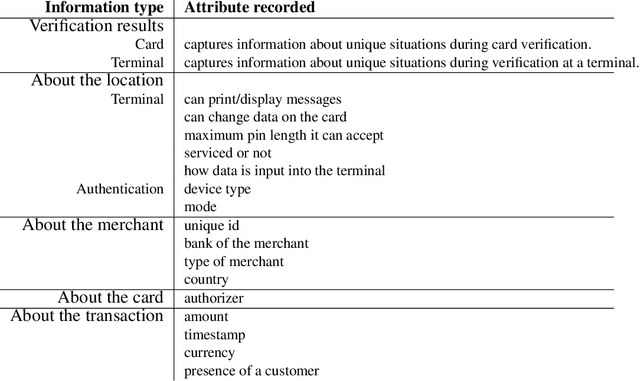


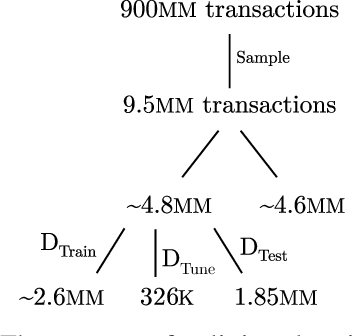
In this paper, we present an automated feature engineering based approach to dramatically reduce false positives in fraud prediction. False positives plague the fraud prediction industry. It is estimated that only 1 in 5 declared as fraud are actually fraud and roughly 1 in every 6 customers have had a valid transaction declined in the past year. To address this problem, we use the Deep Feature Synthesis algorithm to automatically derive behavioral features based on the historical data of the card associated with a transaction. We generate 237 features (>100 behavioral patterns) for each transaction, and use a random forest to learn a classifier. We tested our machine learning model on data from a large multinational bank and compared it to their existing solution. On an unseen data of 1.852 million transactions, we were able to reduce the false positives by 54% and provide a savings of 190K euros. We also assess how to deploy this solution, and whether it necessitates streaming computation for real time scoring. We found that our solution can maintain similar benefits even when historical features are computed once every 7 days.