 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePrediction Factory: automated development and collaborative evaluation of predictive models
Nov 29, 2018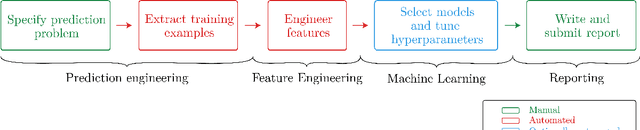



In this paper, we present a data science automation system called Prediction Factory. The system uses several key automation algorithms to enable data scientists to rapidly develop predictive models and share them with domain experts. To assess the system's impact, we implemented 3 different interfaces for creating predictive modeling projects: baseline automation, full automation, and optional automation. With a dataset of online grocery shopper behaviors, we divided data scientists among the interfaces to specify prediction problems, learn and evaluate models, and write a report for domain experts to judge whether or not to fund to continue working on. In total, 22 data scientists created 94 reports that were judged 296 times by 26 experts. In a head-to-head trial, reports generated utilizing full data science automation interface reports were funded 57.5% of the time, while the ones that used baseline automation were only funded 42.5% of the time. An intermediate interface which supports optional automation generated reports were funded 58.6% more often compared to the baseline. Full automation and optional automation reports were funded about equally when put head-to-head. These results demonstrate that Prediction Factory has implemented a critical amount of automation to augment the role of data scientists and improve business outcomes.
Machine learning 2.0 : Engineering Data Driven AI Products
Jul 01, 2018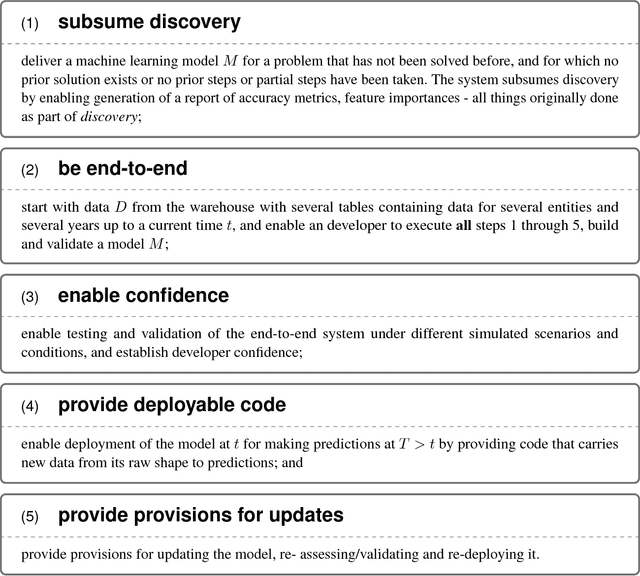

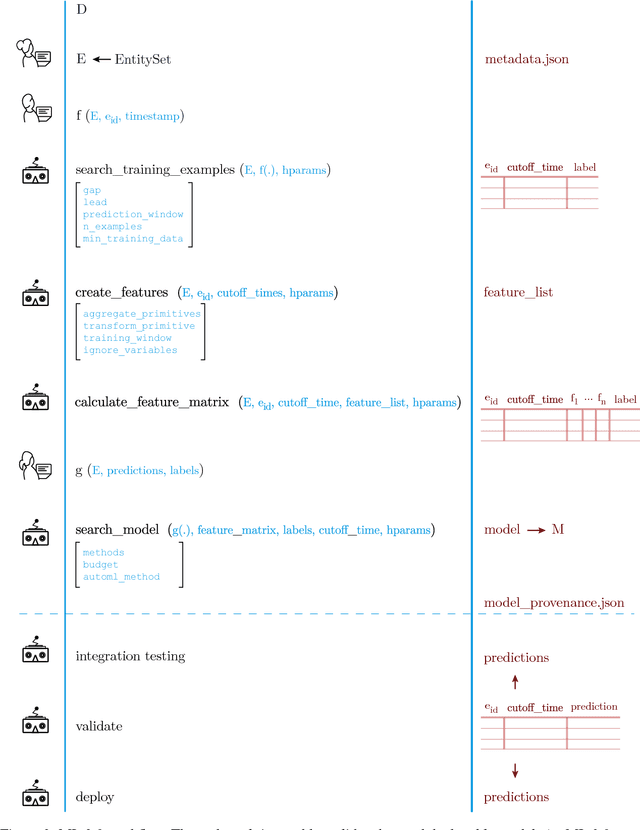

ML 2.0: In this paper, we propose a paradigm shift from the current practice of creating machine learning models - which requires months-long discovery, exploration and "feasibility report" generation, followed by re-engineering for deployment - in favor of a rapid, 8-week process of development, understanding, validation and deployment that can executed by developers or subject matter experts (non-ML experts) using reusable APIs. This accomplishes what we call a "minimum viable data-driven model," delivering a ready-to-use machine learning model for problems that haven't been solved before using machine learning. We provide provisions for the refinement and adaptation of the "model," with strict enforcement and adherence to both the scaffolding/abstractions and the process. We imagine that this will bring forth the second phase in machine learning, in which discovery is subsumed by more targeted goals of delivery and impact.