 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeKTAE: A Model-Free Algorithm to Key-Tokens Advantage Estimation in Mathematical Reasoning
May 22, 2025Recent advances have demonstrated that integrating reinforcement learning with rule-based rewards can significantly enhance the reasoning capabilities of large language models, even without supervised fine-tuning. However, prevalent reinforcement learning algorithms such as GRPO and its variants like DAPO, suffer from a coarse granularity issue when computing the advantage. Specifically, they compute rollout-level advantages that assign identical values to every token within a sequence, failing to capture token-specific contributions and hindering effective learning. To address this limitation, we propose Key-token Advantage Estimation (KTAE) - a novel algorithm that estimates fine-grained, token-level advantages without introducing additional models. KTAE leverages the correctness of sampled rollouts and applies statistical analysis to quantify the importance of individual tokens within a sequence to the final outcome. This quantified token-level importance is then combined with the rollout-level advantage to obtain a more fine-grained token-level advantage estimation. Empirical results show that models trained with GRPO+KTAE and DAPO+KTAE outperform baseline methods across five mathematical reasoning benchmarks. Notably, they achieve higher accuracy with shorter responses and even surpass R1-Distill-Qwen-1.5B using the same base model.
Towards Scientific Intelligence: A Survey of LLM-based Scientific Agents
Mar 31, 2025



As scientific research becomes increasingly complex, innovative tools are needed to manage vast data, facilitate interdisciplinary collaboration, and accelerate discovery. Large language models (LLMs) are now evolving into LLM-based scientific agents that automate critical tasks, ranging from hypothesis generation and experiment design to data analysis and simulation. Unlike general-purpose LLMs, these specialized agents integrate domain-specific knowledge, advanced tool sets, and robust validation mechanisms, enabling them to handle complex data types, ensure reproducibility, and drive scientific breakthroughs. This survey provides a focused review of the architectures, design, benchmarks, applications, and ethical considerations surrounding LLM-based scientific agents. We highlight why they differ from general agents and the ways in which they advance research across various scientific fields. By examining their development and challenges, this survey offers a comprehensive roadmap for researchers and practitioners to harness these agents for more efficient, reliable, and ethically sound scientific discovery.
TESSP: Text-Enhanced Self-Supervised Speech Pre-training
Nov 24, 2022



Self-supervised speech pre-training empowers the model with the contextual structure inherent in the speech signal while self-supervised text pre-training empowers the model with linguistic information. Both of them are beneficial for downstream speech tasks such as ASR. However, the distinct pre-training objectives make it challenging to jointly optimize the speech and text representation in the same model. To solve this problem, we propose Text-Enhanced Self-Supervised Speech Pre-training (TESSP), aiming to incorporate the linguistic information into speech pre-training. Our model consists of three parts, i.e., a speech encoder, a text encoder and a shared encoder. The model takes unsupervised speech and text data as the input and leverages the common HuBERT and MLM losses respectively. We also propose phoneme up-sampling and representation swapping to enable joint modeling of the speech and text information. Specifically, to fix the length mismatching problem between speech and text data, we phonemize the text sequence and up-sample the phonemes with the alignment information extracted from a small set of supervised data. Moreover, to close the gap between the learned speech and text representations, we swap the text representation with the speech representation extracted by the respective private encoders according to the alignment information. Experiments on the Librispeech dataset shows the proposed TESSP model achieves more than 10% improvement compared with WavLM on the test-clean and test-other sets. We also evaluate our model on the SUPERB benchmark, showing our model has better performance on Phoneme Recognition, Acoustic Speech Recognition and Speech Translation compared with WavLM.
RAPO: An Adaptive Ranking Paradigm for Bilingual Lexicon Induction
Oct 18, 2022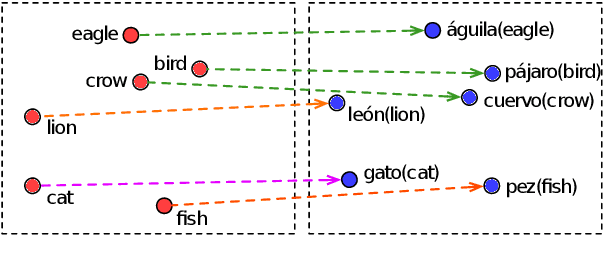
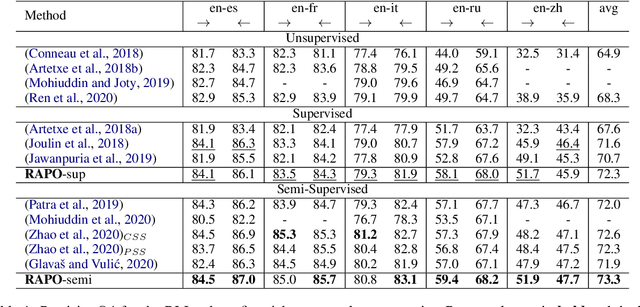
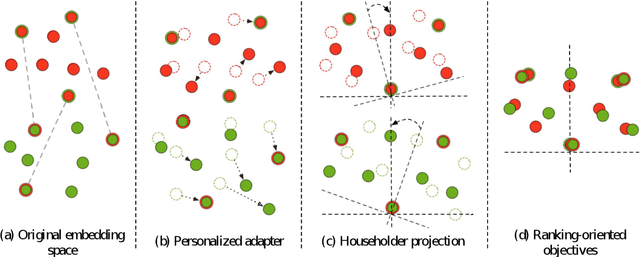
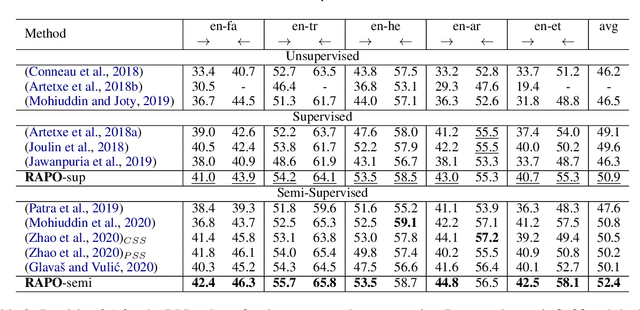
Bilingual lexicon induction induces the word translations by aligning independently trained word embeddings in two languages. Existing approaches generally focus on minimizing the distances between words in the aligned pairs, while suffering from low discriminative capability to distinguish the relative orders between positive and negative candidates. In addition, the mapping function is globally shared by all words, whose performance might be hindered by the deviations in the distributions of different languages. In this work, we propose a novel ranking-oriented induction model RAPO to learn personalized mapping function for each word. RAPO is capable of enjoying the merits from the unique characteristics of a single word and the cross-language isomorphism simultaneously. Extensive experimental results on public datasets including both rich-resource and low-resource languages demonstrate the superiority of our proposal. Our code is publicly available in \url{https://github.com/Jlfj345wf/RAPO}.
SpeechLM: Enhanced Speech Pre-Training with Unpaired Textual Data
Sep 30, 2022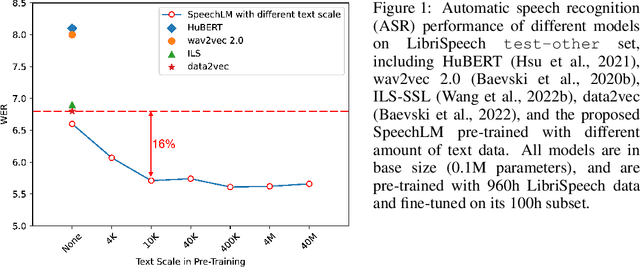
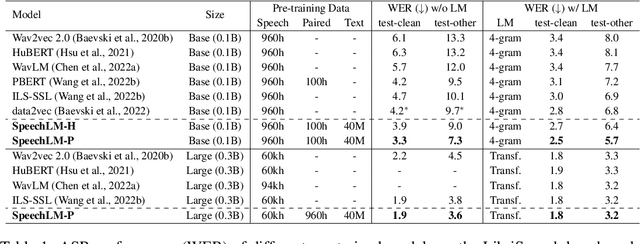
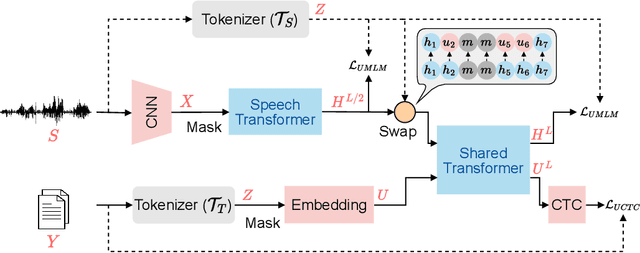
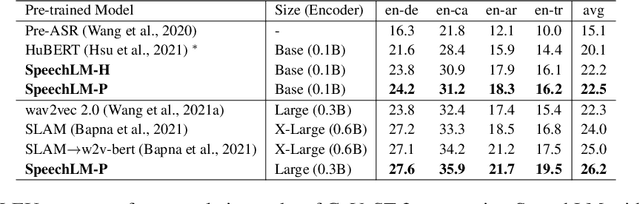
How to boost speech pre-training with textual data is an unsolved problem due to the fact that speech and text are very different modalities with distinct characteristics. In this paper, we propose a cross-modal Speech and Language Model (SpeechLM) to explicitly align speech and text pre-training with a pre-defined unified discrete representation. Specifically, we introduce two alternative discrete tokenizers to bridge the speech and text modalities, including phoneme-unit and hidden-unit tokenizers, which can be trained using a small amount of paired speech-text data. Based on the trained tokenizers, we convert the unlabeled speech and text data into tokens of phoneme units or hidden units. The pre-training objective is designed to unify the speech and the text into the same discrete semantic space with a unified Transformer network. Leveraging only 10K text sentences, our SpeechLM gets a 16\% relative WER reduction over the best base model performance (from 6.8 to 5.7) on the public LibriSpeech ASR benchmark. Moreover, SpeechLM with fewer parameters even outperforms previous SOTA models on CoVoST-2 speech translation tasks. We also evaluate our SpeechLM on various spoken language processing tasks under the universal representation evaluation framework SUPERB, demonstrating significant improvements on content-related tasks. Our code and models are available at https://aka.ms/SpeechLM.
Speech Pre-training with Acoustic Piece
Apr 07, 2022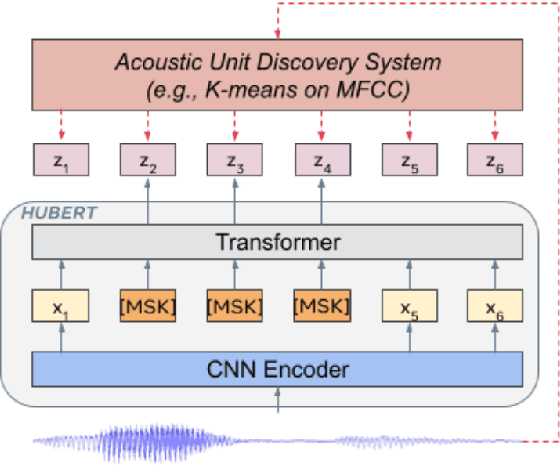

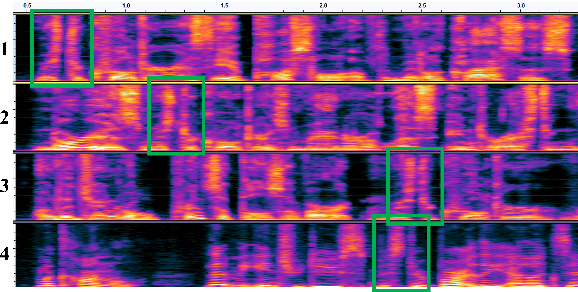
Previous speech pre-training methods, such as wav2vec2.0 and HuBERT, pre-train a Transformer encoder to learn deep representations from audio data, with objectives predicting either elements from latent vector quantized space or pre-generated labels (known as target codes) with offline clustering. However, those training signals (quantized elements or codes) are independent across different tokens without considering their relations. According to our observation and analysis, the target codes share obvious patterns aligned with phonemized text data. Based on that, we propose to leverage those patterns to better pre-train the model considering the relations among the codes. The patterns we extracted, called "acoustic piece"s, are from the sentence piece result of HuBERT codes. With the acoustic piece as the training signal, we can implicitly bridge the input audio and natural language, which benefits audio-to-text tasks, such as automatic speech recognition (ASR). Simple but effective, our method "HuBERT-AP" significantly outperforms strong baselines on the LibriSpeech ASR task.
KESA: A Knowledge Enhanced Approach For Sentiment Analysis
Feb 24, 2022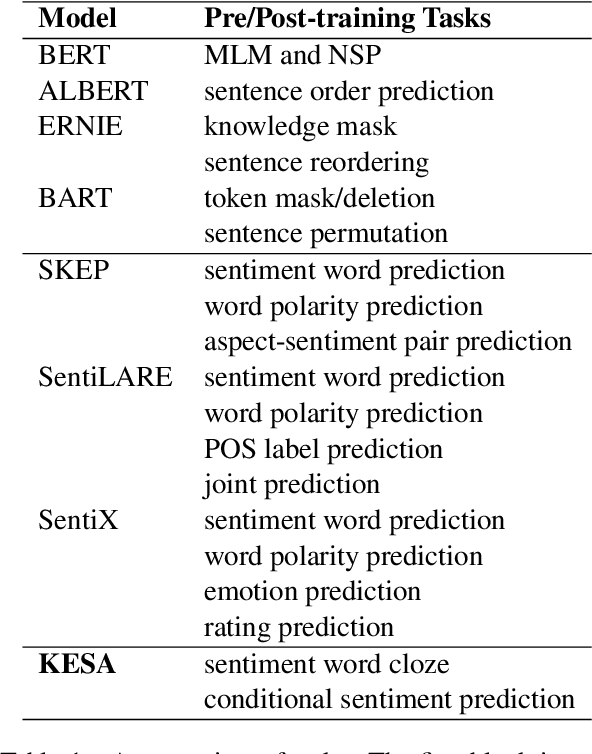
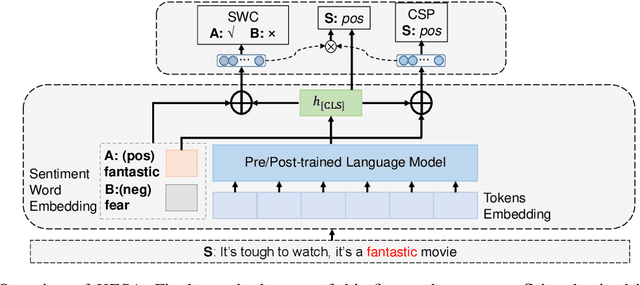
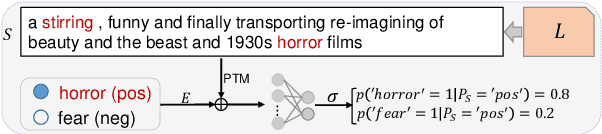

Though some recent works focus on injecting sentiment knowledge into pre-trained language models, they usually design mask and reconstruction tasks in the post-training phase. In this paper, we aim to benefit from sentiment knowledge in a lighter way. To achieve this goal, we study sentence-level sentiment analysis and, correspondingly, propose two sentiment-aware auxiliary tasks named sentiment word cloze and conditional sentiment prediction. The first task learns to select the correct sentiment words within the input, given the overall sentiment polarity as prior knowledge. On the contrary, the second task predicts the overall sentiment polarity given the sentiment polarity of the word as prior knowledge. In addition, two kinds of label combination methods are investigated to unify multiple types of labels in each task. We argue that more information can promote the models to learn more profound semantic representation. We implement it in a straightforward way to verify this hypothesis. The experimental results demonstrate that our approach consistently outperforms pre-trained models and is additive to existing knowledge-enhanced post-trained models. The code and data are released at https://github.com/lshowway/KESA.
WavLM: Large-Scale Self-Supervised Pre-Training for Full Stack Speech Processing
Oct 29, 2021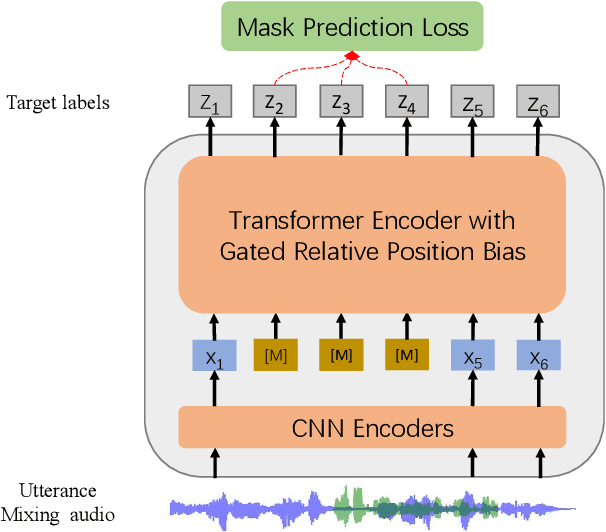
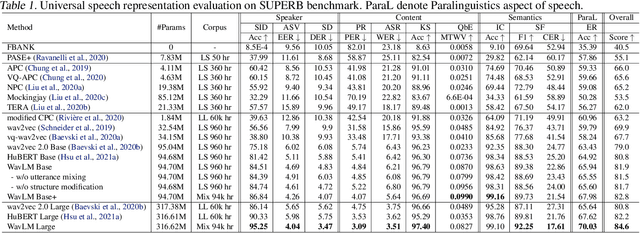
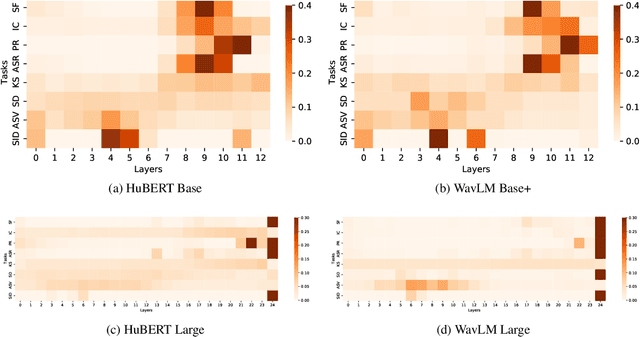
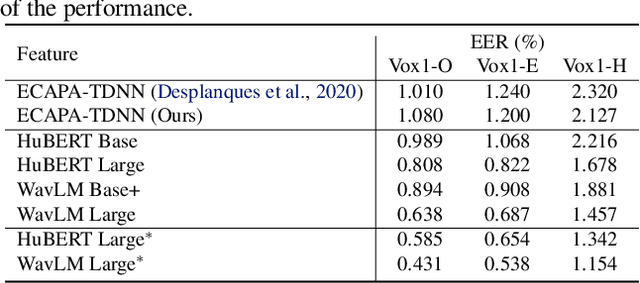
Self-supervised learning (SSL) achieves great success in speech recognition, while limited exploration has been attempted for other speech processing tasks. As speech signal contains multi-faceted information including speaker identity, paralinguistics, spoken content, etc., learning universal representations for all speech tasks is challenging. In this paper, we propose a new pre-trained model, WavLM, to solve full-stack downstream speech tasks. WavLM is built based on the HuBERT framework, with an emphasis on both spoken content modeling and speaker identity preservation. We first equip the Transformer structure with gated relative position bias to improve its capability on recognition tasks. For better speaker discrimination, we propose an utterance mixing training strategy, where additional overlapped utterances are created unsupervisely and incorporated during model training. Lastly, we scale up the training dataset from 60k hours to 94k hours. WavLM Large achieves state-of-the-art performance on the SUPERB benchmark, and brings significant improvements for various speech processing tasks on their representative benchmarks. The code and pretrained models are available at https://aka.ms/wavlm.
Optimizing Alignment of Speech and Language Latent Spaces for End-to-End Speech Recognition and Understanding
Oct 23, 2021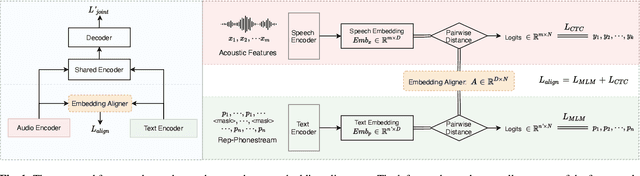
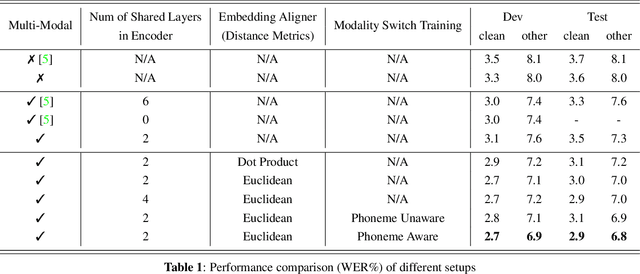
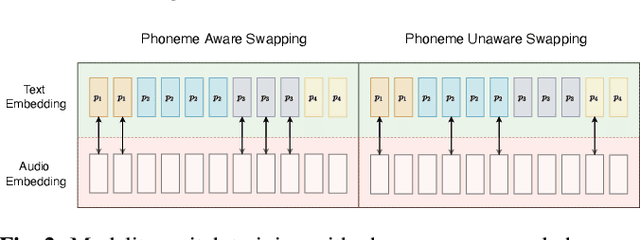
The advances in attention-based encoder-decoder (AED) networks have brought great progress to end-to-end (E2E) automatic speech recognition (ASR). One way to further improve the performance of AED-based E2E ASR is to introduce an extra text encoder for leveraging extensive text data and thus capture more context-aware linguistic information. However, this approach brings a mismatch problem between the speech encoder and the text encoder due to the different units used for modeling. In this paper, we propose an embedding aligner and modality switch training to better align the speech and text latent spaces. The embedding aligner is a shared linear projection between text encoder and speech encoder trained by masked language modeling (MLM) loss and connectionist temporal classification (CTC), respectively. The modality switch training randomly swaps speech and text embeddings based on the forced alignment result to learn a joint representation space. Experimental results show that our proposed approach achieves a relative 14% to 19% word error rate (WER) reduction on Librispeech ASR task. We further verify its effectiveness on spoken language understanding (SLU), i.e., an absolute 2.5% to 2.8% F1 score improvement on SNIPS slot filling task.
SpeechT5: Unified-Modal Encoder-Decoder Pre-training for Spoken Language Processing
Oct 14, 2021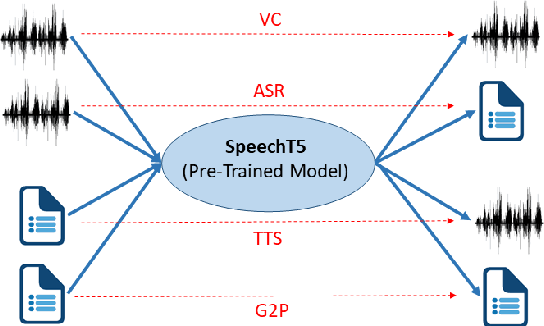
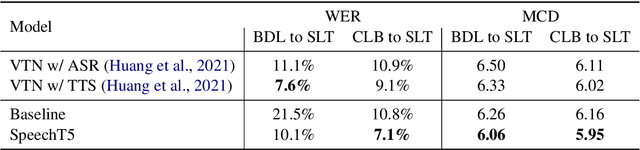
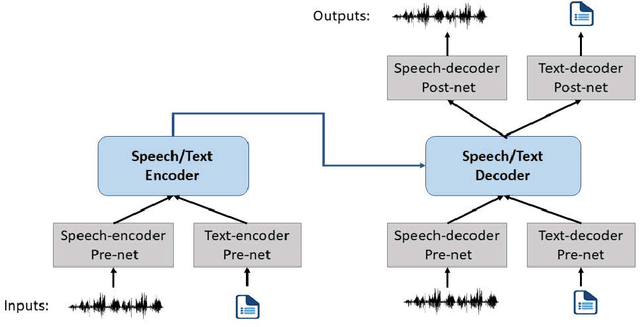
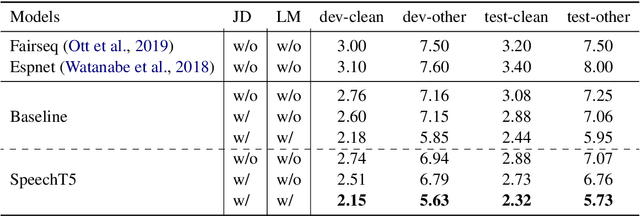
Motivated by the success of T5 (Text-To-Text Transfer Transformer) in pre-training natural language processing models, we propose a unified-modal SpeechT5 framework that explores the encoder-decoder pre-training for self-supervised speech/text representation learning. The SpeechT5 framework consists of a shared encoder-decoder network and six modal-specific (speech/text) pre/post-nets. After preprocessing the speech/text input through the pre-nets, the shared encoder-decoder network models the sequence to sequence transformation, and then the post-nets generate the output in the speech/text modality based on the decoder output. Particularly, SpeechT5 can pre-train on a large scale of unlabeled speech and text data to improve the capability of the speech and textual modeling. To align the textual and speech information into a unified semantic space, we propose a cross-modal vector quantization method with random mixing-up to bridge speech and text. Extensive evaluations on a wide variety of spoken language processing tasks, including voice conversion, automatic speech recognition, text to speech, and speaker identification, show the superiority of the proposed SpeechT5 framework.