 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTowards Scientific Intelligence: A Survey of LLM-based Scientific Agents
Mar 31, 2025



As scientific research becomes increasingly complex, innovative tools are needed to manage vast data, facilitate interdisciplinary collaboration, and accelerate discovery. Large language models (LLMs) are now evolving into LLM-based scientific agents that automate critical tasks, ranging from hypothesis generation and experiment design to data analysis and simulation. Unlike general-purpose LLMs, these specialized agents integrate domain-specific knowledge, advanced tool sets, and robust validation mechanisms, enabling them to handle complex data types, ensure reproducibility, and drive scientific breakthroughs. This survey provides a focused review of the architectures, design, benchmarks, applications, and ethical considerations surrounding LLM-based scientific agents. We highlight why they differ from general agents and the ways in which they advance research across various scientific fields. By examining their development and challenges, this survey offers a comprehensive roadmap for researchers and practitioners to harness these agents for more efficient, reliable, and ethically sound scientific discovery.
LR${}^{2}$Bench: Evaluating Long-chain Reflective Reasoning Capabilities of Large Language Models via Constraint Satisfaction Problems
Feb 25, 2025

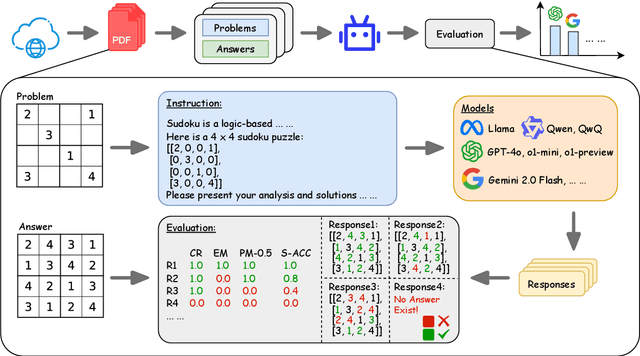

Recent progress in o1-like models has significantly enhanced the reasoning abilities of Large Language Models (LLMs), empowering them to tackle increasingly complex tasks through reflection capabilities, such as making assumptions, backtracking, and self-refinement. However, effectively evaluating such reflection capabilities remains challenging due to the lack of appropriate benchmarks. To bridge this gap, we introduce LR${}^{2}$Bench, a novel benchmark designed to evaluate the Long-chain Reflective Reasoning capabilities of LLMs. LR${}^{2}$Bench comprises 850 samples across six Constraint Satisfaction Problems (CSPs) where reflective reasoning is crucial for deriving solutions that meet all given constraints. Each type of task focuses on distinct constraint patterns, such as knowledge-based, logical, and spatial constraints, providing a comprehensive evaluation of diverse problem-solving scenarios. We conduct extensive evaluation on both conventional models and o1-like models. Our experimental results reveal that even the most advanced reasoning-specific models, such as DeepSeek-R1 and OpenAI o1-preview, struggle with tasks in LR${}^{2}$Bench, achieving an average Exact Match score of only 20.0% and 23.6%, respectively. These findings underscore the significant room for improvement in the reflective reasoning capabilities of current LLMs. The leaderboard of our benchmark is available at https://huggingface.co/spaces/UltraRonin/LR2Bench