 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLR${}^{2}$Bench: Evaluating Long-chain Reflective Reasoning Capabilities of Large Language Models via Constraint Satisfaction Problems
Feb 25, 2025

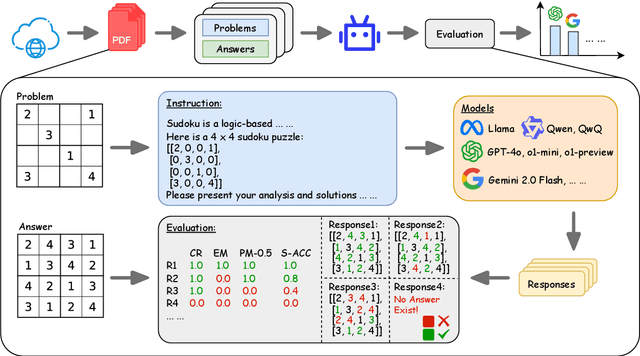

Recent progress in o1-like models has significantly enhanced the reasoning abilities of Large Language Models (LLMs), empowering them to tackle increasingly complex tasks through reflection capabilities, such as making assumptions, backtracking, and self-refinement. However, effectively evaluating such reflection capabilities remains challenging due to the lack of appropriate benchmarks. To bridge this gap, we introduce LR${}^{2}$Bench, a novel benchmark designed to evaluate the Long-chain Reflective Reasoning capabilities of LLMs. LR${}^{2}$Bench comprises 850 samples across six Constraint Satisfaction Problems (CSPs) where reflective reasoning is crucial for deriving solutions that meet all given constraints. Each type of task focuses on distinct constraint patterns, such as knowledge-based, logical, and spatial constraints, providing a comprehensive evaluation of diverse problem-solving scenarios. We conduct extensive evaluation on both conventional models and o1-like models. Our experimental results reveal that even the most advanced reasoning-specific models, such as DeepSeek-R1 and OpenAI o1-preview, struggle with tasks in LR${}^{2}$Bench, achieving an average Exact Match score of only 20.0% and 23.6%, respectively. These findings underscore the significant room for improvement in the reflective reasoning capabilities of current LLMs. The leaderboard of our benchmark is available at https://huggingface.co/spaces/UltraRonin/LR2Bench
ChineseWebText 2.0: Large-Scale High-quality Chinese Web Text with Multi-dimensional and fine-grained information
Nov 29, 2024



During the development of large language models (LLMs), pre-training data play a critical role in shaping LLMs' capabilities. In recent years several large-scale and high-quality pre-training datasets have been released to accelerate the research of LLMs, including ChineseWebText1.0, C4, Pile, WanJuan, MAPCC and others. However, as LLMs continue to evolve, focus has increasingly shifted to domain-specific capabilities and safety concerns, making those previous coarse-grained texts insufficient for meeting training requirements. Furthermore, fine-grained information, such as quality, domain and toxicity, is becoming increasingly important in building powerful and reliable LLMs for various scenarios. To address these challenges, in this paper we propose a new tool-chain called MDFG-tool for constructing large-scale and high-quality Chinese datasets with multi-dimensional and fine-grained information. First, we employ manually crafted rules to discard explicit noisy texts from raw contents. Second, the quality evaluation model, domain classifier, and toxicity evaluation model are well-designed to assess the remaining cleaned data respectively. Finally, we integrate these three types of fine-grained information for each text. With this approach, we release the largest, high-quality and fine-grained Chinese text ChineseWebText2.0, which consists of 3.8TB and each text is associated with a quality score, domain labels, a toxicity label and a toxicity score, facilitating the LLM researchers to select data based on various types of fine-grained information. The data, codes and the tool-chain are available on this website https://github.com/CASIA-LM/ChineseWebText-2.0