 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeKTAE: A Model-Free Algorithm to Key-Tokens Advantage Estimation in Mathematical Reasoning
May 22, 2025Recent advances have demonstrated that integrating reinforcement learning with rule-based rewards can significantly enhance the reasoning capabilities of large language models, even without supervised fine-tuning. However, prevalent reinforcement learning algorithms such as GRPO and its variants like DAPO, suffer from a coarse granularity issue when computing the advantage. Specifically, they compute rollout-level advantages that assign identical values to every token within a sequence, failing to capture token-specific contributions and hindering effective learning. To address this limitation, we propose Key-token Advantage Estimation (KTAE) - a novel algorithm that estimates fine-grained, token-level advantages without introducing additional models. KTAE leverages the correctness of sampled rollouts and applies statistical analysis to quantify the importance of individual tokens within a sequence to the final outcome. This quantified token-level importance is then combined with the rollout-level advantage to obtain a more fine-grained token-level advantage estimation. Empirical results show that models trained with GRPO+KTAE and DAPO+KTAE outperform baseline methods across five mathematical reasoning benchmarks. Notably, they achieve higher accuracy with shorter responses and even surpass R1-Distill-Qwen-1.5B using the same base model.
An Efficient and Precise Training Data Construction Framework for Process-supervised Reward Model in Mathematical Reasoning
Mar 04, 2025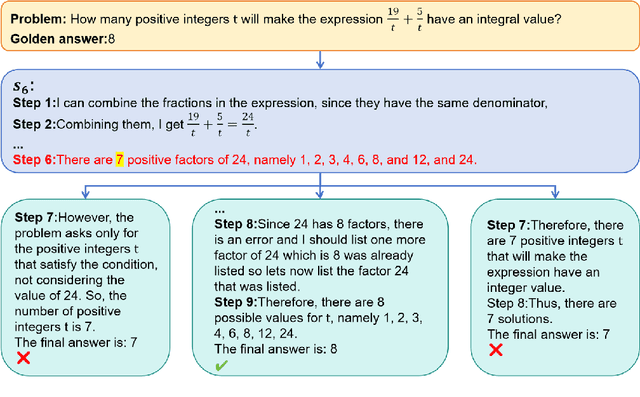
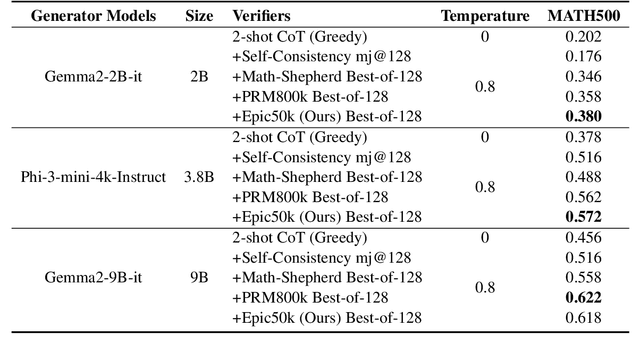
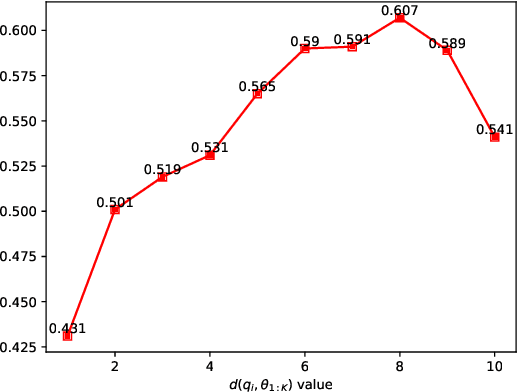

Enhancing the mathematical reasoning capabilities of Large Language Models (LLMs) is of great scientific and practical significance. Researchers typically employ process-supervised reward models (PRMs) to guide the reasoning process, effectively improving the models' reasoning abilities. However, existing methods for constructing process supervision training data, such as manual annotation and per-step Monte Carlo estimation, are often costly or suffer from poor quality. To address these challenges, this paper introduces a framework called EpicPRM, which annotates each intermediate reasoning step based on its quantified contribution and uses an adaptive binary search algorithm to enhance both annotation precision and efficiency. Using this approach, we efficiently construct a high-quality process supervision training dataset named Epic50k, consisting of 50k annotated intermediate steps. Compared to other publicly available datasets, the PRM trained on Epic50k demonstrates significantly superior performance. Getting Epic50k at https://github.com/xiaolizh1/EpicPRM.
ChineseWebText 2.0: Large-Scale High-quality Chinese Web Text with Multi-dimensional and fine-grained information
Nov 29, 2024



During the development of large language models (LLMs), pre-training data play a critical role in shaping LLMs' capabilities. In recent years several large-scale and high-quality pre-training datasets have been released to accelerate the research of LLMs, including ChineseWebText1.0, C4, Pile, WanJuan, MAPCC and others. However, as LLMs continue to evolve, focus has increasingly shifted to domain-specific capabilities and safety concerns, making those previous coarse-grained texts insufficient for meeting training requirements. Furthermore, fine-grained information, such as quality, domain and toxicity, is becoming increasingly important in building powerful and reliable LLMs for various scenarios. To address these challenges, in this paper we propose a new tool-chain called MDFG-tool for constructing large-scale and high-quality Chinese datasets with multi-dimensional and fine-grained information. First, we employ manually crafted rules to discard explicit noisy texts from raw contents. Second, the quality evaluation model, domain classifier, and toxicity evaluation model are well-designed to assess the remaining cleaned data respectively. Finally, we integrate these three types of fine-grained information for each text. With this approach, we release the largest, high-quality and fine-grained Chinese text ChineseWebText2.0, which consists of 3.8TB and each text is associated with a quality score, domain labels, a toxicity label and a toxicity score, facilitating the LLM researchers to select data based on various types of fine-grained information. The data, codes and the tool-chain are available on this website https://github.com/CASIA-LM/ChineseWebText-2.0
A Survey on Data Selection for LLM Instruction Tuning
Feb 04, 2024



Instruction tuning is a vital step of training large language models (LLM), so how to enhance the effect of instruction tuning has received increased attention. Existing works indicate that the quality of the dataset is more crucial than the quantity during instruction tuning of LLM. Therefore, recently a lot of studies focus on exploring the methods of selecting high-quality subset from instruction datasets, aiming to reduce training costs and enhance the instruction-following capabilities of LLMs. This paper presents a comprehensive survey on data selection for LLM instruction tuning. Firstly, we introduce the wildly used instruction datasets. Then, we propose a new taxonomy of the data selection methods and provide a detailed introduction of recent advances,and the evaluation strategies and results of data selection methods are also elaborated in detail. Finally, we emphasize the open challenges and present new frontiers of this task.
MoDS: Model-oriented Data Selection for Instruction Tuning
Nov 27, 2023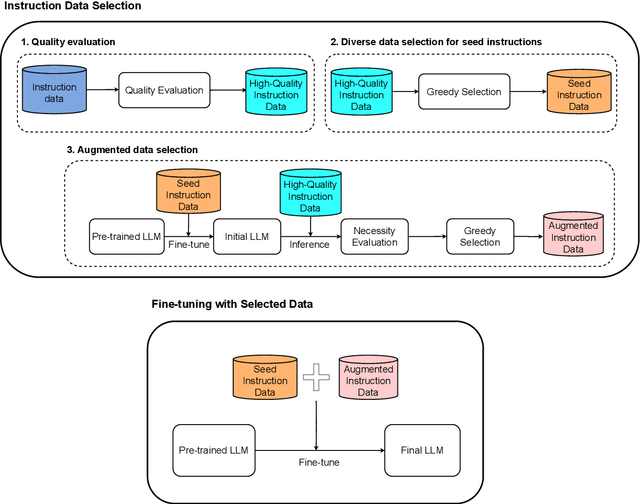


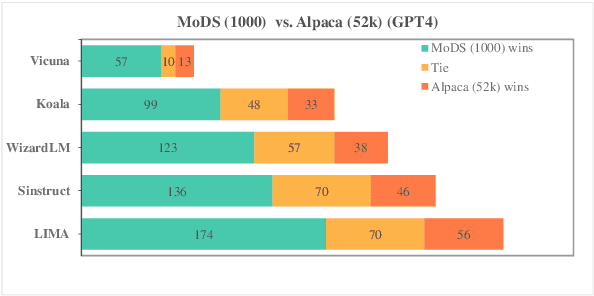
Instruction tuning has become the de facto method to equip large language models (LLMs) with the ability of following user instructions. Usually, hundreds of thousands or millions of instruction-following pairs are employed to fine-tune the foundation LLMs. Recently, some studies show that a small number of high-quality instruction data is enough. However, how to select appropriate instruction data for a given LLM is still an open problem. To address this problem, in this paper we present a model-oriented data selection (MoDS) approach, which selects instruction data based on a new criteria considering three aspects: quality, coverage and necessity. First, our approach utilizes a quality evaluation model to filter out the high-quality subset from the original instruction dataset, and then designs an algorithm to further select from the high-quality subset a seed instruction dataset with good coverage. The seed dataset is applied to fine-tune the foundation LLM to obtain an initial instruction-following LLM. Finally, we develop a necessity evaluation model to find out the instruction data which are performed badly in the initial instruction-following LLM and consider them necessary instructions to further improve the LLMs. In this way, we can get a small high-quality, broad-coverage and high-necessity subset from the original instruction datasets. Experimental results show that, the model fine-tuned with 4,000 instruction pairs selected by our approach could perform better than the model fine-tuned with the full original dataset which includes 214k instruction data.
ChineseWebText: Large-scale High-quality Chinese Web Text Extracted with Effective Evaluation Model
Nov 10, 2023During the development of large language models (LLMs), the scale and quality of the pre-training data play a crucial role in shaping LLMs' capabilities. To accelerate the research of LLMs, several large-scale datasets, such as C4 [1], Pile [2], RefinedWeb [3] and WanJuan [4], have been released to the public. However, most of the released corpus focus mainly on English, and there is still lack of complete tool-chain for extracting clean texts from web data. Furthermore, fine-grained information of the corpus, e.g. the quality of each text, is missing. To address these challenges, we propose in this paper a new complete tool-chain EvalWeb to extract Chinese clean texts from noisy web data. First, similar to previous work, manually crafted rules are employed to discard explicit noisy texts from the raw crawled web contents. Second, a well-designed evaluation model is leveraged to assess the remaining relatively clean data, and each text is assigned a specific quality score. Finally, we can easily utilize an appropriate threshold to select the high-quality pre-training data for Chinese. Using our proposed approach, we release the largest and latest large-scale high-quality Chinese web text ChineseWebText, which consists of 1.42 TB and each text is associated with a quality score, facilitating the LLM researchers to choose the data according to the desired quality thresholds. We also release a much cleaner subset of 600 GB Chinese data with the quality exceeding 90%.