 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeACE-RL: Adaptive Constraint-Enhanced Reward for Long-form Generation Reinforcement Learning
Sep 05, 2025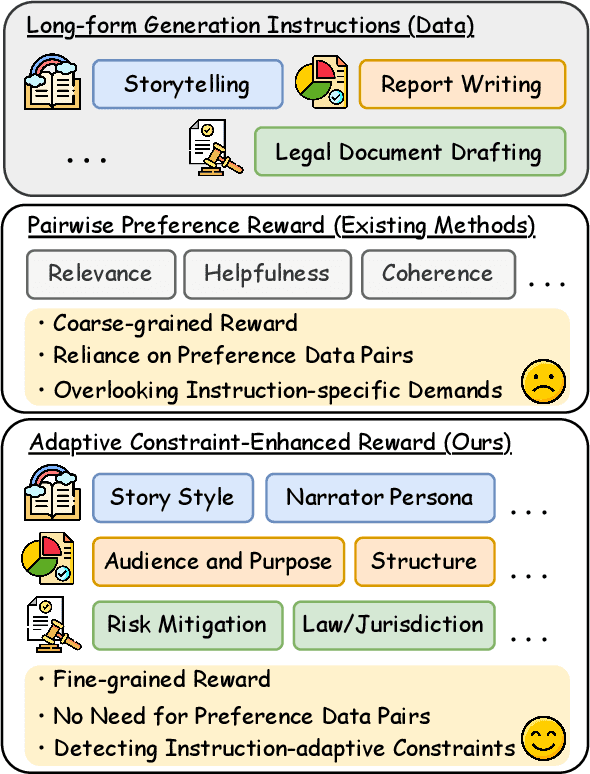

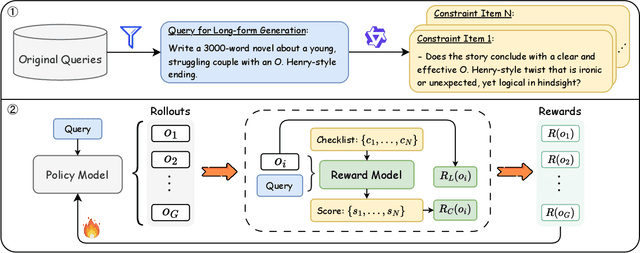
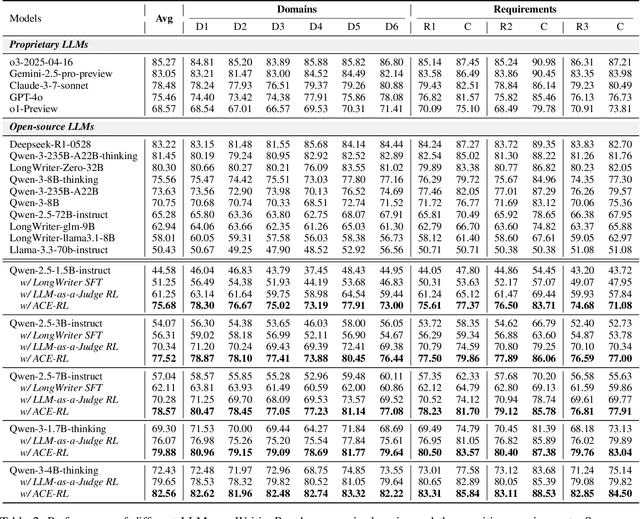
Large Language Models (LLMs) have demonstrated remarkable progress in long-context understanding, yet they face significant challenges in high-quality long-form generation. Existing studies primarily suffer from two limitations: (1) A heavy reliance on scarce, high-quality long-form response data for supervised fine-tuning (SFT) or for pairwise preference reward in reinforcement learning (RL). (2) Focus on coarse-grained quality optimization dimensions, such as relevance, coherence, and helpfulness, overlooking the fine-grained specifics inherent to diverse long-form generation scenarios. To address this issue, we propose a framework using Adaptive Constraint-Enhanced reward for long-form generation Reinforcement Learning (ACE-RL). ACE-RL first automatically deconstructs each instruction into a set of fine-grained, adaptive constraint criteria by identifying its underlying intents and demands. Subsequently, we design a reward mechanism that quantifies the quality of long-form responses based on their satisfaction over corresponding constraints, converting subjective quality evaluation into constraint verification. Finally, we utilize reinforcement learning to guide models toward superior long-form generation capabilities. Experimental results demonstrate that our ACE-RL framework significantly outperforms existing SFT and RL baselines by 20.70% and 7.32% on WritingBench, and our top-performing model even surpasses proprietary systems like GPT-4o by 7.10%, providing a more effective training paradigm for LLMs to generate high-quality content across diverse long-form generation scenarios.
LADM: Long-context Training Data Selection with Attention-based Dependency Measurement for LLMs
Mar 04, 2025



Long-context modeling has drawn more and more attention in the area of Large Language Models (LLMs). Continual training with long-context data becomes the de-facto method to equip LLMs with the ability to process long inputs. However, it still remains an open challenge to measure the quality of long-context training data. To address this issue, we propose a Long-context data selection framework with Attention-based Dependency Measurement (LADM), which can efficiently identify high-quality long-context data from a large-scale, multi-domain pre-training corpus. LADM leverages the retrieval capabilities of the attention mechanism to capture contextual dependencies, ensuring a comprehensive quality measurement of long-context data. Experimental results show that our LADM framework significantly boosts the performance of LLMs on multiple long-context tasks with only 1B tokens for continual training.
LR${}^{2}$Bench: Evaluating Long-chain Reflective Reasoning Capabilities of Large Language Models via Constraint Satisfaction Problems
Feb 25, 2025

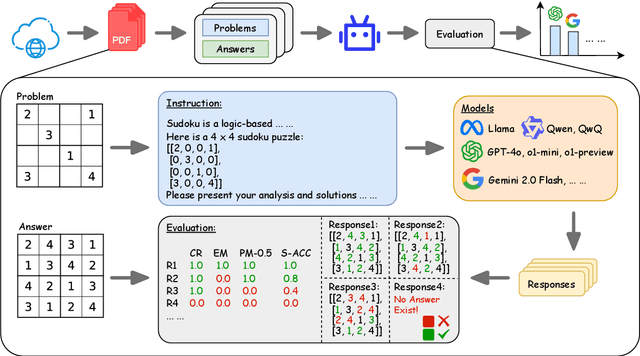

Recent progress in o1-like models has significantly enhanced the reasoning abilities of Large Language Models (LLMs), empowering them to tackle increasingly complex tasks through reflection capabilities, such as making assumptions, backtracking, and self-refinement. However, effectively evaluating such reflection capabilities remains challenging due to the lack of appropriate benchmarks. To bridge this gap, we introduce LR${}^{2}$Bench, a novel benchmark designed to evaluate the Long-chain Reflective Reasoning capabilities of LLMs. LR${}^{2}$Bench comprises 850 samples across six Constraint Satisfaction Problems (CSPs) where reflective reasoning is crucial for deriving solutions that meet all given constraints. Each type of task focuses on distinct constraint patterns, such as knowledge-based, logical, and spatial constraints, providing a comprehensive evaluation of diverse problem-solving scenarios. We conduct extensive evaluation on both conventional models and o1-like models. Our experimental results reveal that even the most advanced reasoning-specific models, such as DeepSeek-R1 and OpenAI o1-preview, struggle with tasks in LR${}^{2}$Bench, achieving an average Exact Match score of only 20.0% and 23.6%, respectively. These findings underscore the significant room for improvement in the reflective reasoning capabilities of current LLMs. The leaderboard of our benchmark is available at https://huggingface.co/spaces/UltraRonin/LR2Bench
Hit the Sweet Spot! Span-Level Ensemble for Large Language Models
Sep 27, 2024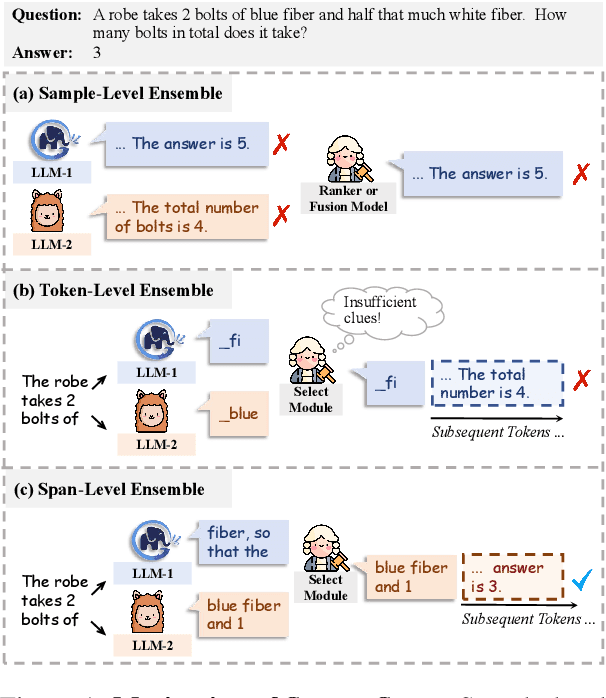
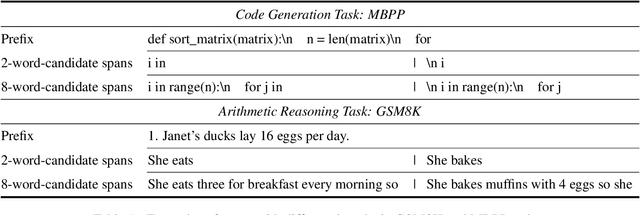
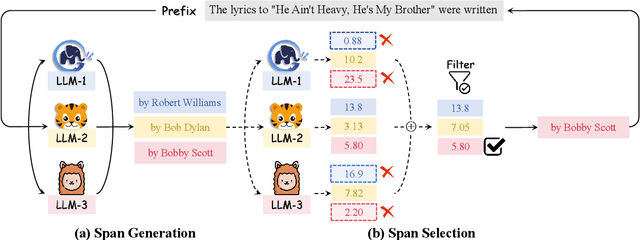

Ensembling various LLMs to unlock their complementary potential and leverage their individual strengths is highly valuable. Previous studies typically focus on two main paradigms: sample-level and token-level ensembles. Sample-level ensemble methods either select or blend fully generated outputs, which hinders dynamic correction and enhancement of outputs during the generation process. On the other hand, token-level ensemble methods enable real-time correction through fine-grained ensemble at each generation step. However, the information carried by an individual token is quite limited, leading to suboptimal decisions at each step. To address these issues, we propose SweetSpan, a span-level ensemble method that effectively balances the need for real-time adjustments and the information required for accurate ensemble decisions. Our approach involves two key steps: First, we have each candidate model independently generate candidate spans based on the shared prefix. Second, we calculate perplexity scores to facilitate mutual evaluation among the candidate models and achieve robust span selection by filtering out unfaithful scores. To comprehensively evaluate ensemble methods, we propose a new challenging setting (ensemble models with significant performance gaps) in addition to the standard setting (ensemble the best-performing models) to assess the performance of model ensembles in more realistic scenarios. Experimental results in both standard and challenging settings across various language generation tasks demonstrate the effectiveness, robustness, and versatility of our approach compared with previous ensemble methods.
ChineseWebText: Large-scale High-quality Chinese Web Text Extracted with Effective Evaluation Model
Nov 10, 2023During the development of large language models (LLMs), the scale and quality of the pre-training data play a crucial role in shaping LLMs' capabilities. To accelerate the research of LLMs, several large-scale datasets, such as C4 [1], Pile [2], RefinedWeb [3] and WanJuan [4], have been released to the public. However, most of the released corpus focus mainly on English, and there is still lack of complete tool-chain for extracting clean texts from web data. Furthermore, fine-grained information of the corpus, e.g. the quality of each text, is missing. To address these challenges, we propose in this paper a new complete tool-chain EvalWeb to extract Chinese clean texts from noisy web data. First, similar to previous work, manually crafted rules are employed to discard explicit noisy texts from the raw crawled web contents. Second, a well-designed evaluation model is leveraged to assess the remaining relatively clean data, and each text is assigned a specific quality score. Finally, we can easily utilize an appropriate threshold to select the high-quality pre-training data for Chinese. Using our proposed approach, we release the largest and latest large-scale high-quality Chinese web text ChineseWebText, which consists of 1.42 TB and each text is associated with a quality score, facilitating the LLM researchers to choose the data according to the desired quality thresholds. We also release a much cleaner subset of 600 GB Chinese data with the quality exceeding 90%.