 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLADM: Long-context Training Data Selection with Attention-based Dependency Measurement for LLMs
Mar 04, 2025



Long-context modeling has drawn more and more attention in the area of Large Language Models (LLMs). Continual training with long-context data becomes the de-facto method to equip LLMs with the ability to process long inputs. However, it still remains an open challenge to measure the quality of long-context training data. To address this issue, we propose a Long-context data selection framework with Attention-based Dependency Measurement (LADM), which can efficiently identify high-quality long-context data from a large-scale, multi-domain pre-training corpus. LADM leverages the retrieval capabilities of the attention mechanism to capture contextual dependencies, ensuring a comprehensive quality measurement of long-context data. Experimental results show that our LADM framework significantly boosts the performance of LLMs on multiple long-context tasks with only 1B tokens for continual training.
Boosting LLM Translation Skills without General Ability Loss via Rationale Distillation
Oct 17, 2024



Large Language Models (LLMs) have achieved impressive results across numerous NLP tasks but still encounter difficulties in machine translation. Traditional methods to improve translation have typically involved fine-tuning LLMs using parallel corpora. However, vanilla fine-tuning often leads to catastrophic forgetting of the instruction-following capabilities and alignment with human preferences, compromising their broad general abilities and introducing potential security risks. These abilities, which are developed using proprietary and unavailable training data, make existing continual instruction tuning methods ineffective. To overcome this issue, we propose a novel approach called RaDis (Rationale Distillation). RaDis harnesses the strong generative capabilities of LLMs to create rationales for training data, which are then "replayed" to prevent forgetting. These rationales encapsulate general knowledge and safety principles, acting as self-distillation targets to regulate the training process. By jointly training on both reference translations and self-generated rationales, the model can learn new translation skills while preserving its overall general abilities. Extensive experiments demonstrate that our method enhances machine translation performance while maintaining the broader capabilities of LLMs across other tasks. This work presents a pathway for creating more versatile LLMs that excel in specialized tasks without compromising generality and safety.
Hit the Sweet Spot! Span-Level Ensemble for Large Language Models
Sep 27, 2024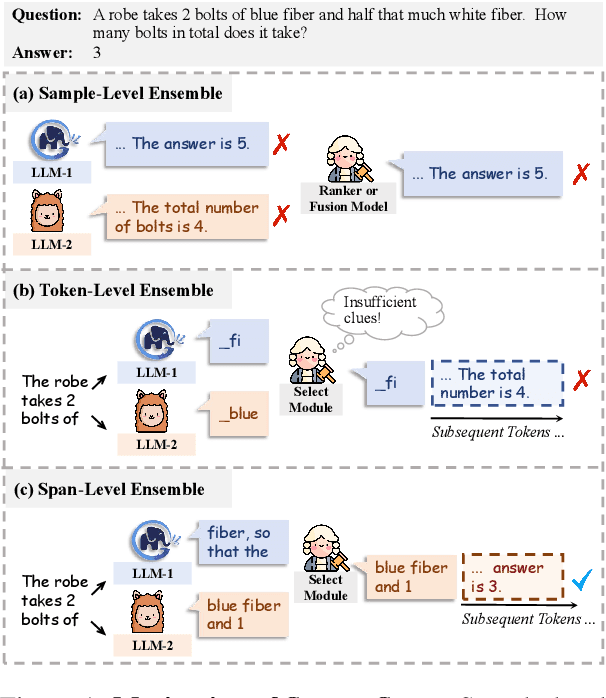
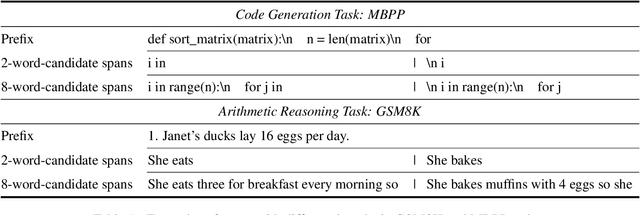
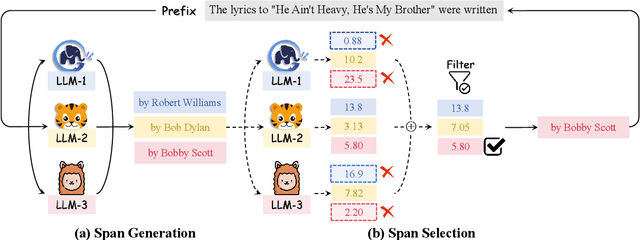

Ensembling various LLMs to unlock their complementary potential and leverage their individual strengths is highly valuable. Previous studies typically focus on two main paradigms: sample-level and token-level ensembles. Sample-level ensemble methods either select or blend fully generated outputs, which hinders dynamic correction and enhancement of outputs during the generation process. On the other hand, token-level ensemble methods enable real-time correction through fine-grained ensemble at each generation step. However, the information carried by an individual token is quite limited, leading to suboptimal decisions at each step. To address these issues, we propose SweetSpan, a span-level ensemble method that effectively balances the need for real-time adjustments and the information required for accurate ensemble decisions. Our approach involves two key steps: First, we have each candidate model independently generate candidate spans based on the shared prefix. Second, we calculate perplexity scores to facilitate mutual evaluation among the candidate models and achieve robust span selection by filtering out unfaithful scores. To comprehensively evaluate ensemble methods, we propose a new challenging setting (ensemble models with significant performance gaps) in addition to the standard setting (ensemble the best-performing models) to assess the performance of model ensembles in more realistic scenarios. Experimental results in both standard and challenging settings across various language generation tasks demonstrate the effectiveness, robustness, and versatility of our approach compared with previous ensemble methods.
Bridging the Gap between Different Vocabularies for LLM Ensemble
Apr 15, 2024
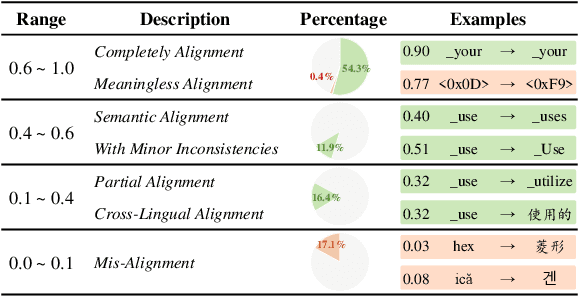
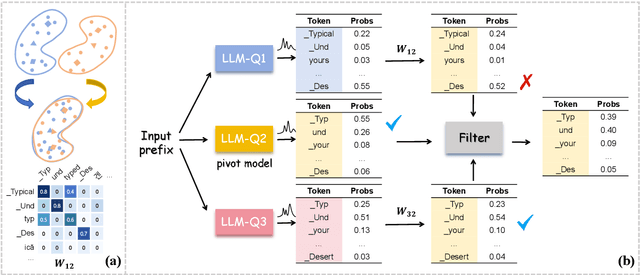
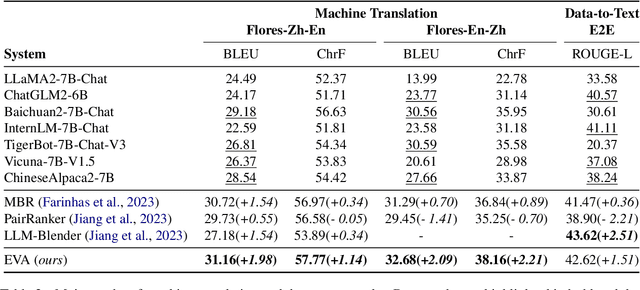
Ensembling different large language models (LLMs) to unleash their complementary potential and harness their individual strengths is highly valuable. Nevertheless, vocabulary discrepancies among various LLMs have constrained previous studies to either selecting or blending completely generated outputs. This limitation hinders the dynamic correction and enhancement of outputs during the generation process, resulting in a limited capacity for effective ensemble. To address this issue, we propose a novel method to Ensemble LLMs via Vocabulary Alignment (EVA). EVA bridges the lexical gap among various LLMs, enabling meticulous ensemble at each generation step. Specifically, we first learn mappings between the vocabularies of different LLMs with the assistance of overlapping tokens. Subsequently, these mappings are employed to project output distributions of LLMs into a unified space, facilitating a fine-grained ensemble. Finally, we design a filtering strategy to exclude models that generate unfaithful tokens. Experimental results on commonsense reasoning, arithmetic reasoning, machine translation, and data-to-text generation tasks demonstrate the superiority of our approach compared with individual LLMs and previous ensemble methods conducted on complete outputs. Further analyses confirm that our approach can leverage knowledge from different language models and yield consistent improvement.
Bilingual Mutual Information Based Adaptive Training for Neural Machine Translation
May 27, 2021

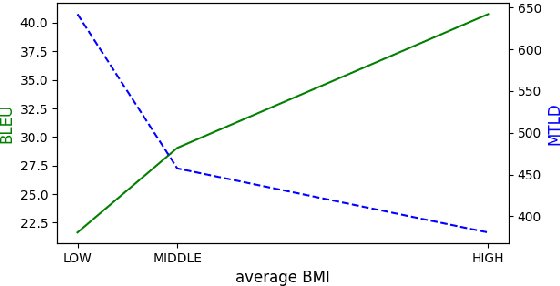
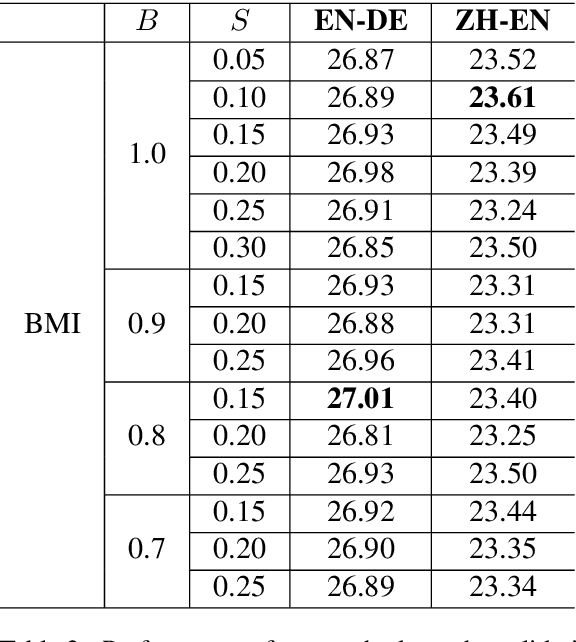
Recently, token-level adaptive training has achieved promising improvement in machine translation, where the cross-entropy loss function is adjusted by assigning different training weights to different tokens, in order to alleviate the token imbalance problem. However, previous approaches only use static word frequency information in the target language without considering the source language, which is insufficient for bilingual tasks like machine translation. In this paper, we propose a novel bilingual mutual information (BMI) based adaptive objective, which measures the learning difficulty for each target token from the perspective of bilingualism, and assigns an adaptive weight accordingly to improve token-level adaptive training. This method assigns larger training weights to tokens with higher BMI, so that easy tokens are updated with coarse granularity while difficult tokens are updated with fine granularity. Experimental results on WMT14 English-to-German and WMT19 Chinese-to-English demonstrate the superiority of our approach compared with the Transformer baseline and previous token-level adaptive training approaches. Further analyses confirm that our method can improve the lexical diversity.