 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMoDS: Model-oriented Data Selection for Instruction Tuning
Paper and Code
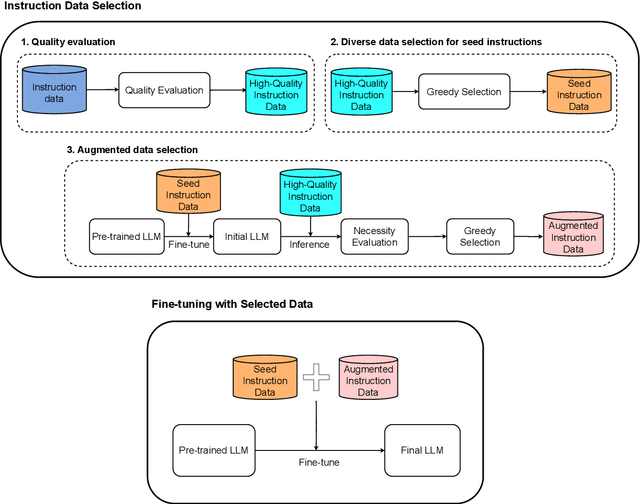


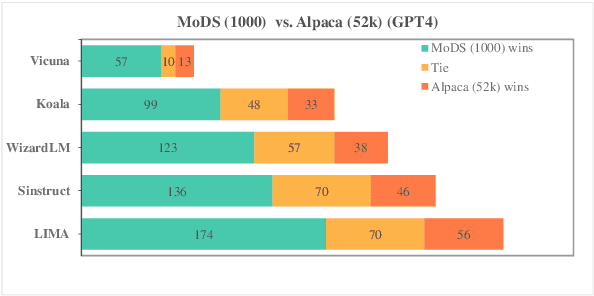
Instruction tuning has become the de facto method to equip large language models (LLMs) with the ability of following user instructions. Usually, hundreds of thousands or millions of instruction-following pairs are employed to fine-tune the foundation LLMs. Recently, some studies show that a small number of high-quality instruction data is enough. However, how to select appropriate instruction data for a given LLM is still an open problem. To address this problem, in this paper we present a model-oriented data selection (MoDS) approach, which selects instruction data based on a new criteria considering three aspects: quality, coverage and necessity. First, our approach utilizes a quality evaluation model to filter out the high-quality subset from the original instruction dataset, and then designs an algorithm to further select from the high-quality subset a seed instruction dataset with good coverage. The seed dataset is applied to fine-tune the foundation LLM to obtain an initial instruction-following LLM. Finally, we develop a necessity evaluation model to find out the instruction data which are performed badly in the initial instruction-following LLM and consider them necessary instructions to further improve the LLMs. In this way, we can get a small high-quality, broad-coverage and high-necessity subset from the original instruction datasets. Experimental results show that, the model fine-tuned with 4,000 instruction pairs selected by our approach could perform better than the model fine-tuned with the full original dataset which includes 214k instruction data.