 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeKTAE: A Model-Free Algorithm to Key-Tokens Advantage Estimation in Mathematical Reasoning
May 22, 2025Recent advances have demonstrated that integrating reinforcement learning with rule-based rewards can significantly enhance the reasoning capabilities of large language models, even without supervised fine-tuning. However, prevalent reinforcement learning algorithms such as GRPO and its variants like DAPO, suffer from a coarse granularity issue when computing the advantage. Specifically, they compute rollout-level advantages that assign identical values to every token within a sequence, failing to capture token-specific contributions and hindering effective learning. To address this limitation, we propose Key-token Advantage Estimation (KTAE) - a novel algorithm that estimates fine-grained, token-level advantages without introducing additional models. KTAE leverages the correctness of sampled rollouts and applies statistical analysis to quantify the importance of individual tokens within a sequence to the final outcome. This quantified token-level importance is then combined with the rollout-level advantage to obtain a more fine-grained token-level advantage estimation. Empirical results show that models trained with GRPO+KTAE and DAPO+KTAE outperform baseline methods across five mathematical reasoning benchmarks. Notably, they achieve higher accuracy with shorter responses and even surpass R1-Distill-Qwen-1.5B using the same base model.
An Efficient and Precise Training Data Construction Framework for Process-supervised Reward Model in Mathematical Reasoning
Mar 04, 2025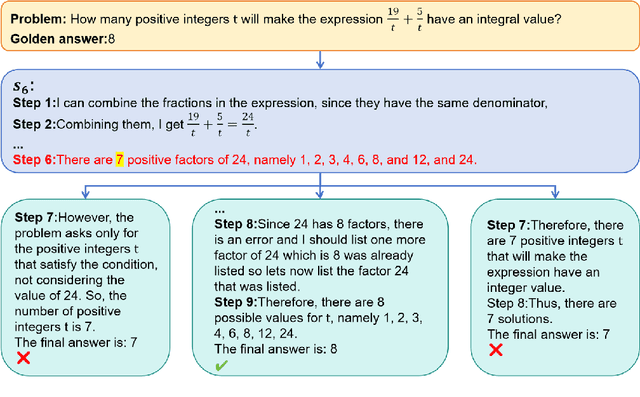
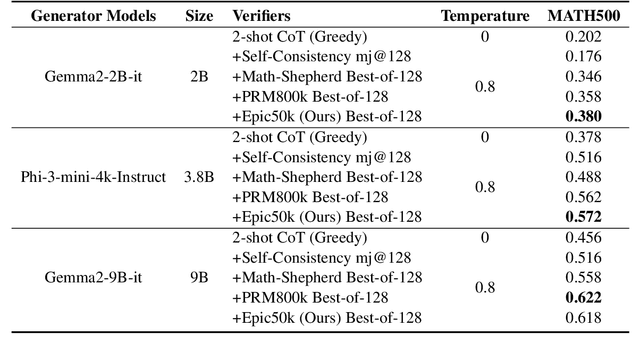
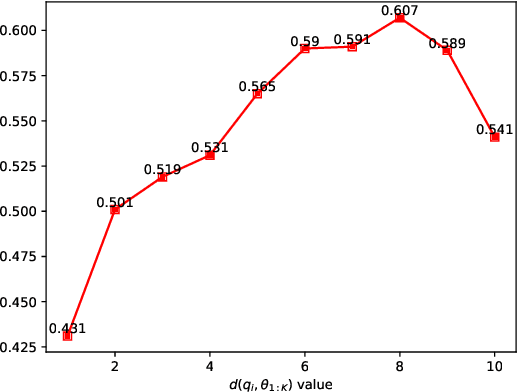

Enhancing the mathematical reasoning capabilities of Large Language Models (LLMs) is of great scientific and practical significance. Researchers typically employ process-supervised reward models (PRMs) to guide the reasoning process, effectively improving the models' reasoning abilities. However, existing methods for constructing process supervision training data, such as manual annotation and per-step Monte Carlo estimation, are often costly or suffer from poor quality. To address these challenges, this paper introduces a framework called EpicPRM, which annotates each intermediate reasoning step based on its quantified contribution and uses an adaptive binary search algorithm to enhance both annotation precision and efficiency. Using this approach, we efficiently construct a high-quality process supervision training dataset named Epic50k, consisting of 50k annotated intermediate steps. Compared to other publicly available datasets, the PRM trained on Epic50k demonstrates significantly superior performance. Getting Epic50k at https://github.com/xiaolizh1/EpicPRM.