 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSpeech Pre-training with Acoustic Piece
Paper and Code
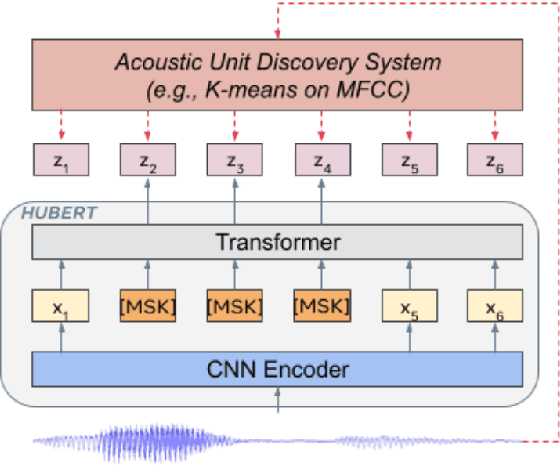

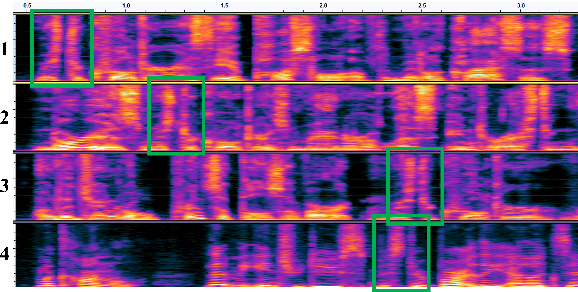
Previous speech pre-training methods, such as wav2vec2.0 and HuBERT, pre-train a Transformer encoder to learn deep representations from audio data, with objectives predicting either elements from latent vector quantized space or pre-generated labels (known as target codes) with offline clustering. However, those training signals (quantized elements or codes) are independent across different tokens without considering their relations. According to our observation and analysis, the target codes share obvious patterns aligned with phonemized text data. Based on that, we propose to leverage those patterns to better pre-train the model considering the relations among the codes. The patterns we extracted, called "acoustic piece"s, are from the sentence piece result of HuBERT codes. With the acoustic piece as the training signal, we can implicitly bridge the input audio and natural language, which benefits audio-to-text tasks, such as automatic speech recognition (ASR). Simple but effective, our method "HuBERT-AP" significantly outperforms strong baselines on the LibriSpeech ASR task.