 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVirtual Width Networks
Nov 17, 2025



We introduce Virtual Width Networks (VWN), a framework that delivers the benefits of wider representations without incurring the quadratic cost of increasing the hidden size. VWN decouples representational width from backbone width, expanding the embedding space while keeping backbone compute nearly constant. In our large-scale experiment, an 8-times expansion accelerates optimization by over 2 times for next-token and 3 times for next-2-token prediction. The advantage amplifies over training as both the loss gap grows and the convergence-speedup ratio increases, showing that VWN is not only token-efficient but also increasingly effective with scale. Moreover, we identify an approximately log-linear scaling relation between virtual width and loss reduction, offering an initial empirical basis and motivation for exploring virtual-width scaling as a new dimension of large-model efficiency.
Truncated Proximal Policy Optimization
Jun 18, 2025



Recently, test-time scaling Large Language Models (LLMs) have demonstrated exceptional reasoning capabilities across scientific and professional tasks by generating long chains-of-thought (CoT). As a crucial component for developing these reasoning models, reinforcement learning (RL), exemplified by Proximal Policy Optimization (PPO) and its variants, allows models to learn through trial and error. However, PPO can be time-consuming due to its inherent on-policy nature, which is further exacerbated by increasing response lengths. In this work, we propose Truncated Proximal Policy Optimization (T-PPO), a novel extension to PPO that improves training efficiency by streamlining policy update and length-restricted response generation. T-PPO mitigates the issue of low hardware utilization, an inherent drawback of fully synchronized long-generation procedures, where resources often sit idle during the waiting periods for complete rollouts. Our contributions are two-folds. First, we propose Extended Generalized Advantage Estimation (EGAE) for advantage estimation derived from incomplete responses while maintaining the integrity of policy learning. Second, we devise a computationally optimized mechanism that allows for the independent optimization of the policy and value models. By selectively filtering prompt and truncated tokens, this mechanism reduces redundant computations and accelerates the training process without sacrificing convergence performance. We demonstrate the effectiveness and efficacy of T-PPO on AIME 2024 with a 32B base model. The experimental results show that T-PPO improves the training efficiency of reasoning LLMs by up to 2.5x and outperforms its existing competitors.
VAPO: Efficient and Reliable Reinforcement Learning for Advanced Reasoning Tasks
Apr 08, 2025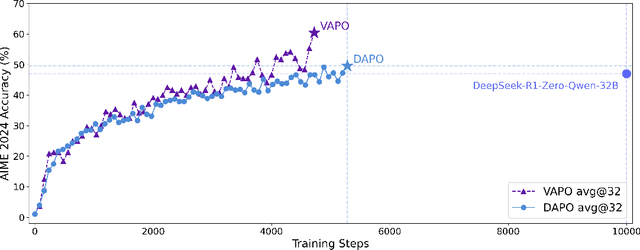

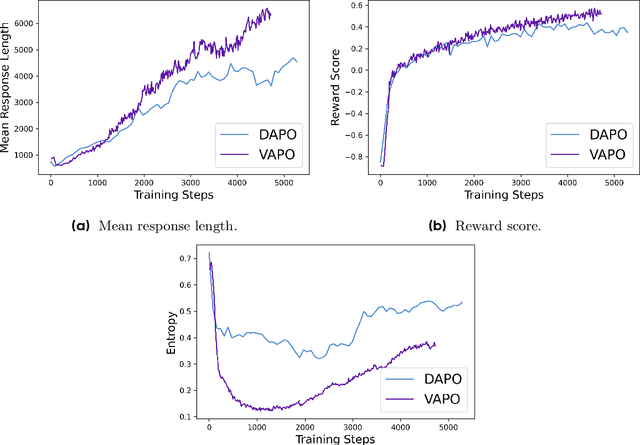
We present VAPO, Value-based Augmented Proximal Policy Optimization framework for reasoning models., a novel framework tailored for reasoning models within the value-based paradigm. Benchmarked the AIME 2024 dataset, VAPO, built on the Qwen 32B pre-trained model, attains a state-of-the-art score of $\mathbf{60.4}$. In direct comparison under identical experimental settings, VAPO outperforms the previously reported results of DeepSeek-R1-Zero-Qwen-32B and DAPO by more than 10 points. The training process of VAPO stands out for its stability and efficiency. It reaches state-of-the-art performance within a mere 5,000 steps. Moreover, across multiple independent runs, no training crashes occur, underscoring its reliability. This research delves into long chain-of-thought (long-CoT) reasoning using a value-based reinforcement learning framework. We pinpoint three key challenges that plague value-based methods: value model bias, the presence of heterogeneous sequence lengths, and the sparsity of reward signals. Through systematic design, VAPO offers an integrated solution that effectively alleviates these challenges, enabling enhanced performance in long-CoT reasoning tasks.
Output-Feedback Boundary Control of Thermally and Flow-Induced Vibrations in Slender Timoshenko Beams
Mar 27, 2025



This work is motivated by the engineering challenge of suppressing vibrations in turbine blades of aero engines, which often operate under extreme thermal conditions and high-Mach aerodynamic environments that give rise to complex vibration phenomena, commonly referred to as thermally-induced and flow-induced vibrations. Using Hamilton's variational principle, the system is modeled as a rotating slender Timoshenko beam under thermal and aerodynamic loads, described by a mixed hyperbolic-parabolic PDE system where instabilities occur both within the PDE domain and at the uncontrolled boundary, and the two types of PDEs are cascaded in the domain. For such a system, we present the state-feedback control design based on the PDE backstepping method. Recognizing that the distributed temperature gradients and structural vibrations in the Timoshenko beam are typically unmeasurable in practice, we design a state observer for the mixed hyperbolic-parabolic PDE system. Based on this observer, an output-feedback controller is then built to regulate the overall system using only available boundary measurements. In the closed-loop system, the state of the uncontrolled boundary, i.e., the furthest state from the control input, is proved to be exponentially convergent to zero, and all signals are proved as uniformly ultimately bounded. The proposed control design is validated on an aero-engine flexible blade under extreme thermal and aerodynamic conditions.
DAPO: An Open-Source LLM Reinforcement Learning System at Scale
Mar 18, 2025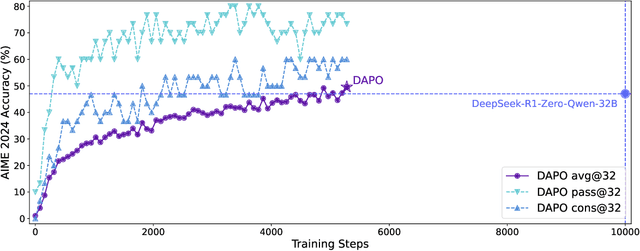

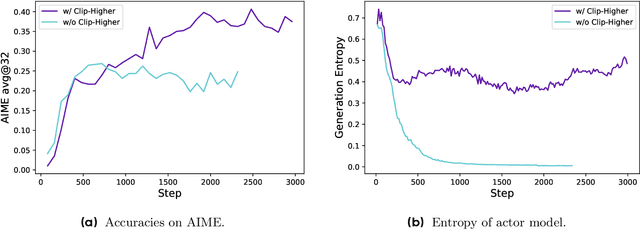

Inference scaling empowers LLMs with unprecedented reasoning ability, with reinforcement learning as the core technique to elicit complex reasoning. However, key technical details of state-of-the-art reasoning LLMs are concealed (such as in OpenAI o1 blog and DeepSeek R1 technical report), thus the community still struggles to reproduce their RL training results. We propose the $\textbf{D}$ecoupled Clip and $\textbf{D}$ynamic s$\textbf{A}$mpling $\textbf{P}$olicy $\textbf{O}$ptimization ($\textbf{DAPO}$) algorithm, and fully open-source a state-of-the-art large-scale RL system that achieves 50 points on AIME 2024 using Qwen2.5-32B base model. Unlike previous works that withhold training details, we introduce four key techniques of our algorithm that make large-scale LLM RL a success. In addition, we open-source our training code, which is built on the verl framework, along with a carefully curated and processed dataset. These components of our open-source system enhance reproducibility and support future research in large-scale LLM RL.
Evaluation and Optimization of Rendering Techniques for Autonomous Driving Simulation
Jun 27, 2023
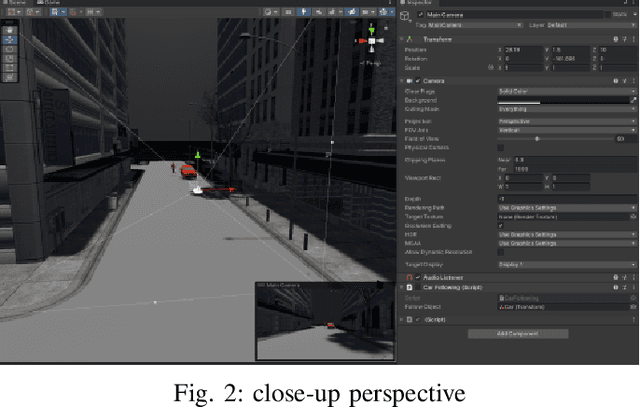
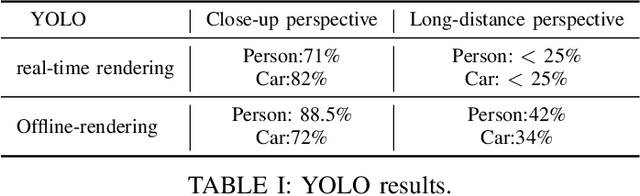
In order to meet the demand for higher scene rendering quality from some autonomous driving teams (such as those focused on CV), we have decided to use an offline simulation industrial rendering framework instead of real-time rendering in our autonomous driving simulator. Our plan is to generate lower-quality scenes using a game engine, extract them, and then use an IQA algorithm to validate the improvement in scene quality achieved through offline rendering. The improved scenes will then be used for training.
Speak Foreign Languages with Your Own Voice: Cross-Lingual Neural Codec Language Modeling
Mar 07, 2023We propose a cross-lingual neural codec language model, VALL-E X, for cross-lingual speech synthesis. Specifically, we extend VALL-E and train a multi-lingual conditional codec language model to predict the acoustic token sequences of the target language speech by using both the source language speech and the target language text as prompts. VALL-E X inherits strong in-context learning capabilities and can be applied for zero-shot cross-lingual text-to-speech synthesis and zero-shot speech-to-speech translation tasks. Experimental results show that it can generate high-quality speech in the target language via just one speech utterance in the source language as a prompt while preserving the unseen speaker's voice, emotion, and acoustic environment. Moreover, VALL-E X effectively alleviates the foreign accent problems, which can be controlled by a language ID. Audio samples are available at \url{https://aka.ms/vallex}.
Neural Codec Language Models are Zero-Shot Text to Speech Synthesizers
Jan 05, 2023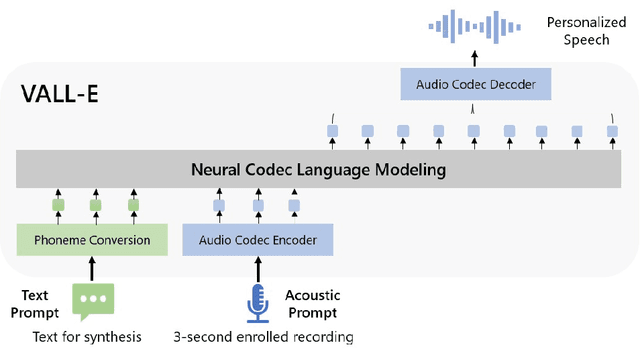

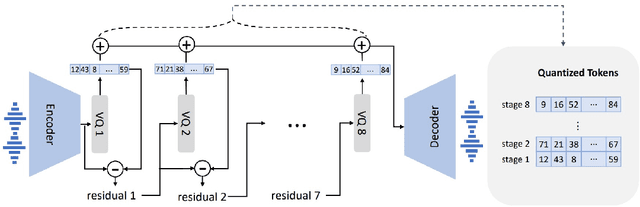
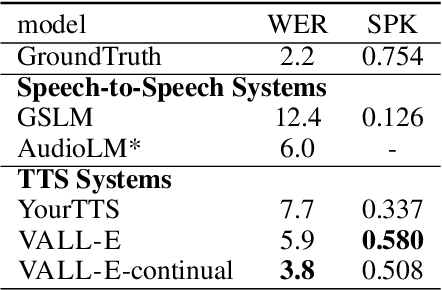
We introduce a language modeling approach for text to speech synthesis (TTS). Specifically, we train a neural codec language model (called Vall-E) using discrete codes derived from an off-the-shelf neural audio codec model, and regard TTS as a conditional language modeling task rather than continuous signal regression as in previous work. During the pre-training stage, we scale up the TTS training data to 60K hours of English speech which is hundreds of times larger than existing systems. Vall-E emerges in-context learning capabilities and can be used to synthesize high-quality personalized speech with only a 3-second enrolled recording of an unseen speaker as an acoustic prompt. Experiment results show that Vall-E significantly outperforms the state-of-the-art zero-shot TTS system in terms of speech naturalness and speaker similarity. In addition, we find Vall-E could preserve the speaker's emotion and acoustic environment of the acoustic prompt in synthesis. See https://aka.ms/valle for demos of our work.
BEATs: Audio Pre-Training with Acoustic Tokenizers
Dec 18, 2022The massive growth of self-supervised learning (SSL) has been witnessed in language, vision, speech, and audio domains over the past few years. While discrete label prediction is widely adopted for other modalities, the state-of-the-art audio SSL models still employ reconstruction loss for pre-training. Compared with reconstruction loss, semantic-rich discrete label prediction encourages the SSL model to abstract the high-level audio semantics and discard the redundant details as in human perception. However, a semantic-rich acoustic tokenizer for general audio pre-training is usually not straightforward to obtain, due to the continuous property of audio and unavailable phoneme sequences like speech. To tackle this challenge, we propose BEATs, an iterative audio pre-training framework to learn Bidirectional Encoder representation from Audio Transformers, where an acoustic tokenizer and an audio SSL model are optimized by iterations. In the first iteration, we use random projection as the acoustic tokenizer to train an audio SSL model in a mask and label prediction manner. Then, we train an acoustic tokenizer for the next iteration by distilling the semantic knowledge from the pre-trained or fine-tuned audio SSL model. The iteration is repeated with the hope of mutual promotion of the acoustic tokenizer and audio SSL model. The experimental results demonstrate our acoustic tokenizers can generate discrete labels with rich audio semantics and our audio SSL models achieve state-of-the-art results across various audio classification benchmarks, even outperforming previous models that use more training data and model parameters significantly. Specifically, we set a new state-of-the-art mAP 50.6% on AudioSet-2M for audio-only models without using any external data, and 98.1% accuracy on ESC-50. The code and pre-trained models are available at https://aka.ms/beats.
Supervision-Guided Codebooks for Masked Prediction in Speech Pre-training
Jun 21, 2022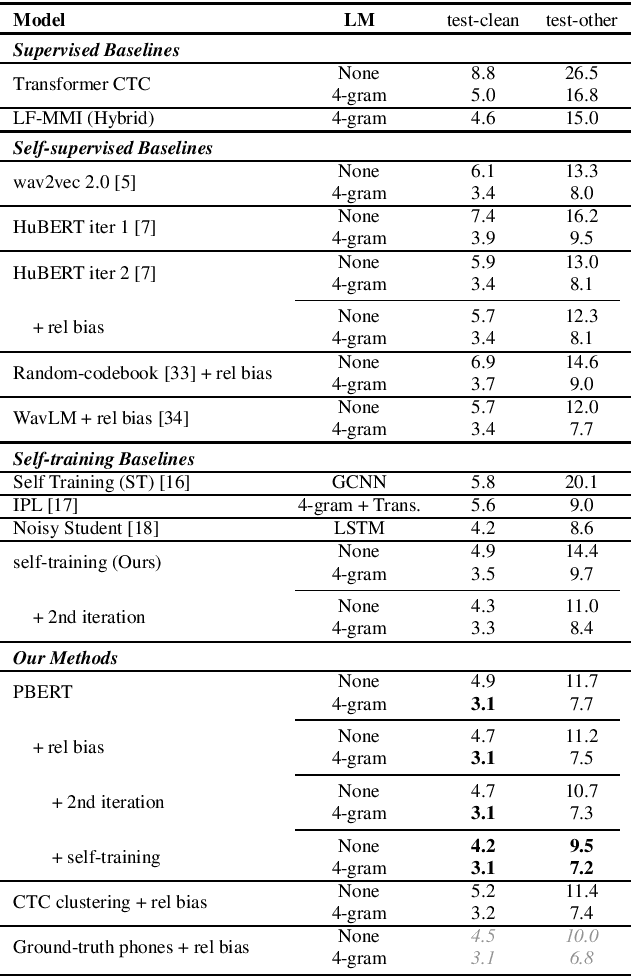
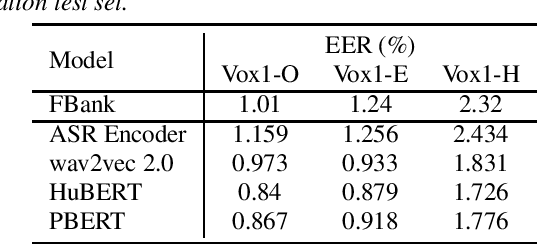
Recently, masked prediction pre-training has seen remarkable progress in self-supervised learning (SSL) for speech recognition. It usually requires a codebook obtained in an unsupervised way, making it less accurate and difficult to interpret. We propose two supervision-guided codebook generation approaches to improve automatic speech recognition (ASR) performance and also the pre-training efficiency, either through decoding with a hybrid ASR system to generate phoneme-level alignments (named PBERT), or performing clustering on the supervised speech features extracted from an end-to-end CTC model (named CTC clustering). Both the hybrid and CTC models are trained on the same small amount of labeled speech as used in fine-tuning. Experiments demonstrate significant superiority of our methods to various SSL and self-training baselines, with up to 17.0% relative WER reduction. Our pre-trained models also show good transferability in a non-ASR speech task.