 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeQDA-SQL: Questions Enhanced Dialogue Augmentation for Multi-Turn Text-to-SQL
Jun 15, 2024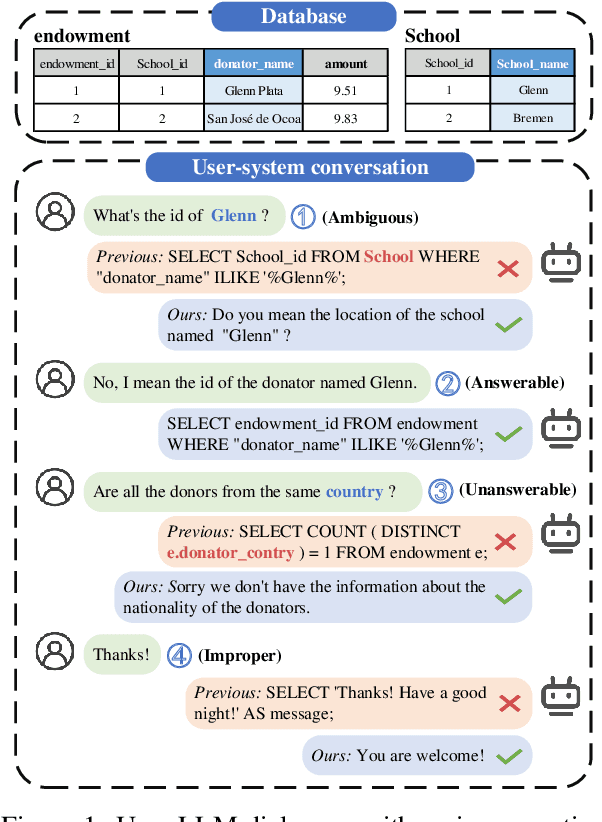

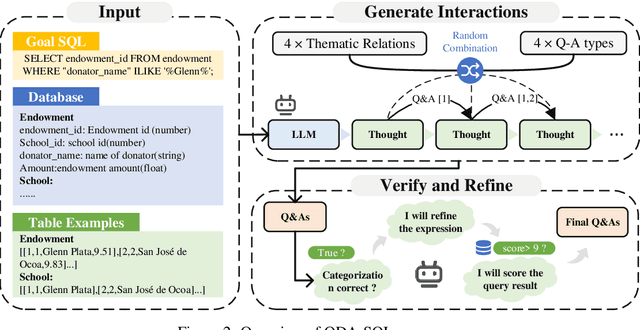

Fine-tuning large language models (LLMs) for specific domain tasks has achieved great success in Text-to-SQL tasks. However, these fine-tuned models often face challenges with multi-turn Text-to-SQL tasks caused by ambiguous or unanswerable questions. It is desired to enhance LLMs to handle multiple types of questions in multi-turn Text-to-SQL tasks. To address this, we propose a novel data augmentation method, called QDA-SQL, which generates multiple types of multi-turn Q\&A pairs by using LLMs. In QDA-SQL, we introduce a novel data augmentation method incorporating validation and correction mechanisms to handle complex multi-turn Text-to-SQL tasks. Experimental results demonstrate that QDA-SQL enables fine-tuned models to exhibit higher performance on SQL statement accuracy and enhances their ability to handle complex, unanswerable questions in multi-turn Text-to-SQL tasks. The generation script and test set are released at https://github.com/mcxiaoxiao/QDA-SQL.
Ultra Fast Speech Separation Model with Teacher Student Learning
Apr 27, 2022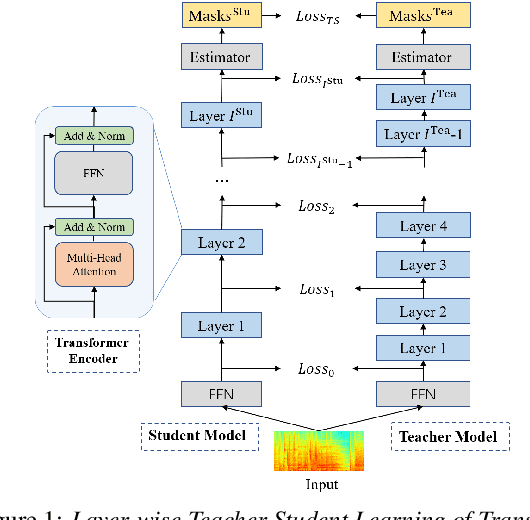
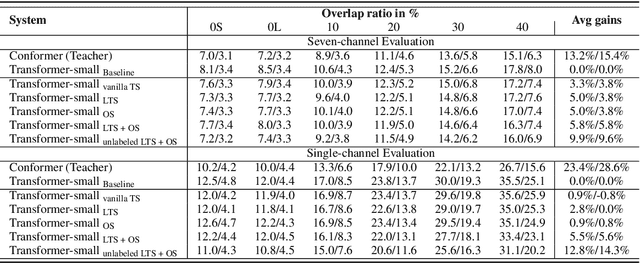
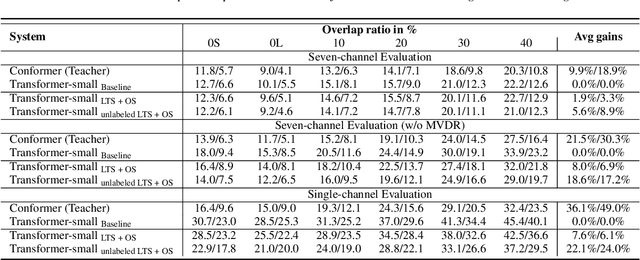
Transformer has been successfully applied to speech separation recently with its strong long-dependency modeling capacity using a self-attention mechanism. However, Transformer tends to have heavy run-time costs due to the deep encoder layers, which hinders its deployment on edge devices. A small Transformer model with fewer encoder layers is preferred for computational efficiency, but it is prone to performance degradation. In this paper, an ultra fast speech separation Transformer model is proposed to achieve both better performance and efficiency with teacher student learning (T-S learning). We introduce layer-wise T-S learning and objective shifting mechanisms to guide the small student model to learn intermediate representations from the large teacher model. Compared with the small Transformer model trained from scratch, the proposed T-S learning method reduces the word error rate (WER) by more than 5% for both multi-channel and single-channel speech separation on LibriCSS dataset. Utilizing more unlabeled speech data, our ultra fast speech separation models achieve more than 10% relative WER reduction.
Why does Self-Supervised Learning for Speech Recognition Benefit Speaker Recognition?
Apr 27, 2022
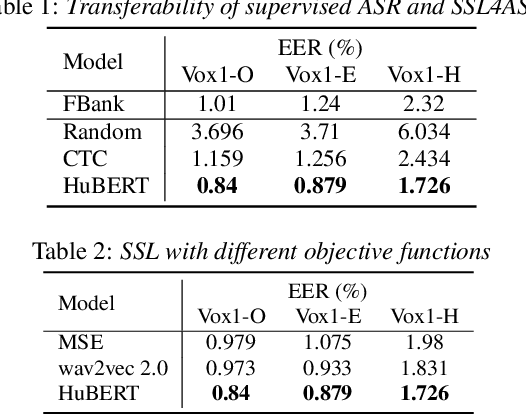
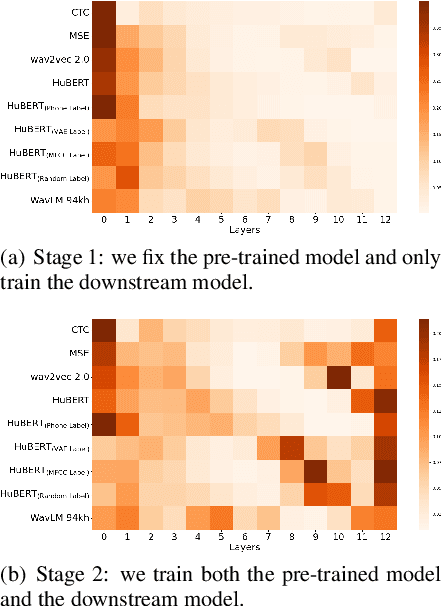
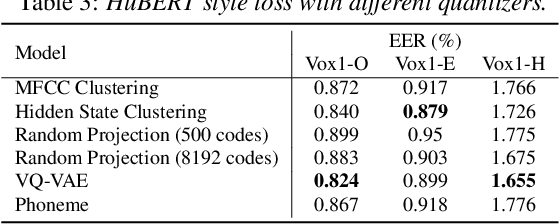
Recently, self-supervised learning (SSL) has demonstrated strong performance in speaker recognition, even if the pre-training objective is designed for speech recognition. In this paper, we study which factor leads to the success of self-supervised learning on speaker-related tasks, e.g. speaker verification (SV), through a series of carefully designed experiments. Our empirical results on the Voxceleb-1 dataset suggest that the benefit of SSL to SV task is from a combination of mask speech prediction loss, data scale, and model size, while the SSL quantizer has a minor impact. We further employ the integrated gradients attribution method and loss landscape visualization to understand the effectiveness of self-supervised learning for speaker recognition performance.
UniSpeech-SAT: Universal Speech Representation Learning with Speaker Aware Pre-Training
Oct 12, 2021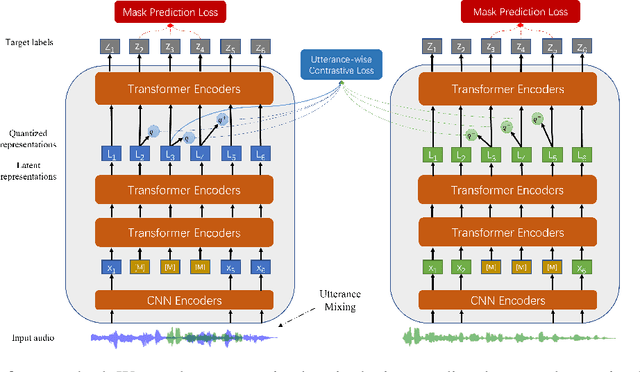
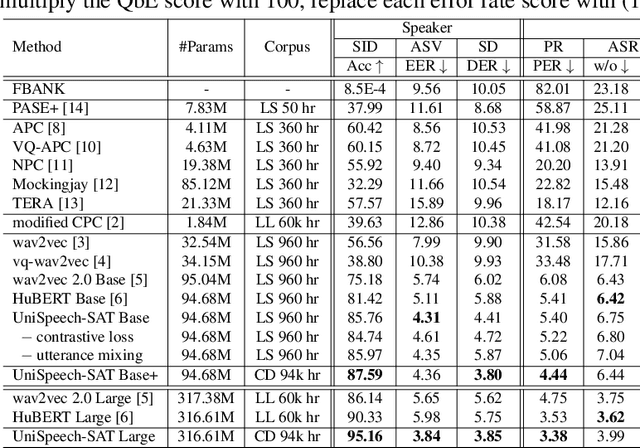
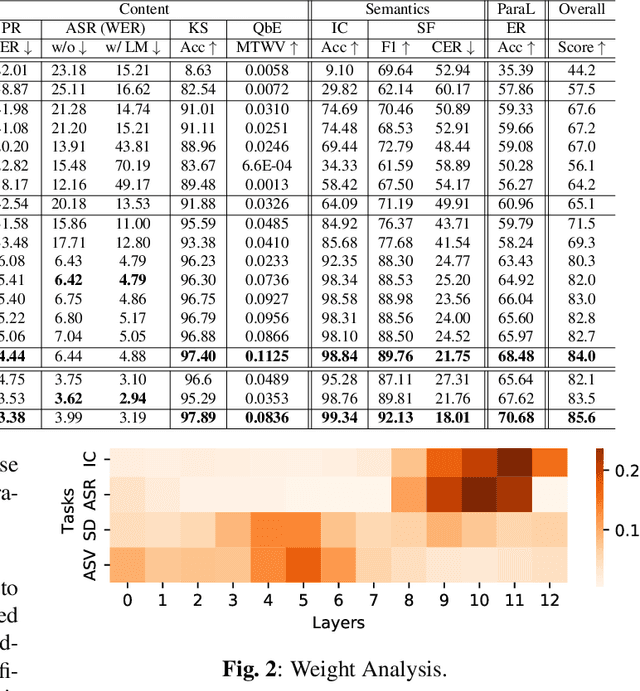
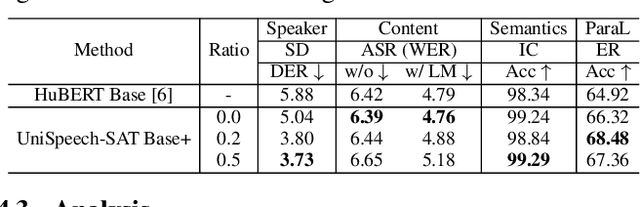
Self-supervised learning (SSL) is a long-standing goal for speech processing, since it utilizes large-scale unlabeled data and avoids extensive human labeling. Recent years witness great successes in applying self-supervised learning in speech recognition, while limited exploration was attempted in applying SSL for modeling speaker characteristics. In this paper, we aim to improve the existing SSL framework for speaker representation learning. Two methods are introduced for enhancing the unsupervised speaker information extraction. First, we apply the multi-task learning to the current SSL framework, where we integrate the utterance-wise contrastive loss with the SSL objective function. Second, for better speaker discrimination, we propose an utterance mixing strategy for data augmentation, where additional overlapped utterances are created unsupervisely and incorporate during training. We integrate the proposed methods into the HuBERT framework. Experiment results on SUPERB benchmark show that the proposed system achieves state-of-the-art performance in universal representation learning, especially for speaker identification oriented tasks. An ablation study is performed verifying the efficacy of each proposed method. Finally, we scale up training dataset to 94 thousand hours public audio data and achieve further performance improvement in all SUPERB tasks.
Recall and Learn: Fine-tuning Deep Pretrained Language Models with Less Forgetting
Apr 27, 2020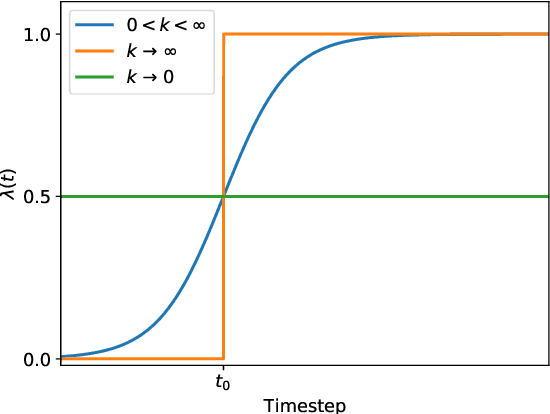
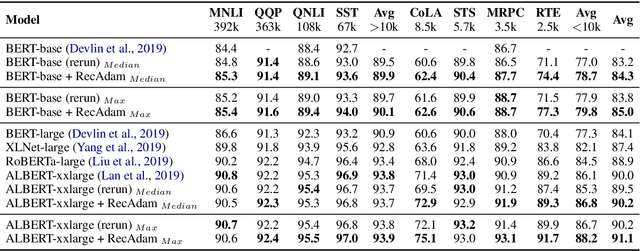
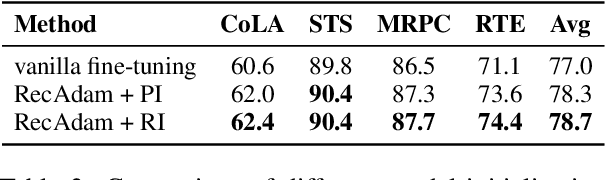
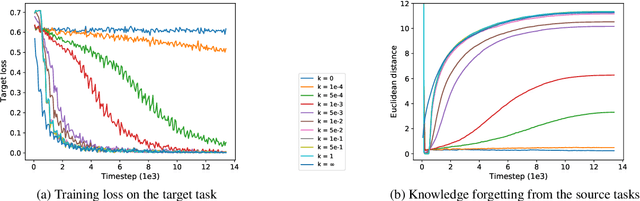
Deep pretrained language models have achieved great success in the way of pretraining first and then fine-tuning. But such a sequential transfer learning paradigm often confronts the catastrophic forgetting problem and leads to sub-optimal performance. To fine-tune with less forgetting, we propose a recall and learn mechanism, which adopts the idea of multi-task learning and jointly learns pretraining tasks and downstream tasks. Specifically, we propose a Pretraining Simulation mechanism to recall the knowledge from pretraining tasks without data, and an Objective Shifting mechanism to focus the learning on downstream tasks gradually. Experiments show that our method achieves state-of-the-art performance on the GLUE benchmark. Our method also enables BERT-base to achieve better performance than directly fine-tuning of BERT-large. Further, we provide the open-source RecAdam optimizer, which integrates the proposed mechanisms into Adam optimizer, to facility the NLP community.