 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEvaluating and Enhancing LLMs for Multi-turn Text-to-SQL with Multiple Question Types
Dec 21, 2024Recent advancements in large language models (LLMs) have significantly advanced text-to-SQL systems. However, most LLM-based methods often narrowly focus on SQL generation, neglecting the complexities of real-world conversational queries. This oversight can lead to unreliable responses, particularly for ambiguous questions that cannot be directly addressed with SQL. To bridge this gap, we propose MMSQL, a comprehensive test suite designed to evaluate the question classification and SQL generation capabilities of LLMs by simulating real-world scenarios with diverse question types and multi-turn Q\&A interactions. Using MMSQL, we assessed the performance of popular LLMs, including both open-source and closed-source models, and identified key factors impacting their performance in such scenarios. Moreover, we introduce an LLM-based multi-agent framework that employs specialized agents to identify question types and determine appropriate answering strategies. Our experiments demonstrate that this approach significantly enhances the model's ability to navigate the complexities of conversational dynamics, effectively handling the diverse and complex nature of user queries.
Breaking the Context Bottleneck on Long Time Series Forecasting
Dec 21, 2024Long-term time-series forecasting is essential for planning and decision-making in economics, energy, and transportation, where long foresight is required. To obtain such long foresight, models must be both efficient and effective in processing long sequence. Recent advancements have enhanced the efficiency of these models; however, the challenge of effectively leveraging longer sequences persists. This is primarily due to the tendency of these models to overfit when presented with extended inputs, necessitating the use of shorter input lengths to maintain tolerable error margins. In this work, we investigate the multiscale modeling method and propose the Logsparse Decomposable Multiscaling (LDM) framework for the efficient and effective processing of long sequences. We demonstrate that by decoupling patterns at different scales in time series, we can enhance predictability by reducing non-stationarity, improve efficiency through a compact long input representation, and simplify the architecture by providing clear task assignments. Experimental results demonstrate that LDM not only outperforms all baselines in long-term forecasting benchmarks, but also reducing both training time and memory costs.
QDA-SQL: Questions Enhanced Dialogue Augmentation for Multi-Turn Text-to-SQL
Jun 15, 2024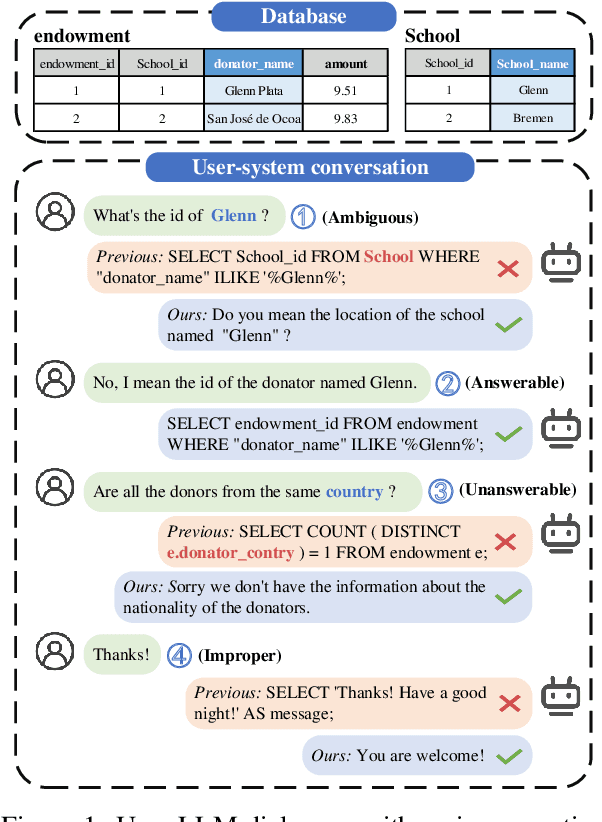

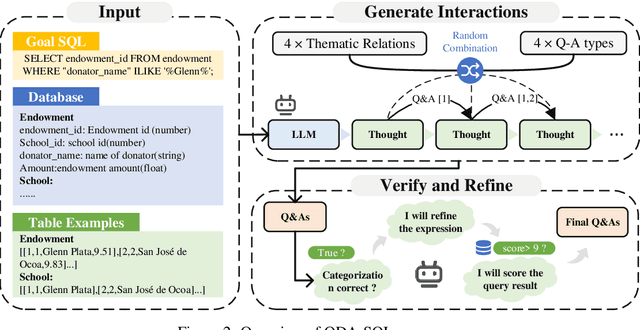

Fine-tuning large language models (LLMs) for specific domain tasks has achieved great success in Text-to-SQL tasks. However, these fine-tuned models often face challenges with multi-turn Text-to-SQL tasks caused by ambiguous or unanswerable questions. It is desired to enhance LLMs to handle multiple types of questions in multi-turn Text-to-SQL tasks. To address this, we propose a novel data augmentation method, called QDA-SQL, which generates multiple types of multi-turn Q\&A pairs by using LLMs. In QDA-SQL, we introduce a novel data augmentation method incorporating validation and correction mechanisms to handle complex multi-turn Text-to-SQL tasks. Experimental results demonstrate that QDA-SQL enables fine-tuned models to exhibit higher performance on SQL statement accuracy and enhances their ability to handle complex, unanswerable questions in multi-turn Text-to-SQL tasks. The generation script and test set are released at https://github.com/mcxiaoxiao/QDA-SQL.