 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTESSP: Text-Enhanced Self-Supervised Speech Pre-training
Nov 24, 2022



Self-supervised speech pre-training empowers the model with the contextual structure inherent in the speech signal while self-supervised text pre-training empowers the model with linguistic information. Both of them are beneficial for downstream speech tasks such as ASR. However, the distinct pre-training objectives make it challenging to jointly optimize the speech and text representation in the same model. To solve this problem, we propose Text-Enhanced Self-Supervised Speech Pre-training (TESSP), aiming to incorporate the linguistic information into speech pre-training. Our model consists of three parts, i.e., a speech encoder, a text encoder and a shared encoder. The model takes unsupervised speech and text data as the input and leverages the common HuBERT and MLM losses respectively. We also propose phoneme up-sampling and representation swapping to enable joint modeling of the speech and text information. Specifically, to fix the length mismatching problem between speech and text data, we phonemize the text sequence and up-sample the phonemes with the alignment information extracted from a small set of supervised data. Moreover, to close the gap between the learned speech and text representations, we swap the text representation with the speech representation extracted by the respective private encoders according to the alignment information. Experiments on the Librispeech dataset shows the proposed TESSP model achieves more than 10% improvement compared with WavLM on the test-clean and test-other sets. We also evaluate our model on the SUPERB benchmark, showing our model has better performance on Phoneme Recognition, Acoustic Speech Recognition and Speech Translation compared with WavLM.
SpeechLM: Enhanced Speech Pre-Training with Unpaired Textual Data
Sep 30, 2022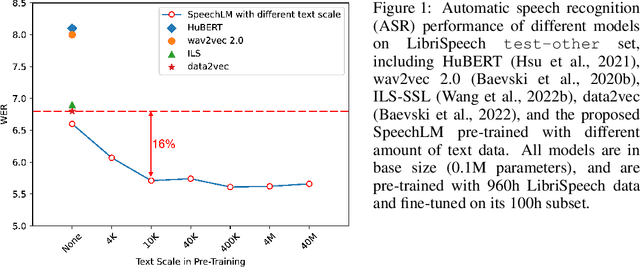
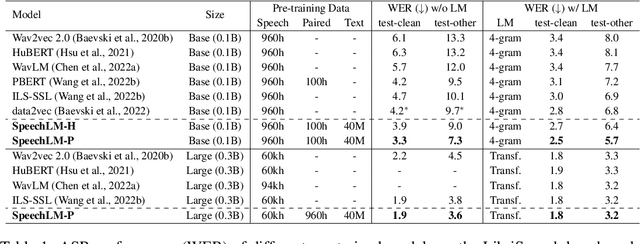
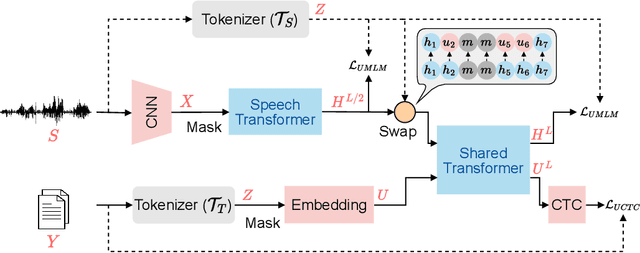
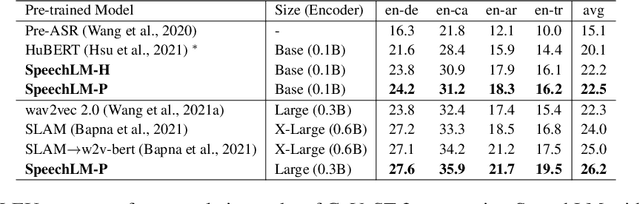
How to boost speech pre-training with textual data is an unsolved problem due to the fact that speech and text are very different modalities with distinct characteristics. In this paper, we propose a cross-modal Speech and Language Model (SpeechLM) to explicitly align speech and text pre-training with a pre-defined unified discrete representation. Specifically, we introduce two alternative discrete tokenizers to bridge the speech and text modalities, including phoneme-unit and hidden-unit tokenizers, which can be trained using a small amount of paired speech-text data. Based on the trained tokenizers, we convert the unlabeled speech and text data into tokens of phoneme units or hidden units. The pre-training objective is designed to unify the speech and the text into the same discrete semantic space with a unified Transformer network. Leveraging only 10K text sentences, our SpeechLM gets a 16\% relative WER reduction over the best base model performance (from 6.8 to 5.7) on the public LibriSpeech ASR benchmark. Moreover, SpeechLM with fewer parameters even outperforms previous SOTA models on CoVoST-2 speech translation tasks. We also evaluate our SpeechLM on various spoken language processing tasks under the universal representation evaluation framework SUPERB, demonstrating significant improvements on content-related tasks. Our code and models are available at https://aka.ms/SpeechLM.
WeNet 2.0: More Productive End-to-End Speech Recognition Toolkit
Mar 29, 2022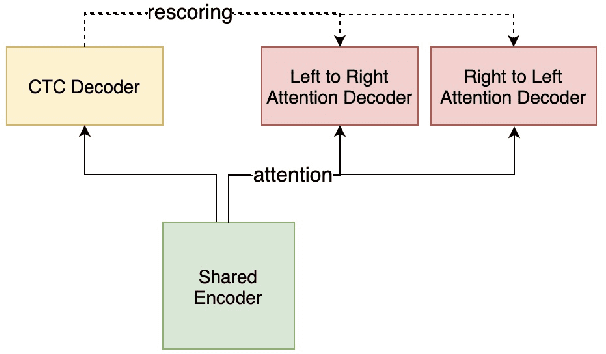



Recently, we made available WeNet, a production-oriented end-to-end speech recognition toolkit, which introduces a unified two-pass (U2) framework and a built-in runtime to address the streaming and non-streaming decoding modes in a single model. To further improve ASR performance and facilitate various production requirements, in this paper, we present WeNet 2.0 with four important updates. (1) We propose U2++, a unified two-pass framework with bidirectional attention decoders, which includes the future contextual information by a right-to-left attention decoder to improve the representative ability of the shared encoder and the performance during the rescoring stage. (2) We introduce an n-gram based language model and a WFST-based decoder into WeNet 2.0, promoting the use of rich text data in production scenarios. (3) We design a unified contextual biasing framework, which leverages user-specific context (e.g., contact lists) to provide rapid adaptation ability for production and improves ASR accuracy in both with-LM and without-LM scenarios. (4) We design a unified IO to support large-scale data for effective model training. In summary, the brand-new WeNet 2.0 achieves up to 10\% relative recognition performance improvement over the original WeNet on various corpora and makes available several important production-oriented features.
Boundary and Context Aware Training for CIF-based Non-Autoregressive End-to-end ASR
Apr 10, 2021Continuous integrate-and-fire (CIF) based models, which use a soft and monotonic alignment mechanism, have been well applied in non-autoregressive (NAR) speech recognition and achieved competitive performance compared with other NAR methods. However, such an alignment learning strategy may also result in inaccurate acoustic boundary estimation and deceleration in convergence speed. To eliminate these drawbacks and improve performance further, we incorporate an additional connectionist temporal classification (CTC) based alignment loss and a contextual decoder into the CIF-based NAR model. Specifically, we use the CTC spike information to guide the leaning of acoustic boundary and adopt a new contextual decoder to capture the linguistic dependencies within a sentence in the conventional CIF model. Besides, a recently proposed Conformer architecture is also employed to model both local and global acoustic dependencies. Experiments on the open-source Mandarin corpora AISHELL-1 show that the proposed method achieves a comparable character error rate (CER) of 4.9% with only 1/24 latency compared with a state-of-the-art autoregressive (AR) Conformer model.
WeNet: Production First and Production Ready End-to-End Speech Recognition Toolkit
Feb 02, 2021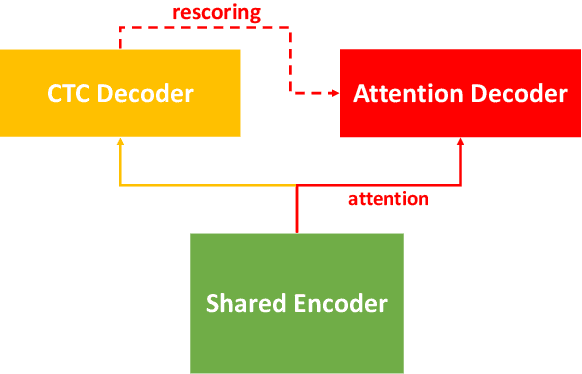
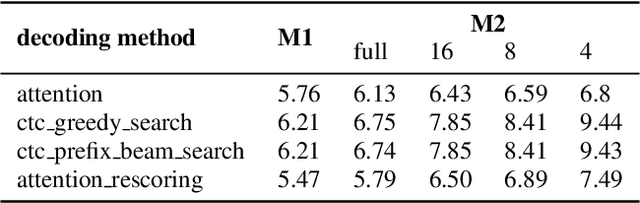

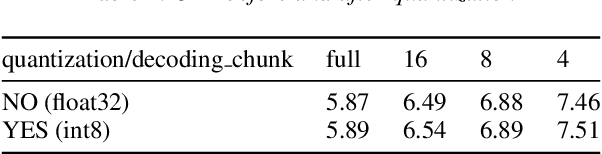
In this paper, we present a new open source, production first and production ready end-to-end (E2E) speech recognition toolkit named WeNet. The main motivation of WeNet is to close the gap between the research and the production of E2E speech recognition models. WeNet provides an efficient way to ship ASR applications in several real-world scenarios, which is the main difference and advantage to other open source E2E speech recognition toolkits. This paper introduces WeNet from three aspects, including model architecture, framework design and performance metrics. Our experiments on AISHELL-1 using WeNet, not only give a promising character error rate (CER) on a unified streaming and non-streaming two pass (U2) E2E model but also show reasonable RTF and latency, both of these aspects are favored for production adoption. The toolkit is publicly available at https://github.com/mobvoi/wenet.
Unified Streaming and Non-streaming Two-pass End-to-end Model for Speech Recognition
Dec 10, 2020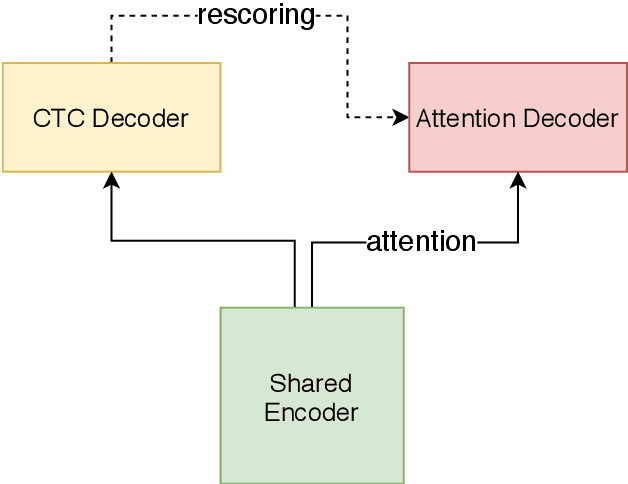


In this paper, we present a novel two-pass approach to unify streaming and non-streaming end-to-end (E2E) speech recognition in a single model. Our model adopts the hybrid CTC/attention architecture, in which the conformer layers in the encoder are modified. We propose a dynamic chunk-based attention strategy to allow arbitrary right context length. At inference time, the CTC decoder generates n-best hypotheses in a streaming way. The inference latency could be easily controlled by only changing the chunk size. The CTC hypotheses are then rescored by the attention decoder to get the final result. This efficient rescoring process causes very little sentence-level latency. Our experiments on the open 170-hour AISHELL-1 dataset show that, the proposed method can unify the streaming and non-streaming model simply and efficiently. On the AISHELL-1 test set, our unified model achieves 5.60% relative character error rate (CER) reduction in non-streaming ASR compared to a standard non-streaming transformer. The same model achieves 5.42% CER with 640ms latency in a streaming ASR system.
Cascade RNN-Transducer: Syllable Based Streaming On-device Mandarin Speech Recognition with a Syllable-to-Character Converter
Nov 17, 2020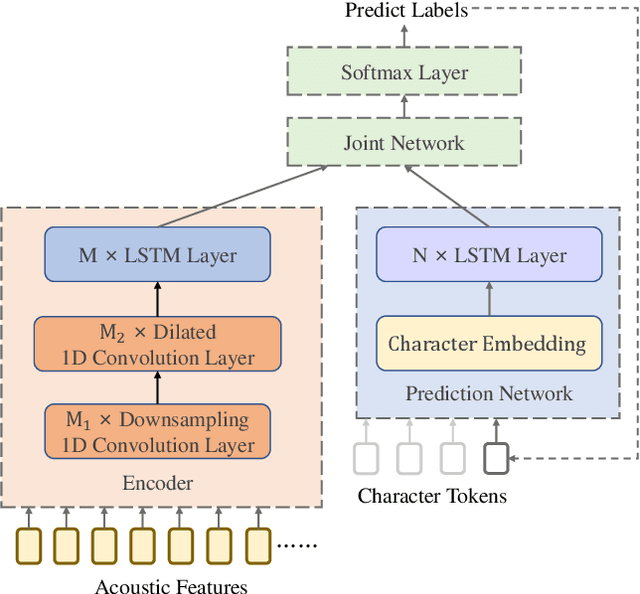

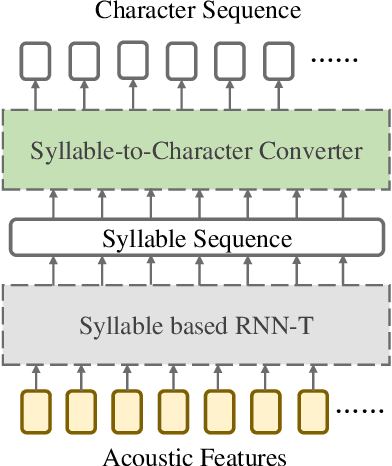
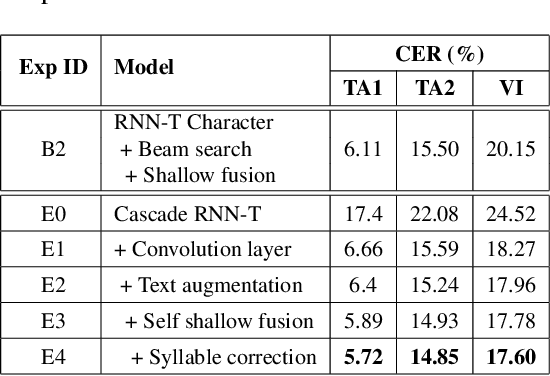
End-to-end models are favored in automatic speech recognition (ASR) because of its simplified system structure and superior performance. Among these models, recurrent neural network transducer (RNN-T) has achieved significant progress in streaming on-device speech recognition because of its high-accuracy and low-latency. RNN-T adopts a prediction network to enhance language information, but its language modeling ability is limited because it still needs paired speech-text data to train. Further strengthening the language modeling ability through extra text data, such as shallow fusion with an external language model, only brings a small performance gain. In view of the fact that Mandarin Chinese is a character-based language and each character is pronounced as a tonal syllable, this paper proposes a novel cascade RNN-T approach to improve the language modeling ability of RNN-T. Our approach firstly uses an RNN-T to transform acoustic feature into syllable sequence, and then converts the syllable sequence into character sequence through an RNN-T-based syllable-to-character converter. Thus a rich text repository can be easily used to strengthen the language model ability. By introducing several important tricks, the cascade RNN-T approach surpasses the character-based RNN-T by a large margin on several Mandarin test sets, with much higher recognition quality and similar latency.