 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUnified Streaming and Non-streaming Two-pass End-to-end Model for Speech Recognition
Dec 10, 2020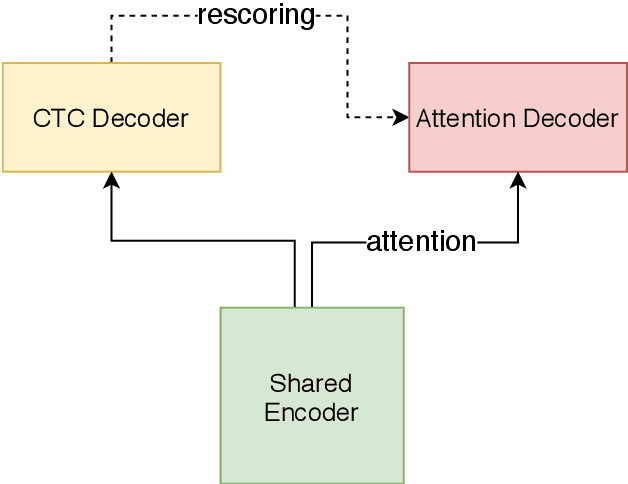

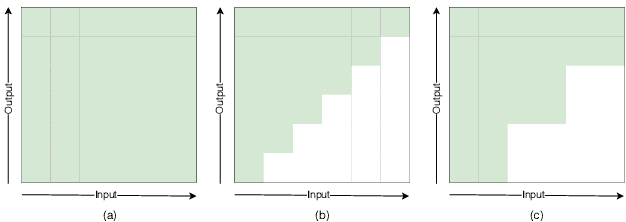

In this paper, we present a novel two-pass approach to unify streaming and non-streaming end-to-end (E2E) speech recognition in a single model. Our model adopts the hybrid CTC/attention architecture, in which the conformer layers in the encoder are modified. We propose a dynamic chunk-based attention strategy to allow arbitrary right context length. At inference time, the CTC decoder generates n-best hypotheses in a streaming way. The inference latency could be easily controlled by only changing the chunk size. The CTC hypotheses are then rescored by the attention decoder to get the final result. This efficient rescoring process causes very little sentence-level latency. Our experiments on the open 170-hour AISHELL-1 dataset show that, the proposed method can unify the streaming and non-streaming model simply and efficiently. On the AISHELL-1 test set, our unified model achieves 5.60% relative character error rate (CER) reduction in non-streaming ASR compared to a standard non-streaming transformer. The same model achieves 5.42% CER with 640ms latency in a streaming ASR system.