 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOn the application of Large Language Models for language teaching and assessment technology
Jul 17, 2023The recent release of very large language models such as PaLM and GPT-4 has made an unprecedented impact in the popular media and public consciousness, giving rise to a mixture of excitement and fear as to their capabilities and potential uses, and shining a light on natural language processing research which had not previously received so much attention. The developments offer great promise for education technology, and in this paper we look specifically at the potential for incorporating large language models in AI-driven language teaching and assessment systems. We consider several research areas and also discuss the risks and ethical considerations surrounding generative AI in education technology for language learners. Overall we find that larger language models offer improvements over previous models in text generation, opening up routes toward content generation which had not previously been plausible. For text generation they must be prompted carefully and their outputs may need to be reshaped before they are ready for use. For automated grading and grammatical error correction, tasks whose progress is checked on well-known benchmarks, early investigations indicate that large language models on their own do not improve on state-of-the-art results according to standard evaluation metrics. For grading it appears that linguistic features established in the literature should still be used for best performance, and for error correction it may be that the models can offer alternative feedback styles which are not measured sensitively with existing methods. In all cases, there is work to be done to experiment with the inclusion of large language models in education technology for language learners, in order to properly understand and report on their capacities and limitations, and to ensure that foreseeable risks such as misinformation and harmful bias are mitigated.
Adaptive Forgetting Curves for Spaced Repetition Language Learning
Apr 23, 2020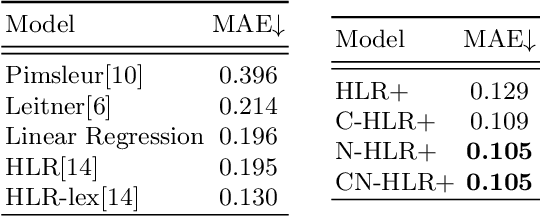

The forgetting curve has been extensively explored by psychologists, educationalists and cognitive scientists alike. In the context of Intelligent Tutoring Systems, modelling the forgetting curve for each user and knowledge component (e.g. vocabulary word) should enable us to develop optimal revision strategies that counteract memory decay and ensure long-term retention. In this study we explore a variety of forgetting curve models incorporating psychological and linguistic features, and we use these models to predict the probability of word recall by learners of English as a second language. We evaluate the impact of the models and their features using data from an online vocabulary teaching platform and find that word complexity is a highly informative feature which may be successfully learned by a neural network model.
Curriculum Q-Learning for Visual Vocabulary Acquisition
Nov 29, 2017

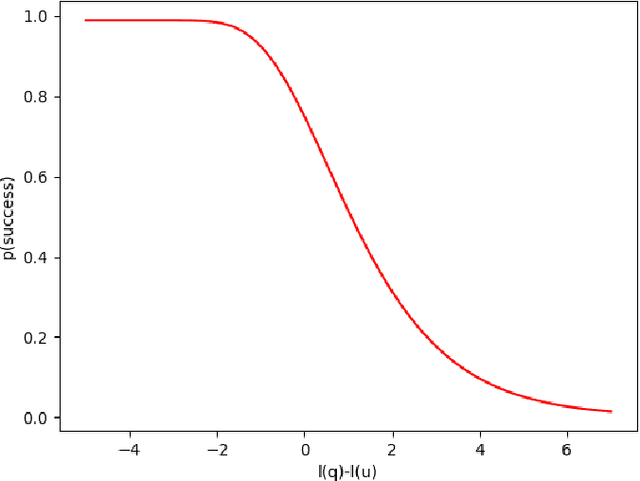
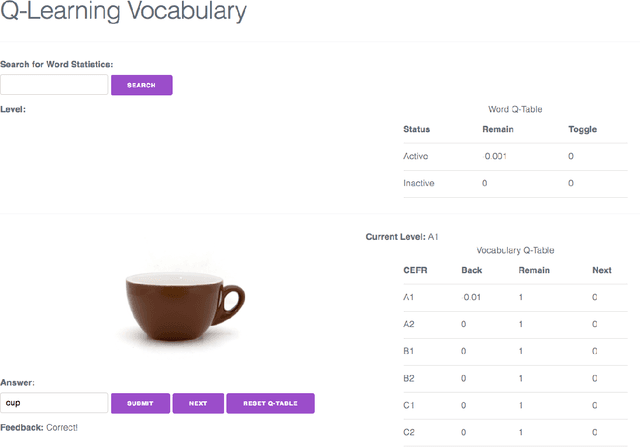
The structure of curriculum plays a vital role in our learning process, both as children and adults. Presenting material in ascending order of difficulty that also exploits prior knowledge can have a significant impact on the rate of learning. However, the notion of difficulty and prior knowledge differs from person to person. Motivated by the need for a personalised curriculum, we present a novel method of curriculum learning for vocabulary words in the form of visual prompts. We employ a reinforcement learning model grounded in pedagogical theories that emulates the actions of a tutor. We simulate three students with different levels of vocabulary knowledge in order to evaluate the how well our model adapts to the environment. The results of the simulation reveal that through interaction, the model is able to identify the areas of weakness, as well as push students to the edge of their ZPD. We hypothesise that these methods can also be effective in training agents to learn language representations in a simulated environment where it has previously been shown that order of words and prior knowledge play an important role in the efficacy of language learning.