 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOn the application of Large Language Models for language teaching and assessment technology
Jul 17, 2023The recent release of very large language models such as PaLM and GPT-4 has made an unprecedented impact in the popular media and public consciousness, giving rise to a mixture of excitement and fear as to their capabilities and potential uses, and shining a light on natural language processing research which had not previously received so much attention. The developments offer great promise for education technology, and in this paper we look specifically at the potential for incorporating large language models in AI-driven language teaching and assessment systems. We consider several research areas and also discuss the risks and ethical considerations surrounding generative AI in education technology for language learners. Overall we find that larger language models offer improvements over previous models in text generation, opening up routes toward content generation which had not previously been plausible. For text generation they must be prompted carefully and their outputs may need to be reshaped before they are ready for use. For automated grading and grammatical error correction, tasks whose progress is checked on well-known benchmarks, early investigations indicate that large language models on their own do not improve on state-of-the-art results according to standard evaluation metrics. For grading it appears that linguistic features established in the literature should still be used for best performance, and for error correction it may be that the models can offer alternative feedback styles which are not measured sensitively with existing methods. In all cases, there is work to be done to experiment with the inclusion of large language models in education technology for language learners, in order to properly understand and report on their capacities and limitations, and to ensure that foreseeable risks such as misinformation and harmful bias are mitigated.
A quantitative study of NLP approaches to question difficulty estimation
May 17, 2023



Recent years witnessed an increase in the amount of research on the task of Question Difficulty Estimation from Text QDET with Natural Language Processing (NLP) techniques, with the goal of targeting the limitations of traditional approaches to question calibration. However, almost the entirety of previous research focused on single silos, without performing quantitative comparisons between different models or across datasets from different educational domains. In this work, we aim at filling this gap, by quantitatively analyzing several approaches proposed in previous research, and comparing their performance on three publicly available real world datasets containing questions of different types from different educational domains. Specifically, we consider reading comprehension Multiple Choice Questions (MCQs), science MCQs, and math questions. We find that Transformer based models are the best performing across different educational domains, with DistilBERT performing almost as well as BERT, and that they outperform other approaches even on smaller datasets. As for the other models, the hybrid ones often outperform the ones based on a single type of features, the ones based on linguistic features perform well on reading comprehension questions, while frequency based features (TF-IDF) and word embeddings (word2vec) perform better in domain knowledge assessment.
Complexity-based partitioning of CSFI problem instances with Transformers
Jun 28, 2021
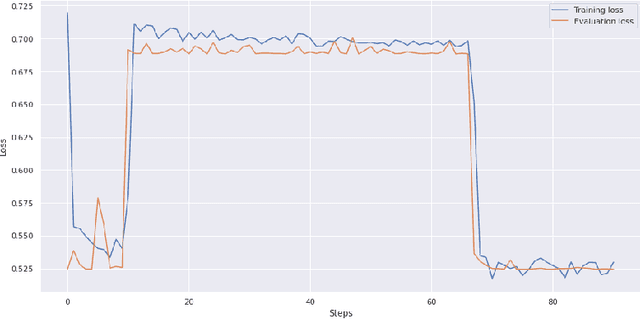
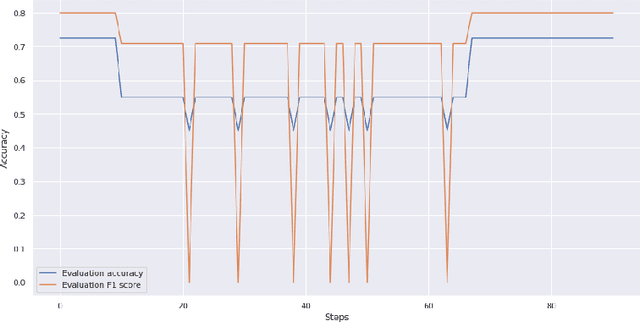
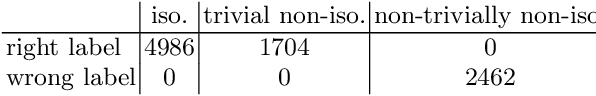
In this paper, we propose a two-steps approach to partition instances of the Conjunctive Normal Form (CNF) Syntactic Formula Isomorphism problem (CSFI) into groups of different complexity. First, we build a model, based on the Transformer architecture, that attempts to solve instances of the CSFI problem. Then, we leverage the errors of such model and train a second Transformer-based model to partition the problem instances into groups of different complexity, thus detecting the ones that can be solved without using too expensive resources. We evaluate the proposed approach on a pseudo-randomly generated dataset and obtain promising results. Finally, we discuss the possibility of extending this approach to other problems based on the same type of textual representation.
Introducing a framework to assess newly created questions with Natural Language Processing
May 06, 2020

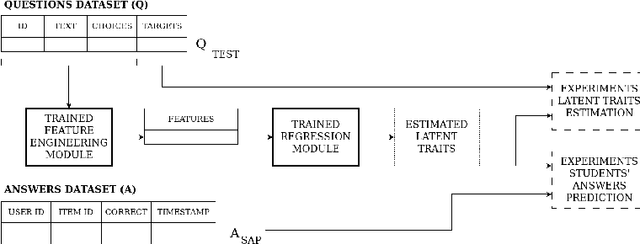
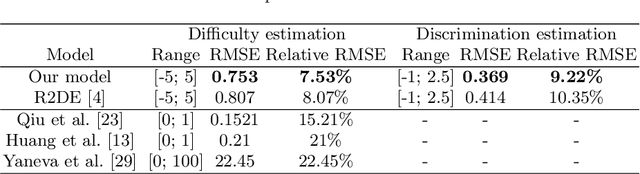
Statistical models such as those derived from Item Response Theory (IRT) enable the assessment of students on a specific subject, which can be useful for several purposes (e.g., learning path customization, drop-out prediction). However, the questions have to be assessed as well and, although it is possible to estimate with IRT the characteristics of questions that have already been answered by several students, this technique cannot be used on newly generated questions. In this paper, we propose a framework to train and evaluate models for estimating the difficulty and discrimination of newly created Multiple Choice Questions by extracting meaningful features from the text of the question and of the possible choices. We implement one model using this framework and test it on a real-world dataset provided by CloudAcademy, showing that it outperforms previously proposed models, reducing by 6.7% the RMSE for difficulty estimation and by 10.8% the RMSE for discrimination estimation. We also present the results of an ablation study performed to support our features choice and to show the effects of different characteristics of the questions' text on difficulty and discrimination.
R2DE: a NLP approach to estimating IRT parameters of newly generated questions
Jan 21, 2020


The main objective of exams consists in performing an assessment of students' expertise on a specific subject. Such expertise, also referred to as skill or knowledge level, can then be leveraged in different ways (e.g., to assign a grade to the students, to understand whether a student might need some support, etc.). Similarly, the questions appearing in the exams have to be assessed in some way before being used to evaluate students. Standard approaches to questions' assessment are either subjective (e.g., assessment by human experts) or introduce a long delay in the process of question generation (e.g., pretesting with real students). In this work we introduce R2DE (which is a Regressor for Difficulty and Discrimination Estimation), a model capable of assessing newly generated multiple-choice questions by looking at the text of the question and the text of the possible choices. In particular, it can estimate the difficulty and the discrimination of each question, as they are defined in Item Response Theory. We also present the results of extensive experiments we carried out on a real world large scale dataset coming from an e-learning platform, showing that our model can be used to perform an initial assessment of newly created questions and ease some of the problems that arise in question generation.