 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIntroducing a framework to assess newly created questions with Natural Language Processing
Paper and Code


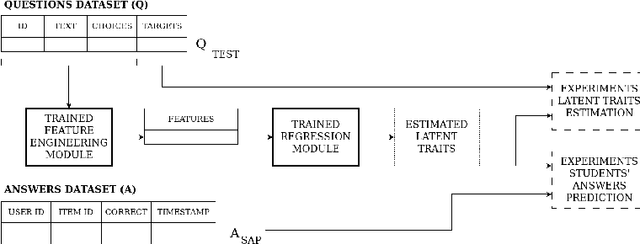
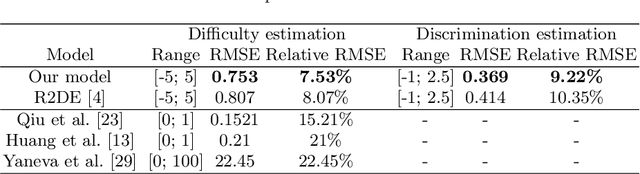
Statistical models such as those derived from Item Response Theory (IRT) enable the assessment of students on a specific subject, which can be useful for several purposes (e.g., learning path customization, drop-out prediction). However, the questions have to be assessed as well and, although it is possible to estimate with IRT the characteristics of questions that have already been answered by several students, this technique cannot be used on newly generated questions. In this paper, we propose a framework to train and evaluate models for estimating the difficulty and discrimination of newly created Multiple Choice Questions by extracting meaningful features from the text of the question and of the possible choices. We implement one model using this framework and test it on a real-world dataset provided by CloudAcademy, showing that it outperforms previously proposed models, reducing by 6.7% the RMSE for difficulty estimation and by 10.8% the RMSE for discrimination estimation. We also present the results of an ablation study performed to support our features choice and to show the effects of different characteristics of the questions' text on difficulty and discrimination.