 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeComplexity-based partitioning of CSFI problem instances with Transformers
Jun 28, 2021
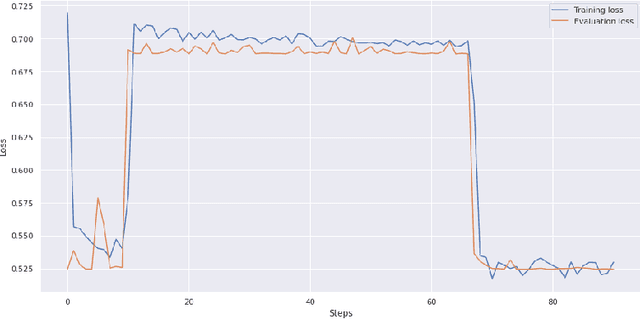
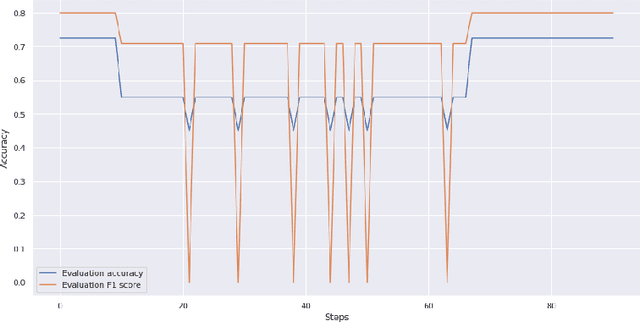
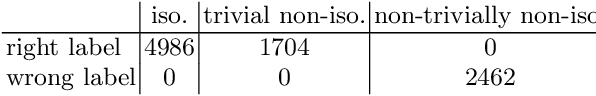
In this paper, we propose a two-steps approach to partition instances of the Conjunctive Normal Form (CNF) Syntactic Formula Isomorphism problem (CSFI) into groups of different complexity. First, we build a model, based on the Transformer architecture, that attempts to solve instances of the CSFI problem. Then, we leverage the errors of such model and train a second Transformer-based model to partition the problem instances into groups of different complexity, thus detecting the ones that can be solved without using too expensive resources. We evaluate the proposed approach on a pseudo-randomly generated dataset and obtain promising results. Finally, we discuss the possibility of extending this approach to other problems based on the same type of textual representation.