 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOpenAI GPT-5 System Card
Dec 19, 2025This is the system card published alongside the OpenAI GPT-5 launch, August 2025. GPT-5 is a unified system with a smart and fast model that answers most questions, a deeper reasoning model for harder problems, and a real-time router that quickly decides which model to use based on conversation type, complexity, tool needs, and explicit intent (for example, if you say 'think hard about this' in the prompt). The router is continuously trained on real signals, including when users switch models, preference rates for responses, and measured correctness, improving over time. Once usage limits are reached, a mini version of each model handles remaining queries. This system card focuses primarily on gpt-5-thinking and gpt-5-main, while evaluations for other models are available in the appendix. The GPT-5 system not only outperforms previous models on benchmarks and answers questions more quickly, but -- more importantly -- is more useful for real-world queries. We've made significant advances in reducing hallucinations, improving instruction following, and minimizing sycophancy, and have leveled up GPT-5's performance in three of ChatGPT's most common uses: writing, coding, and health. All of the GPT-5 models additionally feature safe-completions, our latest approach to safety training to prevent disallowed content. Similarly to ChatGPT agent, we have decided to treat gpt-5-thinking as High capability in the Biological and Chemical domain under our Preparedness Framework, activating the associated safeguards. While we do not have definitive evidence that this model could meaningfully help a novice to create severe biological harm -- our defined threshold for High capability -- we have chosen to take a precautionary approach.
OpenAI o1 System Card
Dec 21, 2024



The o1 model series is trained with large-scale reinforcement learning to reason using chain of thought. These advanced reasoning capabilities provide new avenues for improving the safety and robustness of our models. In particular, our models can reason about our safety policies in context when responding to potentially unsafe prompts, through deliberative alignment. This leads to state-of-the-art performance on certain benchmarks for risks such as generating illicit advice, choosing stereotyped responses, and succumbing to known jailbreaks. Training models to incorporate a chain of thought before answering has the potential to unlock substantial benefits, while also increasing potential risks that stem from heightened intelligence. Our results underscore the need for building robust alignment methods, extensively stress-testing their efficacy, and maintaining meticulous risk management protocols. This report outlines the safety work carried out for the OpenAI o1 and OpenAI o1-mini models, including safety evaluations, external red teaming, and Preparedness Framework evaluations.
Waymax: An Accelerated, Data-Driven Simulator for Large-Scale Autonomous Driving Research
Oct 12, 2023
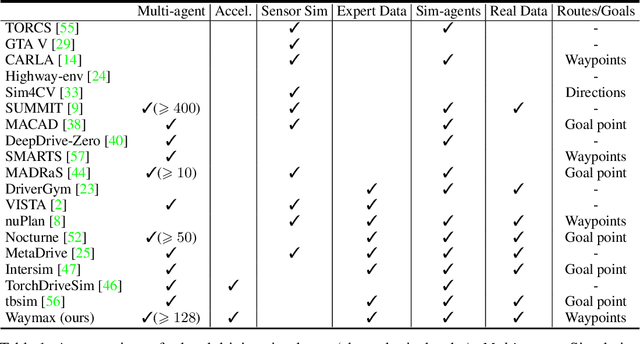
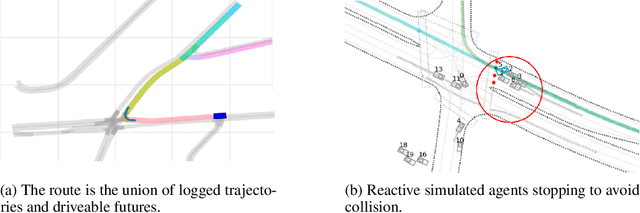
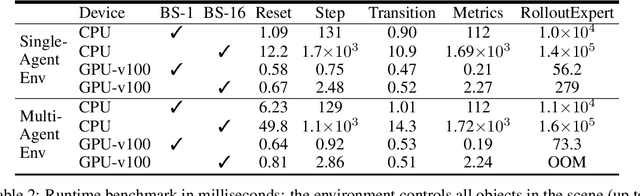
Simulation is an essential tool to develop and benchmark autonomous vehicle planning software in a safe and cost-effective manner. However, realistic simulation requires accurate modeling of nuanced and complex multi-agent interactive behaviors. To address these challenges, we introduce Waymax, a new data-driven simulator for autonomous driving in multi-agent scenes, designed for large-scale simulation and testing. Waymax uses publicly-released, real-world driving data (e.g., the Waymo Open Motion Dataset) to initialize or play back a diverse set of multi-agent simulated scenarios. It runs entirely on hardware accelerators such as TPUs/GPUs and supports in-graph simulation for training, making it suitable for modern large-scale, distributed machine learning workflows. To support online training and evaluation, Waymax includes several learned and hard-coded behavior models that allow for realistic interaction within simulation. To supplement Waymax, we benchmark a suite of popular imitation and reinforcement learning algorithms with ablation studies on different design decisions, where we highlight the effectiveness of routes as guidance for planning agents and the ability of RL to overfit against simulated agents.
General Policy Evaluation and Improvement by Learning to Identify Few But Crucial States
Jul 04, 2022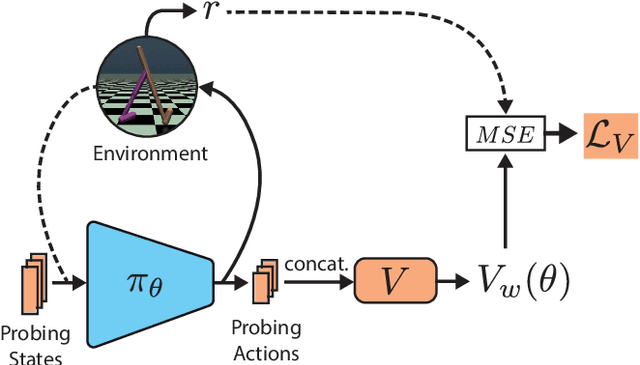
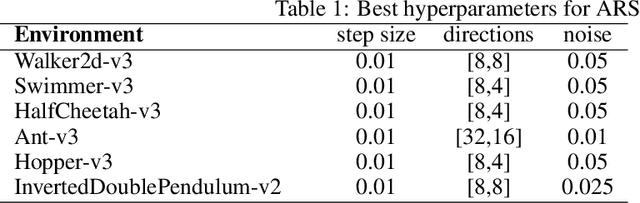
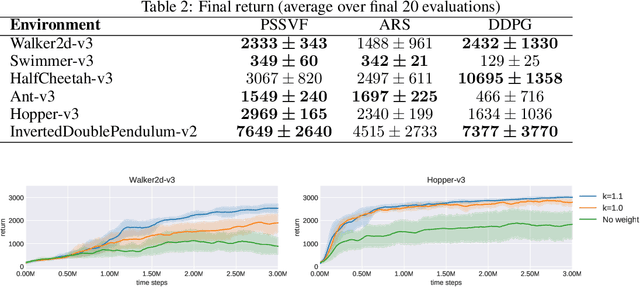
Learning to evaluate and improve policies is a core problem of Reinforcement Learning (RL). Traditional RL algorithms learn a value function defined for a single policy. A recently explored competitive alternative is to learn a single value function for many policies. Here we combine the actor-critic architecture of Parameter-Based Value Functions and the policy embedding of Policy Evaluation Networks to learn a single value function for evaluating (and thus helping to improve) any policy represented by a deep neural network (NN). The method yields competitive experimental results. In continuous control problems with infinitely many states, our value function minimizes its prediction error by simultaneously learning a small set of `probing states' and a mapping from actions produced in probing states to the policy's return. The method extracts crucial abstract knowledge about the environment in form of very few states sufficient to fully specify the behavior of many policies. A policy improves solely by changing actions in probing states, following the gradient of the value function's predictions. Surprisingly, it is possible to clone the behavior of a near-optimal policy in Swimmer-v3 and Hopper-v3 environments only by knowing how to act in 3 and 5 such learned states, respectively. Remarkably, our value function trained to evaluate NN policies is also invariant to changes of the policy architecture: we show that it allows for zero-shot learning of linear policies competitive with the best policy seen during training. Our code is public.
Policy Evaluation Networks
Feb 26, 2020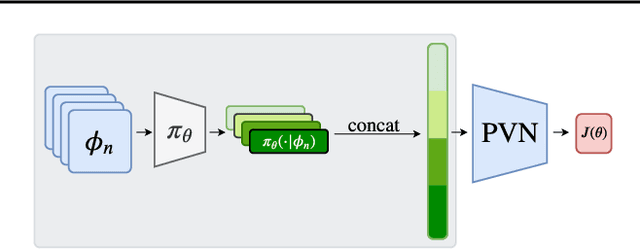
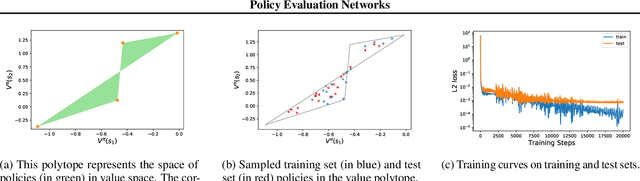
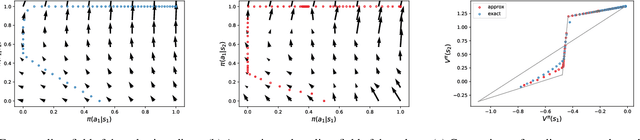
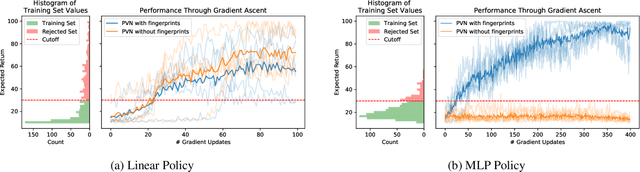
Many reinforcement learning algorithms use value functions to guide the search for better policies. These methods estimate the value of a single policy while generalizing across many states. The core idea of this paper is to flip this convention and estimate the value of many policies, for a single set of states. This approach opens up the possibility of performing direct gradient ascent in policy space without seeing any new data. The main challenge for this approach is finding a way to represent complex policies that facilitates learning and generalization. To address this problem, we introduce a scalable, differentiable fingerprinting mechanism that retains essential policy information in a concise embedding. Our empirical results demonstrate that combining these three elements (learned Policy Evaluation Network, policy fingerprints, gradient ascent) can produce policies that outperform those that generated the training data, in zero-shot manner.
The Barbados 2018 List of Open Issues in Continual Learning
Nov 16, 2018We want to make progress toward artificial general intelligence, namely general-purpose agents that autonomously learn how to competently act in complex environments. The purpose of this report is to sketch a research outline, share some of the most important open issues we are facing, and stimulate further discussion in the community. The content is based on some of our discussions during a week-long workshop held in Barbados in February 2018.
Multi-Agent Actor-Critic for Mixed Cooperative-Competitive Environments
Jan 16, 2018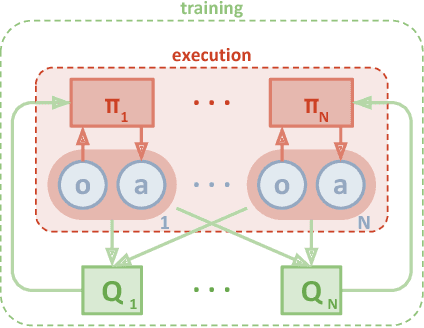
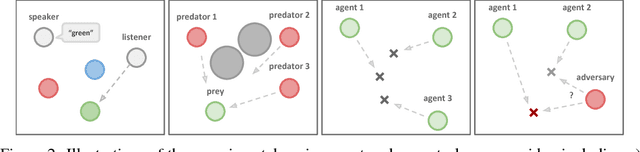
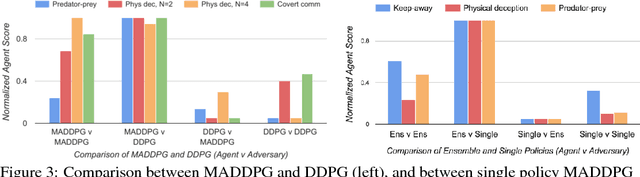
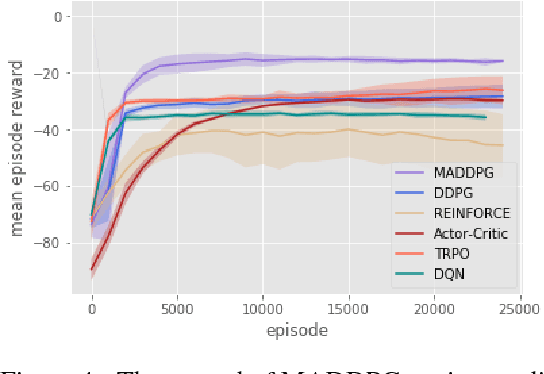
We explore deep reinforcement learning methods for multi-agent domains. We begin by analyzing the difficulty of traditional algorithms in the multi-agent case: Q-learning is challenged by an inherent non-stationarity of the environment, while policy gradient suffers from a variance that increases as the number of agents grows. We then present an adaptation of actor-critic methods that considers action policies of other agents and is able to successfully learn policies that require complex multi-agent coordination. Additionally, we introduce a training regimen utilizing an ensemble of policies for each agent that leads to more robust multi-agent policies. We show the strength of our approach compared to existing methods in cooperative as well as competitive scenarios, where agent populations are able to discover various physical and informational coordination strategies.
Learnings Options End-to-End for Continuous Action Tasks
Nov 30, 2017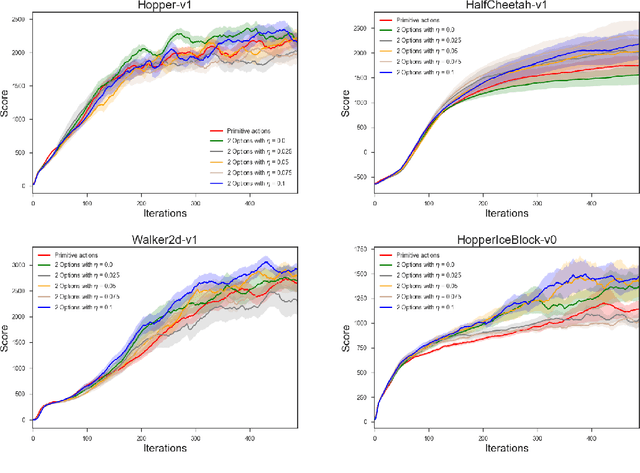
We present new results on learning temporally extended actions for continuoustasks, using the options framework (Suttonet al.[1999b], Precup [2000]). In orderto achieve this goal we work with the option-critic architecture (Baconet al.[2017])using a deliberation cost and train it with proximal policy optimization (Schulmanet al.[2017]) instead of vanilla policy gradient. Results on Mujoco domains arepromising, but lead to interesting questions aboutwhena given option should beused, an issue directly connected to the use of initiation sets.
When Waiting is not an Option : Learning Options with a Deliberation Cost
Sep 14, 2017
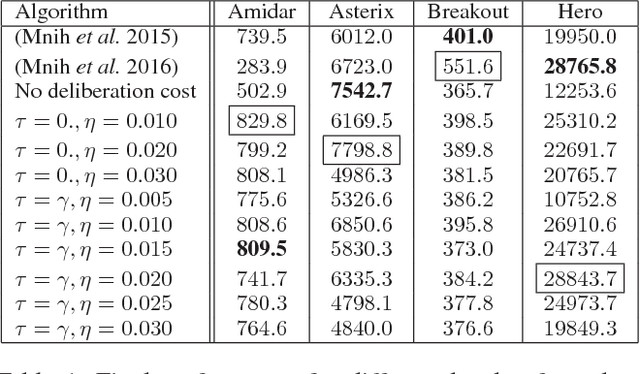
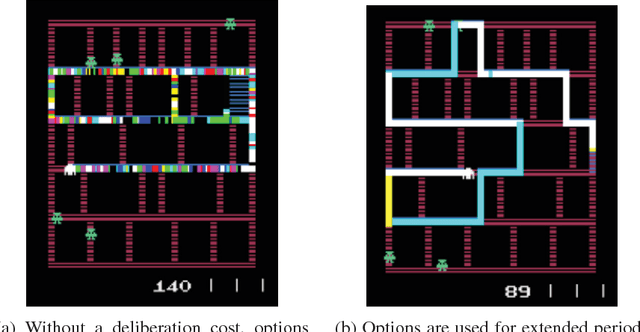
Recent work has shown that temporally extended actions (options) can be learned fully end-to-end as opposed to being specified in advance. While the problem of "how" to learn options is increasingly well understood, the question of "what" good options should be has remained elusive. We formulate our answer to what "good" options should be in the bounded rationality framework (Simon, 1957) through the notion of deliberation cost. We then derive practical gradient-based learning algorithms to implement this objective. Our results in the Arcade Learning Environment (ALE) show increased performance and interpretability.
Investigating Recurrence and Eligibility Traces in Deep Q-Networks
Apr 18, 2017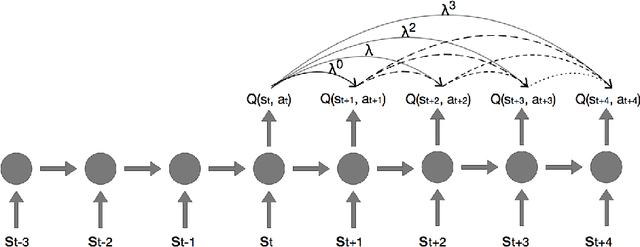
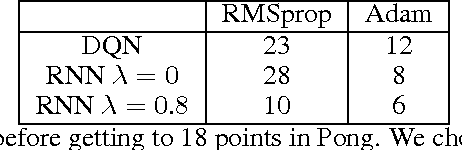
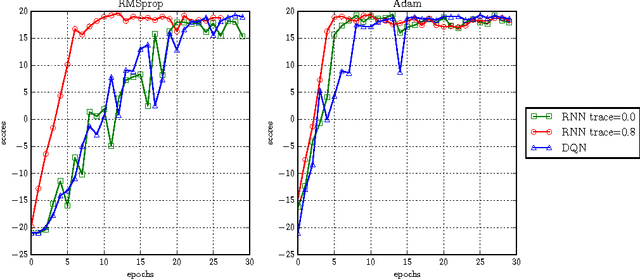

Eligibility traces in reinforcement learning are used as a bias-variance trade-off and can often speed up training time by propagating knowledge back over time-steps in a single update. We investigate the use of eligibility traces in combination with recurrent networks in the Atari domain. We illustrate the benefits of both recurrent nets and eligibility traces in some Atari games, and highlight also the importance of the optimization used in the training.