Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearnings Options End-to-End for Continuous Action Tasks
Paper and Code
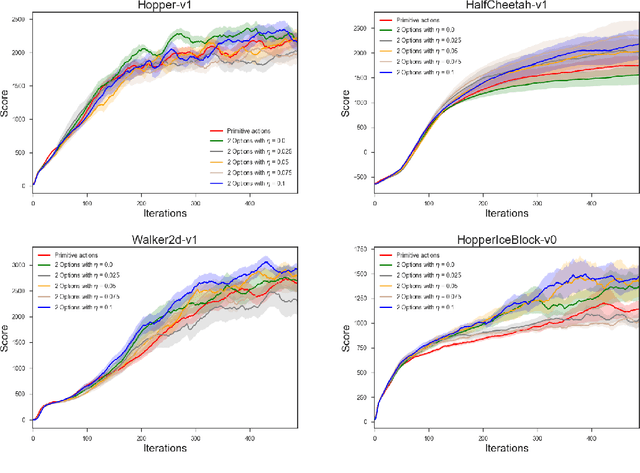
We present new results on learning temporally extended actions for continuoustasks, using the options framework (Suttonet al.[1999b], Precup [2000]). In orderto achieve this goal we work with the option-critic architecture (Baconet al.[2017])using a deliberation cost and train it with proximal policy optimization (Schulmanet al.[2017]) instead of vanilla policy gradient. Results on Mujoco domains arepromising, but lead to interesting questions aboutwhena given option should beused, an issue directly connected to the use of initiation sets.
View paper on